
1 概述
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
总结一下,Tidb是个高度兼容MySQL的分布式数据库,并拥有以下几个特性:
- 高度兼容 MySQL:掌握MySQL,就可以零基础使用TIDB
- 水平弹性扩展:自适应扩展,基于Raft协议
- 分布式事务:悲观锁、乐观锁、因果一致性
- 真正金融级高可用:基于Raft协议
- 一站式 HTAP 解决方案:单个数据库同时支持 OLTP 和 OLAP,进行实时智能处理的能力
其中TiDB的核心特性是:水平扩展、高可用。
本文主要从TiDB的各类组件为起点,了解它的基础架构,并重点分析它在存储架构方面的设计,探究其如何组织数据,Table中的每行记录是如何在内存和磁盘中进行存储的。
2 组件
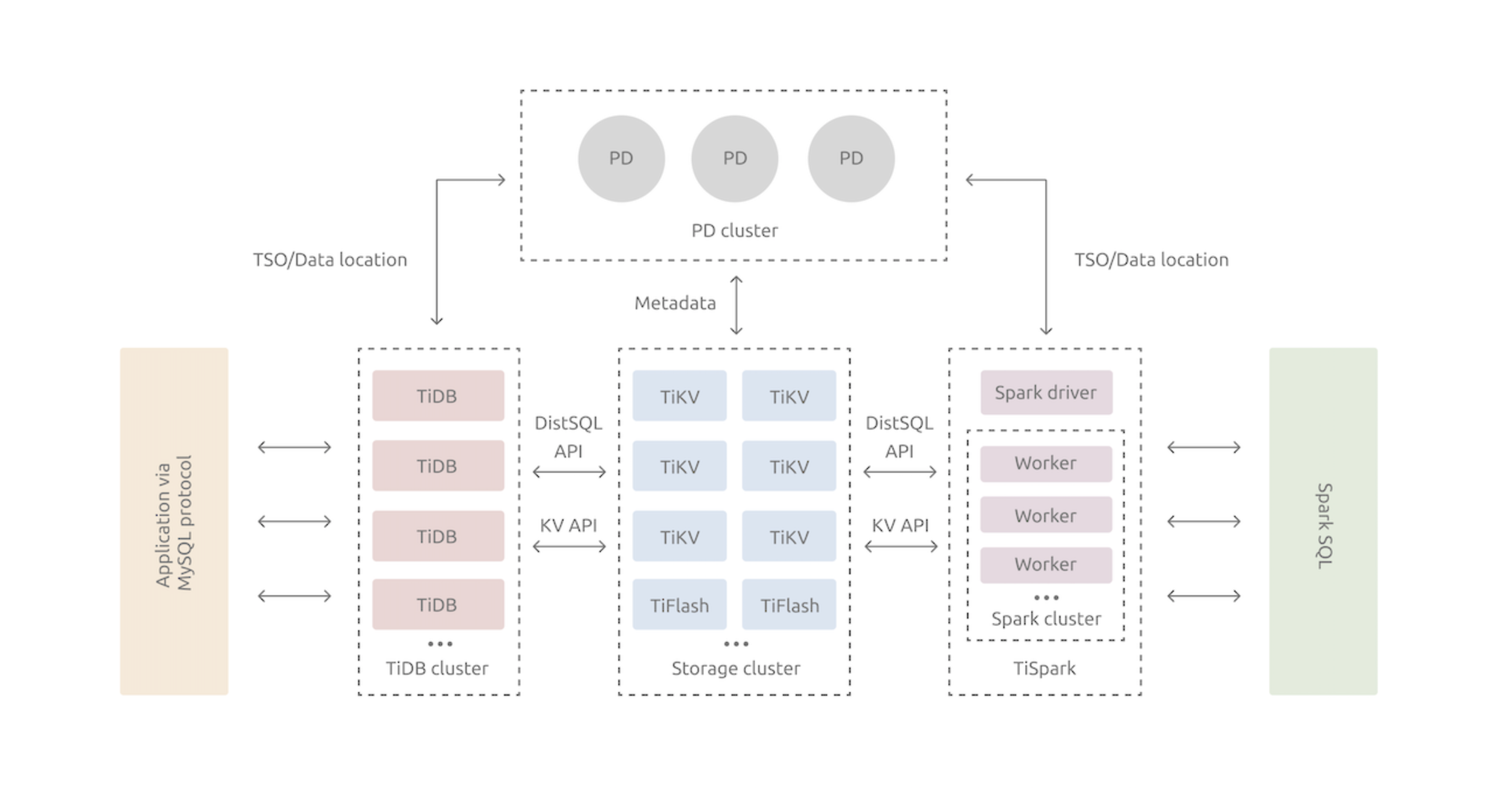
先看一张Tidb的架构图,里面包含 TiDB、Storage(TiKV、TiFlash)、TiSpark、PD。其中的TiDB、TiKV、PD是核心组件;TIFlash、TiSpark是为了解决复杂OLAP的组件。
TiDB是Mysql语法的交互入口,TiSpark是sparkSAL的交互入口。
 )
)2.1 TiDB Server
SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。
TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
2.2 PD (Placement Driver) Server
整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
2.3 存储节点
2.3.1 TiKV Server
负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。
存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。
TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。
TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
