
前言
本文仅代表作者的个人观点;
本文的内容仅限于技术探讨,不能直接作为指导生产环境的素材;
本文素材是红帽公司产品技术和手册;
本文分为系列文章,将会有多篇,初步预计将会有26篇。
一、Openshift的高可用
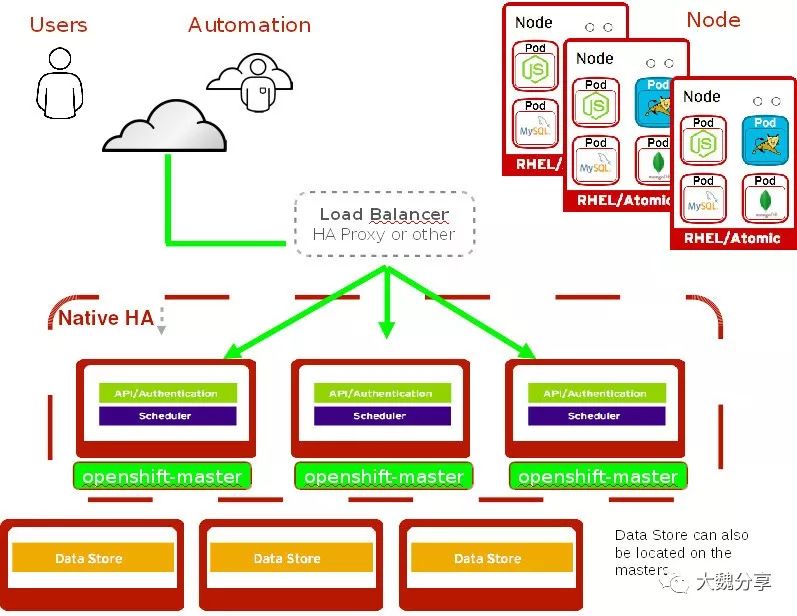
一个典型的OCP高可用架构是:master至少应为三个,且为奇数个(上面有etcd);

基础架构节点不少于两个,上面运行日志、监控、router、INTEGRATED REGISTRY。
Openshift的计算节点不少于2个,以保证当一个节点出现故障的时候,不影响应用。
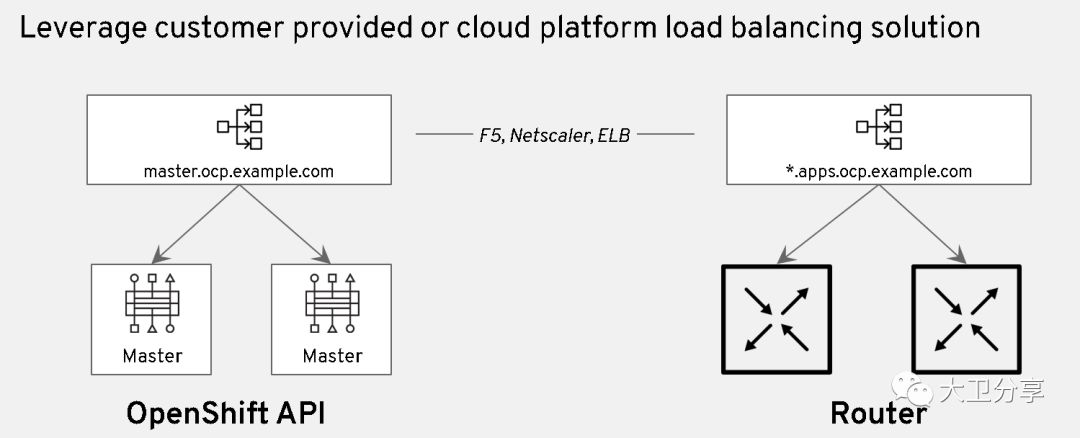
在Openshift中,两个重要的流量入口组件是Master和Router。

在生产环境中,为了保证高可用,Master和Router都会配置多个。这就引入了一个问题:多个Master和Router对外如何提供统一的域名。
这时候,需要使用客户数据中心/公有云的负载均衡。当然,在数据中心内,我们也可以通过Haproxy搭建软负载,这和使用F5的设备无本质区别。
在考虑流量入口的负载均衡的同时,我们还需要考虑DNS的问题。当然,商业的F5通常有DNS的功能。
针对Master,多个Master会有一个VIP/域名。VIP和多个Master都需要被DNS解析。在负载均衡器上,将Master VIP的域名(如master.ocp.example.com)和多个Master的域名对应起来,同时设置负载均衡策略,如roundrobin等。
针对Router, DNS需要将应用对外的域名,解析成router所在的openshift节点的域名。如果有多个router,就需要个多个router配置VIP和它的域名。VIP被解析成多个router所在的Openshift节点的域名(同时配置负载均衡策略)。而DNS上进行配置,对应用对泛域名解析,将其解析成router的VIP。
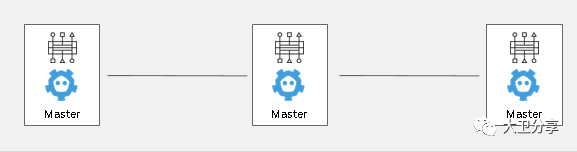
在Openshift中,etcd做服务发现,其K-V数据库存放Openshift的信息。
为了保证etcd的高可用,在生产环境中,etcd应配置成奇数个(2n+1),并且每个etcd成员之间的网络延迟小于5ms。
在Openshift中,建议将etcd与Master节点部署到一起。也就是三个master上,每个master上一个etcd。
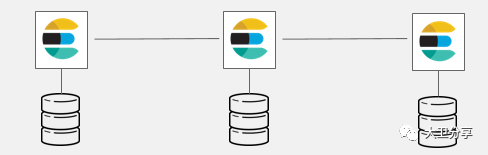
目前Openshift的日志使用EFK,具体概念不展开讲,请参照其他文档。
在EFK中,Elasticsearch需要高可用,和etcd一样,需要2n+1个节点,以保证高可用并规避脑裂。
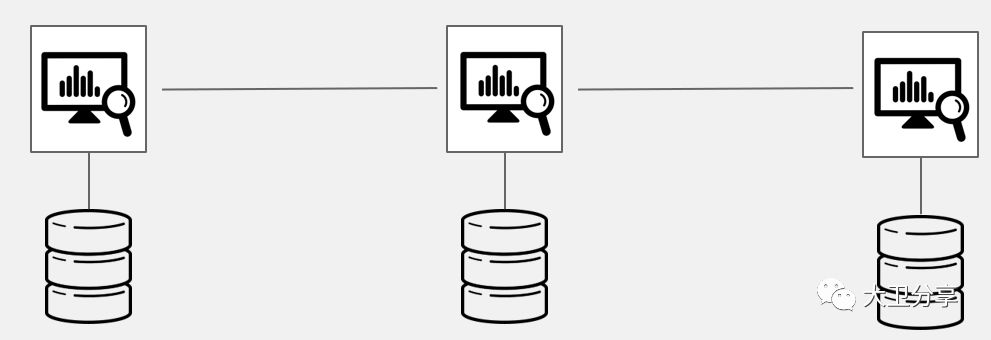
在Openshift的监控数据中,Cassandra分布式数据库存放监控信息,因此需要做高可用。在多个Cassandra之间,做存储的复制。
在Openshift中,集成镜像仓库通常用于存放dev成功后的镜像,以完成整个CI/CD过程。他与数据中心外部镜像仓库是分开的,作用也不一样。
在生产环境中,INTEGRATED REGISTRY通常会被配置成多个。
同样,需要给多个REGISTRY配置VIP和域名。多个REGISTRY的VIP通过负载均衡器的roundrbin指向多个registery。
在本实验中,Openshift的架构如下:
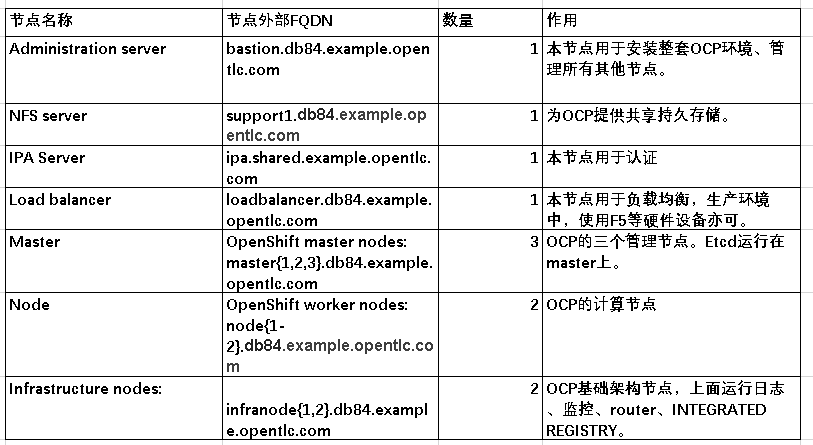
二、Master的高可用配置
在单Master配置环境中,如果master出现故障,如下功能受到影响:

在单Master配置环境中,如果master出现故障,如下功能不受影响:
应用仍在运行
路由器仍然有效
应用程序仍然相互通信
后端服务仍然可以与群集内外的任何其他服务进行通信
Master的高可用配置有两种方式:
1.单Master多etcd
2.多Master多etcd
1.单Master多etcd
如下图,master节点有一个,etcd集群部署在外部,由三个节点组成集群:
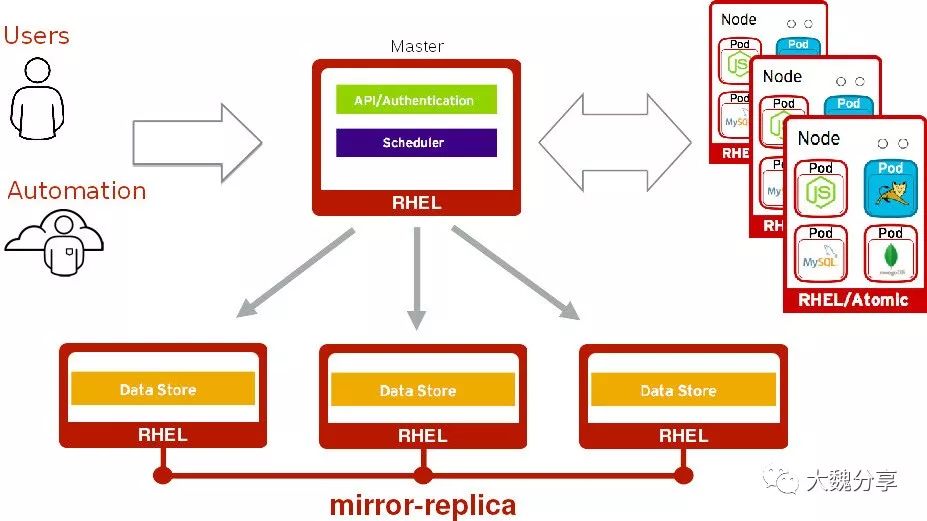
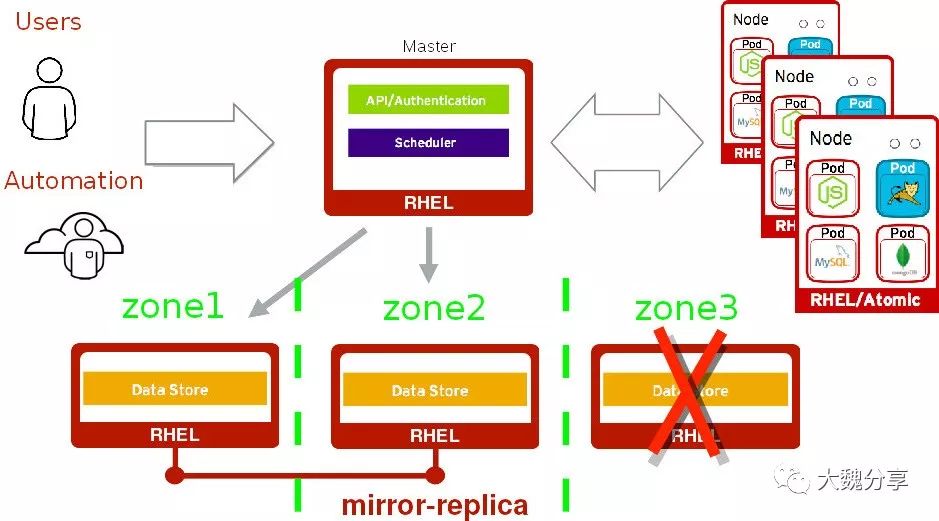