2.3.2 TiFlash
TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。假如使用场景为海量数据,且需要进行统计分析,可以在数据表基础上创建TiFlash存储结构的映射表,以提高查询速度。
以上组件互相配合,支撑着Tidb完成海量数据存储、同时兼顾高可用、事务、优秀的读写性能。
3 存储架构
3.1 TiKV的模型
前文所描述的Tidb架构中,其作为存储节点的有两个服务,TiKV和TiFlash。其中TiFlash为列式存储的形式实现的,可以参考ClickHouse的架构思路,二者具有相似性。本章节主要讨论TiKV的实现。
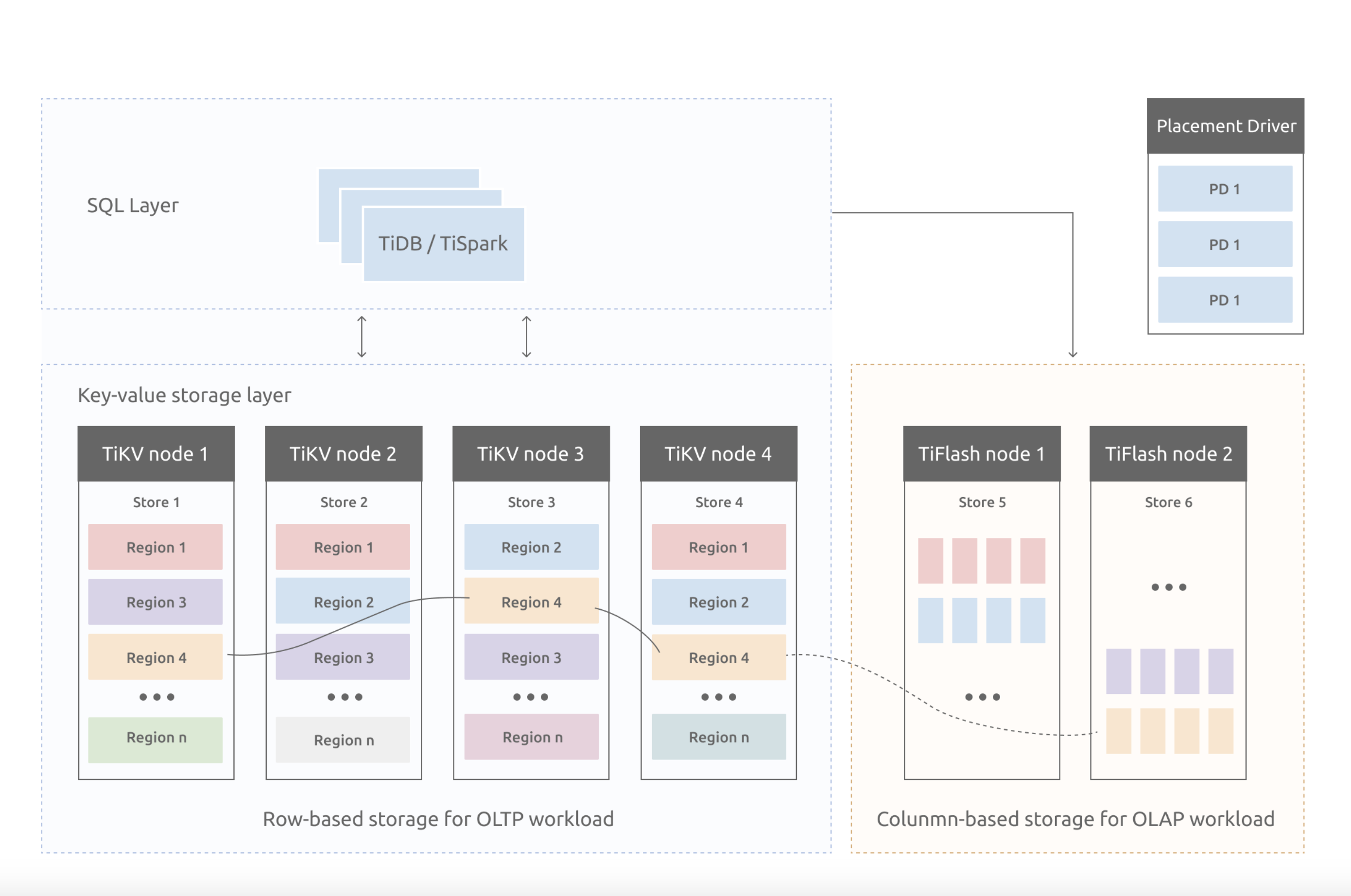 )
)在上图中,TiKV node所描述的就是OLTP场景下Tidb的存储组件,而TiFlash则是应对的LOAP场景。TiKV选择的是Key-Value模型,作为数据的存储模型,并提供有序遍历方法进行读取。
TiKV数据存储有两个关键点:
- 是一个巨大的Map(可以参考HashMap),也就是存储的是Key-Value Pairs(键值对)。
- 这个Map中的Key-Value pair按照Key的二进制顺序有序,也就是可以Seek到某一个Key的位置,然后不断地调用Next方法,以递增的顺序获取比这个Key大的Key-Value。
需要注意的是,这里描述的TiKV的KV存储模型,与SQL中的Table无关,不要有任何代入。
在图中TiKV node内部,有store、Region的概念,这是高可用的解决方案,TiDB采用了Raft算法实现,这里细分析。
3.2 TiKV的行存储结构
在使用Tidb时,依然以传统“表”的概念进行读写,在关系型数据库中,一个表可能有很多列。而Tidb是以Key-Value形式构造数据的,因此需要考虑,将一行记录中,各列数据映射成一个key-value键值对。
首先,在OLTP场景,有大量针对单行或者多行的增、删、改、查操作,要求数据库具备快速读取一行数据的能力。因此,对应的 Key 最好有一个唯一 ID(显示或隐式的 ID),以方便快速定位。
其次,很多 OLAP 型查询需要进行全表扫描。如果能够将一个表中所有行的 Key 编码到一个区间内,就可以通过范围查询高效完成全表扫描的任务。
3.2.1 表数据的KV映射
Tidb中表数据与Key-Value的映射关系,设计如下:
- 为了保证同一个表的数据会放在一起,方便查找,TiDB会为每个表分配一个表ID,用TableID表示,整数、全局唯一。
- TiDB会为每行数据分配一个行ID,用RowID表示,整数、表内唯一。如果表有主键,则行ID等于主键。
基于以上规则,生成的Key-Value键值对为:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1,col2,col3,col4]其中 tablePrefix 和 recordPrefixSep 都是特定的字符串常量,用于在 Key 空间内区分其他数据。
这个例子中,是完全基于RowID形成的Key,可以类比MySQL的聚集索引。
3.2.2 索引数据的KV映射
对于普通索引,在MySQL中是有非聚集索引概念的,尤其innodb中,通过B+Tree形式,子节点记录主键信息,再通过回表方式得到结果数据。
在Tidb中是支持创建索引的,那么索引信息如何存储? 它同时支持主键和二级索引(包括唯一索引和非唯一索引),且与表数据映射方式类似。
设计如下:
- Tidb为表中每个索引,分配了一个索引ID,用IndexID表示。
- 对于主键和唯一索引,需要根据键值快速定位到RowID,这个会存储到value中
因此生成的key-value键值对为:
Key:tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue
Value: RowID由于设计的key中存在indexedColumnsValue,也就是查询的字段值,因此可以直接命中或模糊检索到。再通过value中的RowID,去表数据映射中,检索到RowID对应的行记录。
对于普通索引,一个键值可能对应多行,需要根据键值范围查询对应的RowID。
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
Value: null根据字段值,可以检索到具有相关性的key的列表,在根据key中包含的RowID,再拿到行记录。
3.2.3 映射中的常量字符串