在单Master多etcd情况下,当一个etcd节点失败时:
Master故障转移到另一个etcd节点
Master仍在运作; 不会对最终用户造成干扰,也不会造成数据丢失
每个节点都是另一个节点的副本、
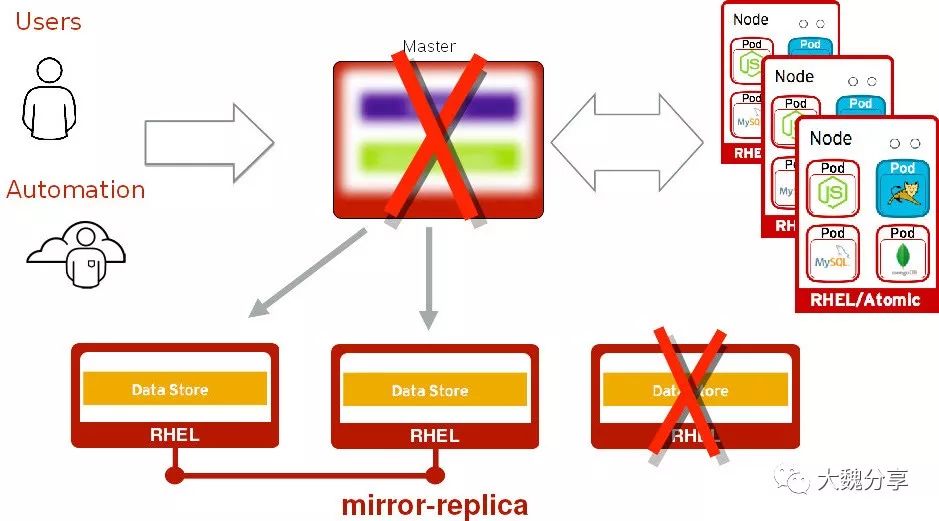
在单Master多etcd情况下,当Master节点和它正在访问的etcd同事出现问题时,所带来的影响和不做高可用没有区别。
与不做高可用先比,优点有:
将Master节点修复完毕后,恢复与etcd的通讯即可
无需恢复数据存储数据
2.多Master多etcd
多Master多etcd利用OpenShift native HA,这种方案可以与任何负载平衡解决方案结合使用。

在这种模式下,如果在ansible inventory文件的[lb]部分中定义了主机,Ansible自动安装和配置HAProxy作为负载均衡。
如果在ansible inventory文件的[lb]部分中没有定义了主机,那么需要用户预先配置了自己的负载均衡,以便多个Master API节点之间实现负载均衡(默认端口8443)
三、Master的高可用配置实验展现
首先确认各个节点与部署节点通讯正常:
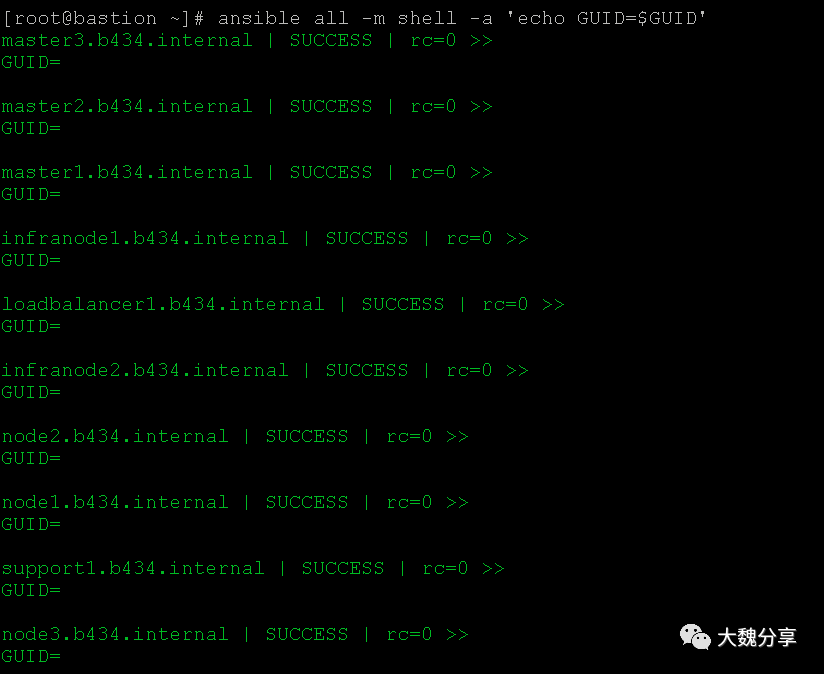
查看ansible inventory文件:
[root@bastion ~]# cat /etc/ansible/hosts
[OSEv3:vars]
openshift_deployment_type=openshift-enterprise
#指定master高可用模式是native,目前版本的OCP只支持Native
openshift_master_cluster_method=native
#设置master vip的对内域名
openshift_master_cluster_hostname=loadbalancer1.b434.internal
#设置master vip的对外域名
openshift_master_cluster_public_hostname=loadbalancer.b434.example.opentlc.com