上述所有编码规则中的 tablePrefix、recordPrefixSep 和 indexPrefixSep 都是字符串常量,用于在 Key 空间内区分其他数据,定义如下:
tablePrefix = []byte{'t'}
recordPrefixSep = []byte{'r'}
indexPrefixSep = []byte{'i'}在上述映射关系中,一个表内所有的行都有相同的 Key 前缀,一个索引的所有数据也都有相同的前缀。这样具有相同的前缀的数据,在 TiKV 的 Key 空间内,是排列在一起的。
因此,只需要设计出稳定的后缀,则可以保证表数据或索引数据,有序的存储在TiKV中。而有序带来的价值就是能够高效的读取。
3.2.4 举例
假设数据库的一张表,如下:
CREATE TABLE User (
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
KEY idxAge (Age)
);表中有3行记录:
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
4, "TiFlash", "OLAP", 30这张表中有一个主键ID、一个普通索引idxAge,对应的是列Age.
假设该表的TableID=10,则其表数据的存储如下:
t10_r1 --> ["TiDB", "SQL Layer", 10]
t10_r2 --> ["TiKV", "KV Engine", 20]
t10_r3 --> ["PD", "Manager", 30]
t10_r4 --> ["TiFlash", "OLAP", 30]其普通索引idxAge的存储如下:
t10_i1_10_1 --> null
t10_i1_20_2 --> null
t10_i1_30_3 --> null
t10_i1_30_4 --> null3.3 SQL与KV映射
TiDB 的 SQL 层,即 TiDB Server,负责将 SQL 翻译成 Key-Value 操作,将其转发给共用的分布式 Key-Value 存储层 TiKV,然后组装 TiKV 返回的结果,最终将查询结果返回给客户端。
举例,“select count(*) from user where name=’tidb’;”这样的SQL语句,在Tidb中进行检索,流程如下:
- 根据表名、所有的RowID,结合表数据的Key编码规则,构造出一个[StartKey,endKey)的左闭右开区间。
- 根据[StartKey,endKey)这个区间内的值,到TiKV中读取数据
- 得到每一行记录后,过滤出name=’tidb’的数据
- 将结果进行统计,计算出count(*)的结果,进行返回。
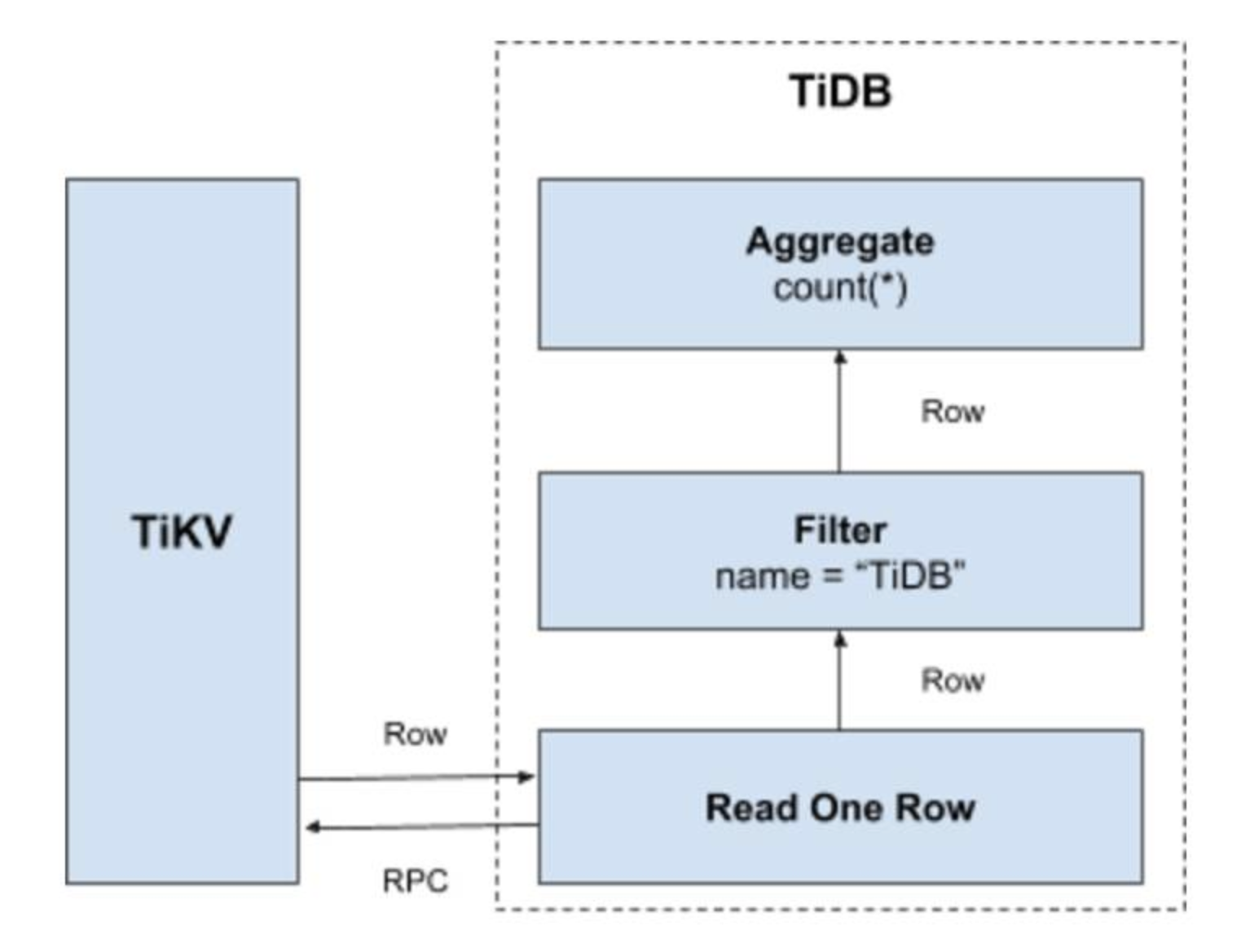 )
)在分布式环境下,为了提高检索效率,实际运行过程中,上述流程是会将name=’tidb’和count( *)下推到集群的每个节点中,减少无异议的网络传输,每个节点最终将count( *)的结果,再由SQL层将结果累加求和。
4 RockDB 持久化
4.1 概述
前文所描述的Key-Value Pairs只是存储模型,是存在于内存中的,任何持久化的存储引擎,数据终归要保存在磁盘上。TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。
这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。这里可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
4.2 RocksDB
TiKV Node的内部被划分成多个Region,这些Region作为数据切片,是数据一致性的基础,而TiKV的持久化单元则是Region,也就是每个Region都会被存储在RocksDB实例中。
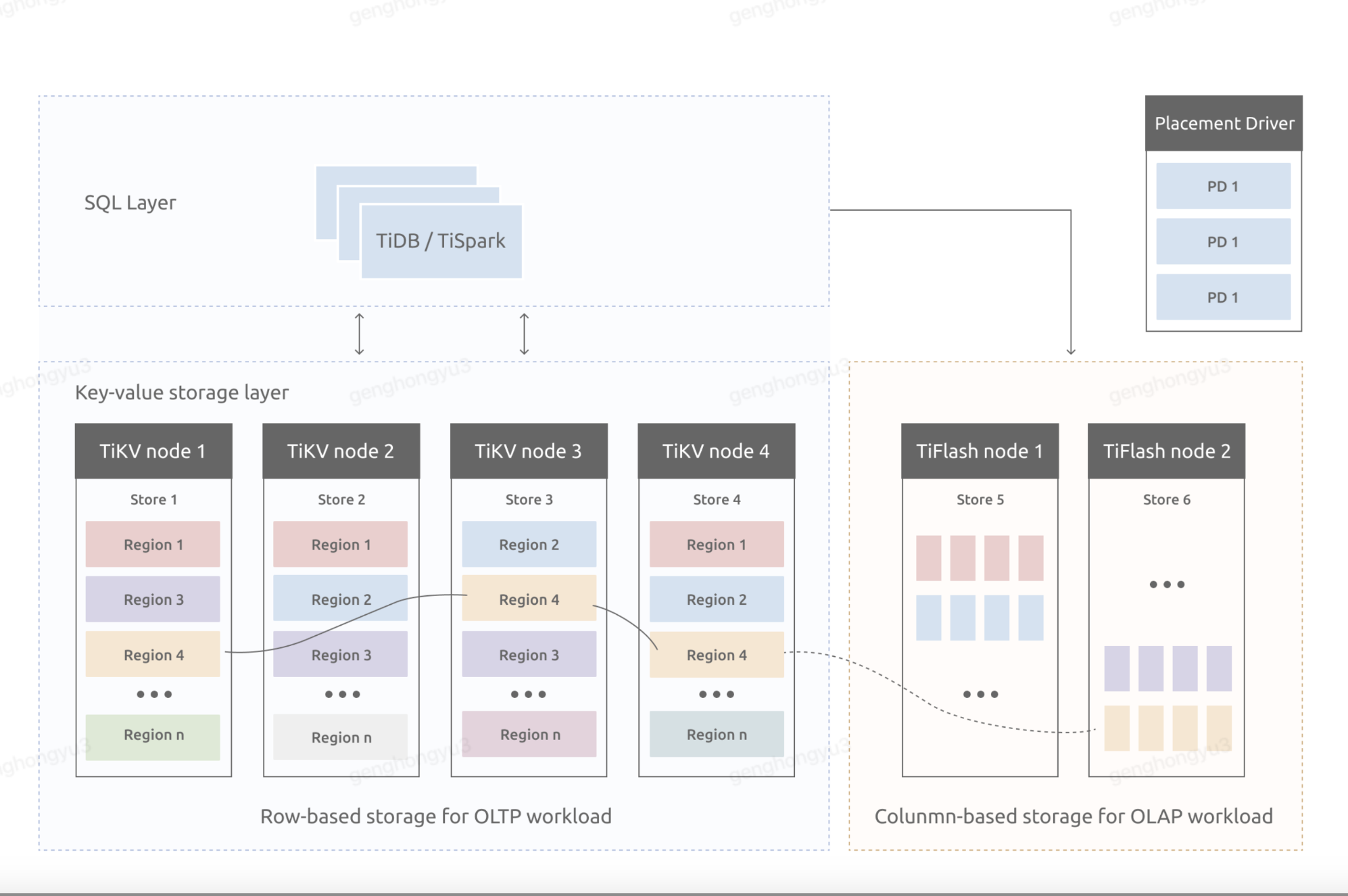 )
)以Region为单元,是基于顺序I/O的性能考虑的。而TiKV是如何有效的组织Region内的数据,保证分片均匀、有序,这里面用到了LSM-Tree,如果有HBase经验一定不模式。
4.2.1 LSM-Tree结构
LSM-Tree(log structured merge-tree)字面意思是“日志结构的合并树”,LSM-Tree的结构是横跨磁盘和内存的。它将存储介质根据功能,划分磁盘的WAL(write ahead log)、内存的MemTable、磁盘的SST文件;其中SST文件又分为多层,每一层数据达到阈值后,会挑选一部分SST合并到下一层,每一层的数据是上一层的10倍,因此90%的数据会存储在最后一层。
 )
)WAL:是预写Log的实现,当进行写操作时,会将数据通过WAL方式备份到磁盘中,防止内存断电而丢失。
Memory-Table:是在内存中的数据结构,用以保存最近的一些更新操作;memory-table可以使用跳跃表或者搜索树等数据结构来组织数据,以保持数据的有序性。当memory-table达到一定的数据量后,memory-table会转化成为immutable memory-table,同时会创建一个新的memory-table来处理新的数据。
Immutable Memory-Table:immutable memory-table在内存中是不可修改的数据结构,它是将memory-table转变为SSTable的一种中间状态。目的是为了在转存过程中不阻塞写操作。写操作可以由新的memory-table处理,而不用因为锁住memory-table而等待。
SST或SSTable:有序键值对集合,是LSM树组在磁盘中的数据的结构。如果SSTable比较大的时候,还可以根据键的值建立一个索引来加速SSTable的查询。SSTable会存在多个,并且按Level设计,每一层级会存在多个SSTable文件。
4.2.2 LSM-Tree执行过程
写入过程
- 首先会检查每个区域的存储是否达到阈值,未达到会直接写入;
- 如果Immutable Memory-Table存在,会等待其压缩过程。
- 如果Memory-Table已经写满,Immutable Memory-Table 不存在,则将当前Memory-Table设置为Immutable Memory-Table,生成新的Memory-Table,再触发压缩,随后进行写入。
- 写的过程会先写入WAL,成功后才会写Memory-Table,此刻写入才完成。
数据存在的位置,按顺序会依次经历WAL、Memory-Table、Immutable Memory-Table、SSTable。其中SSTable是数据最终持久化的位置。而事务性写入只需要经历WAL和Memory-Table即可完成。
查找过程
1.根据目标key,逐级依次在Memory-Table、Immutable Memory-Table、SSTable中查找