#penshift_master_default_subdomain=apps.test.example.com
openshift_master_default_subdomain=apps.b434.example.opentlc.com
containerized=false
#设置node selector,label的标签是env
openshift_hosted_infra_selector='env=infra'
openshift_hosted_node_selector='env=app'
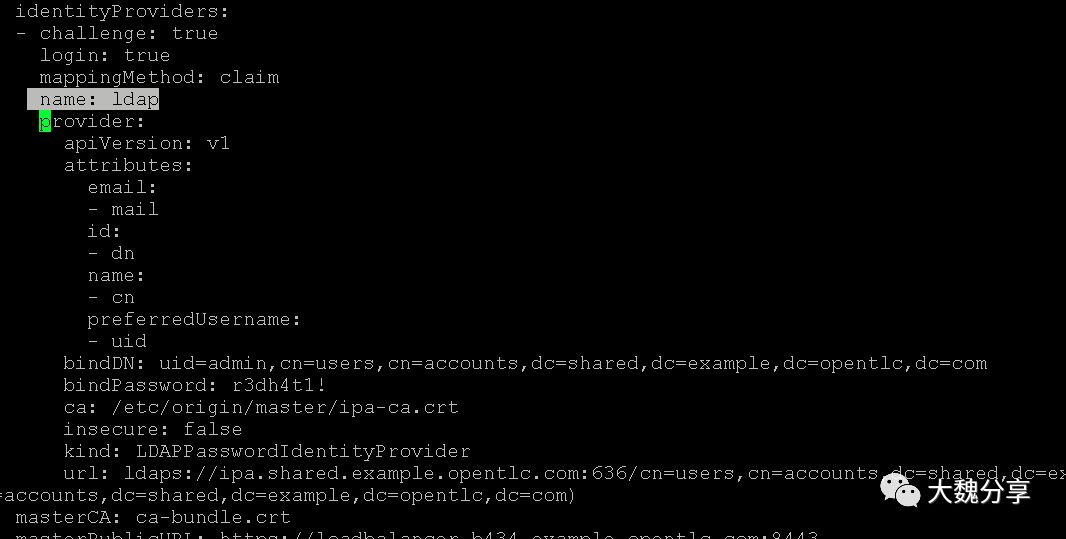
#设置LDAP方式认证
openshift_master_identity_providers=[{'name': 'ldap', 'challenge': 'true', 'login': 'true', 'kind': 'LDAPPasswordIdentityProvider','attributes': {'id': ['dn'], 'email': ['mail'], 'name': ['cn'], 'preferredUsername': ['uid']}, 'bindDN': 'uid=admin,cn=users,cn=accounts,dc=shared,dc=example,dc=opentlc,dc=com', 'bindPassword': 'r3dh4t1!', 'ca': '/etc/origin/master/ipa-ca.crt','insecure': 'false', 'url': 'ldaps://ipa.shared.example.opentlc.com:636/cn=users,cn=accounts,dc=shared,dc=example,dc=opentlc,dc=com?uid?sub?(memberOf=cn=ocp-users,cn=groups,cn=accounts,dc=shared,dc=example,dc=opentlc,dc=com)'}]
openshift_master_ldap_ca_file=/root/ipa-ca.crt
###########################################################################
### Ansible Vars
###########################################################################
timeout=60
ansible_become=yes
ansible_ssh_user=ec2-user
# disable memory check, as we are not a production environment
openshift_disable_check="memory_availability"
# Set this line to enable NFS
openshift_enable_unsupported_configurations=True
###########################################################################
### OpenShift Hosts
###########################################################################
[OSEv3:children]
lb
masters
etcd
nodes
nfs
#glusterfs
[lb]
loadbalancer1.b434.internal
[masters]
master1.b434.internal
master2.b434.internal
master3.b434.internal
[etcd]
master1.b434.internal
master2.b434.internal
master3.b434.internal
[nodes]
## These are the masters
master1.b434.internal openshift_hostname=master1.b434.internal openshift_node_labels="{'env': 'master', 'cluster': 'b434'}"
master2.b434.internal openshift_hostname=master2.b434.internal openshift_node_labels="{'env': 'master', 'cluster': 'b434'}"
master3.b434.internal openshift_hostname=master3.b434.internal openshift_node_labels="{'env': 'master', 'cluster': 'b434'}"
## These are infranodes
infranode1.b434.internal openshift_hostname=infranode1.b434.internal openshift_node_labels="{'env':'infra', 'cluster': 'b434'}"
infranode2.b434.internal openshift_hostname=infranode2.b434.internal openshift_node_labels="{'env':'infra', 'cluster': 'b434'}"
## These are regular nodes
node1.b434.internal openshift_hostname=node1.b434.internal openshift_node_labels="{'env':'app', 'cluster': 'b434'}"
node2.b434.internal openshift_hostname=node2.b434.internal openshift_node_labels="{'env':'app', 'cluster': 'b434'}"
node3.b434.internal openshift_hostname=node3.b434.internal openshift_node_labels="{'env':'app', 'cluster': 'b434'}"