2.其中SSTable会分为几个级别,也是按Level中进行查找。
- Level-0级别,RocksDB会采用遍历的方式,所有为了查找效率,会控制Level-0的文件个数。
- 而Level-1及以上层级的SSTable,数据不会存在交叠,且由于存储有序,会采用二分查找提高效率。
RocksDB为了提高查找效率,每个Memory-Table和SSTable都会有相应的Bloom Filter来加快判断Key是否可能在其中,以减少查找次数。
删除和更新过程
当有删除操作时,并不需要像B+树一样,在磁盘中的找到相应的数据后再删除。
- 首先会在通过查找流程,在Memory-Table、Immuatble Memory-Table中进行查找。
- 如果找到则对结果标记为“删除”。
- 否则会在结尾追加一个节点,并标记为“删除”
在真正删除前,未来的查询操作,都会先找到这个被标记为“删除”的记录。 - 之后会在某一时刻,通过压缩过程真正删除它。
更新操作和删除操作类似,都是只操作内存区域的结构,写入一个标志,随后真正的更新操作被延迟在合并时一并完成。由于操作是发生在内存中,其读写性能也能保障。
4.3 RockDB 的优缺点
优点
- 将数据拆分为几百M大小的块,然后顺序写入
- 首次写入的目的地是内存,采用WAL设计思路,加上顺序写,提高写入的能力,时间复杂度近似常数
- 支持事务,但L0层的数据,key的区间有重叠,支持较差
缺点
- 读写放大严重
- 应对突发流量的时候,削峰能力不足
- 压缩率有限
- 索引效率较低
- 压缩过程比较消耗系统资源,同时对读写影响较大
5 总结
以上针对TiDB的整体架构进行建单介绍,并着重描述了TiKV是如何组织数据、如何存储数据。将其Key-Value的设计思路,与MySQL的索引结构进行对比,识别相似与差异。TiDB依赖RockDB实现了持久化,其中的Lsm-Tree,作为B+Tree的改进结构,其关注中心是“如何在频繁的数据改动下保持系统读取速度的稳定性”,以顺序写磁盘作为目标,假设频繁地对数据进行整理,力求数据的顺序性,带来读性能的稳定,同时也带来了一定程度的读写放大问题。
作者:京东物流 耿宏宇
来源:京东云开发者社区 自猿其说Tech