[nfs]
support1.b434.internal openshift_hostname=support1.b434.internal
查看部署节点上的repo:
运行playbook检查脚本:
ansible-playbook -f 20 /usr/share/ansible/openshift-ansible/playbooks/prerequisites.yml,确保没有错误:
运行playbook,安装OCP:
ansible-playbook -f 20 /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml
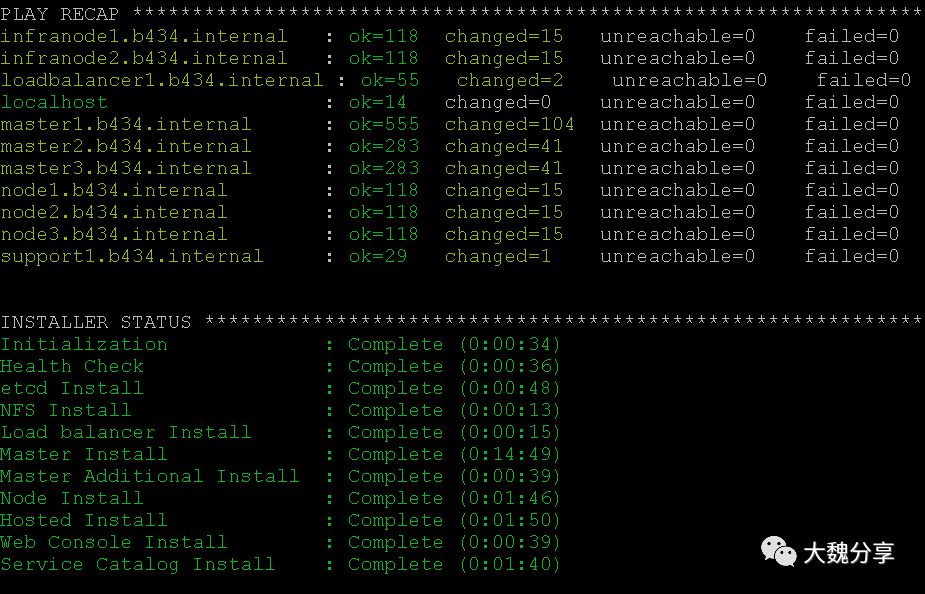
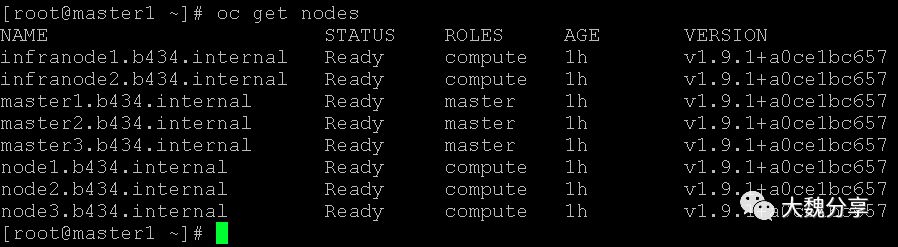
查看版本:

通过浏览器访问loadbalancer public IP;
ssh到master上,查看认证的provider,是ldap:
四、进行冒烟测试
oc new-project smoke-test
oc new-app nodejs-mongo-persistent
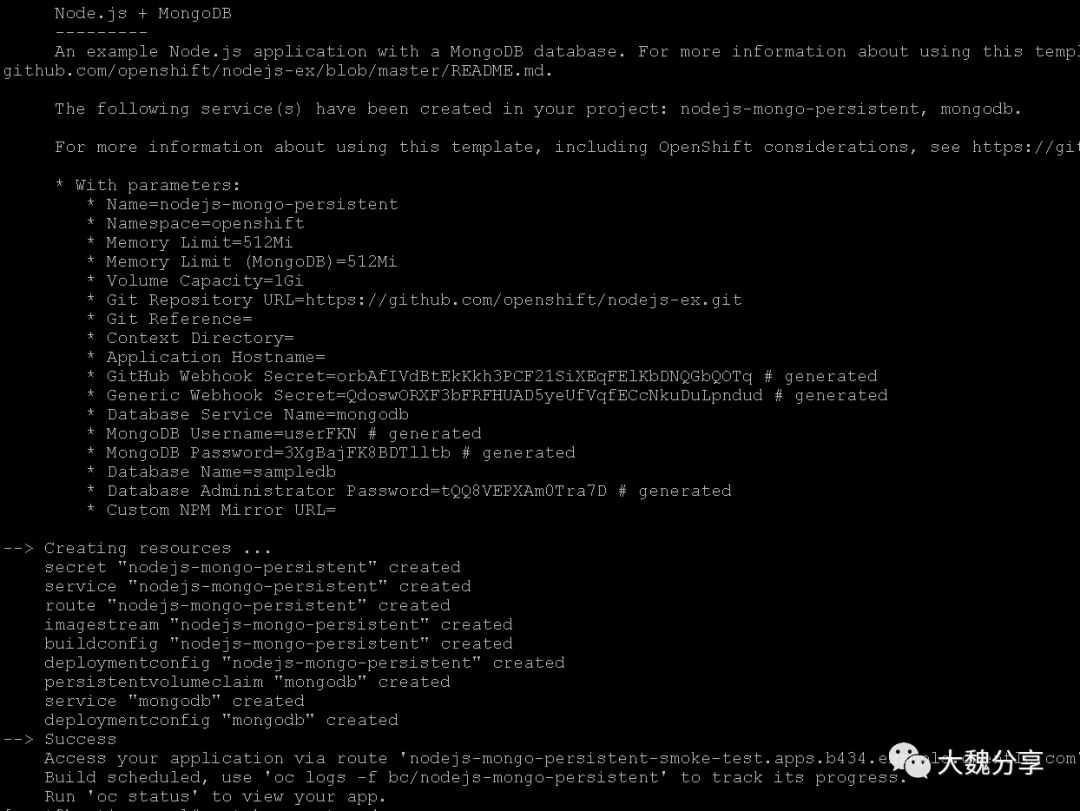
查看pod状态: watch oc get pod


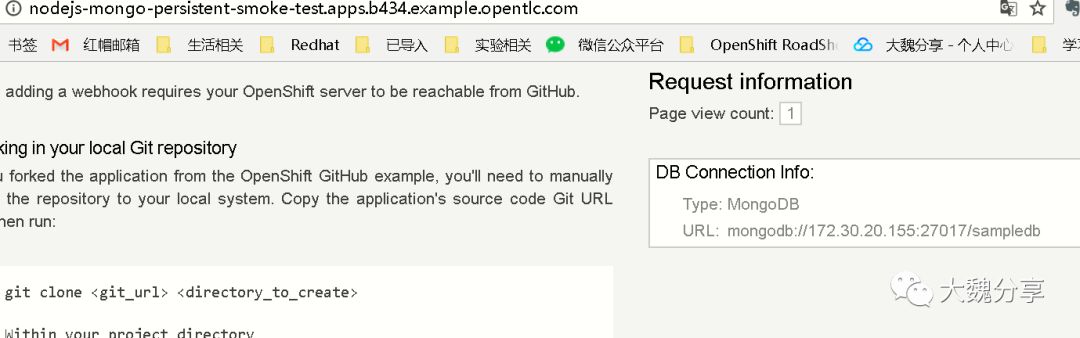
查看路由:

通过浏览器访问应用:

魏新宇
"大魏分享"运营者、红帽资深解决方案架构师
专注开源云计算、容器及自动化运维在金融行业的推广
拥有MBA、ITIL V3、Cobit5、C-STAR、TOGAF9.1(鉴定级)等管理认证。
拥有红帽RHCE/RHCA、VMware VCP-DCV、VCP-DT、VCP-Network、VCP-Cloud、AIX、HPUX等技术认证。
本文分享自微信公众号 - 大魏分享(david-share)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











