
本文分享自天翼云开发者社区《ceph数据重构原理》,作者:x****n
在分布式存储系统Ceph中,硬盘故障是一种常见问题。为了保证数据安全,当发生硬盘故障后,分布式存储系统会依据算法对故障硬盘上的数据进行数据重构及转储。和一般分布式系统一样的是,Ceph同样使用多副本机制来保证数据的高可靠性(注:EC在实现层面可以理解为副本机制的一种),给定一份数据,Ceph在后台自动存储多份副本(一般使用3个副本),从而使得在硬盘损毁、服务器故障、机柜停电等故障情况下,不会出现数据丢失,甚至数据仍能保持在线。不过在故障发生后,Ceph需要及时做故障恢复,将丢失的数据副本补全,以维系持续的数据高可靠性。
一.PG和PGLog Ceph中对象数据的维护由PG(Placement Group)负责,PG作为Ceph中最小的数据管理单元,直接管理对象数据,每个OSD都会管理一定数量的PG。客户端对于对象数据的IO请求,会根据对象ID的Hash值均衡分布在各个PG中。PG中维护了一份PGLog,用来记录该PG的数据变化,这些记录会被持久化记录到后端存储中。PGLog中记录了每次操作的数据和PG的版本,每次数据变更操作都会使PG的版本自增,PGLog中默认保存3000条记录,PG会定期触发Trim操作清理多余的PGLog。通常情况下,在同一个PG的不同副本中的PGLog应该是一致的,故障发生后,不同副本的PGLog可能会处于不一致的状态。
二.OSD的故障种类 故障A:一个正常的OSD因为所在的设备发生异常,导致OSD不能正常工作,OSD被标记为down,某个OSD被设置为Down状态只是简单触发其承载的PG通过Peering进行Primary转换(如果需要),以尽快恢复对外业务(此时PG工作在降级状态),后续OSD在设定的时间内,它又可以正常的工作,这时会添加会集群中;
故障B:当某个OSD处于Down状态足够长时间(例如超过600s),才有理由认为对应的OSD已经无法完全恢复,此时出于数据安全性考虑,Monitor会将其进一步设置为Out。
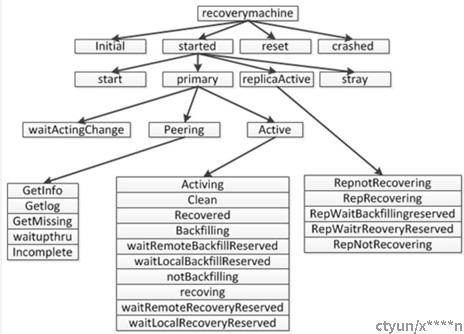
三.OSD的故障处理 故障A:OSD又重新回到PG当中去,这时需要判断一下,如果OSD能够进行增量恢复则进行增量恢复,否则进行全量恢复。(增量恢复:是指恢复OSD出现异常的期间,PG内发生变化的object。全量恢复:是指将PG内的全部object进行恢复)。需要全量恢复的操作叫做backfill操作。需要增量恢复的操作叫做recovery操作。Peering完成后,PG进入Active状态,并根据PG的副本状态将自己标记为Degraded/Undersized状态,在Degraded状态下,PGLog存储的日志数量默认会扩展到10000条记录,提供更多的数据记录便于副本节点上线后的数据恢复。进入Active状态后,PG可用并开始接受数据IO的请求,并根据Peering的信息决定是否进行Recovery和Backfill操作。Primary PG将根据对象的缺失列表进行具体对象的数据拷贝,对于Replica PG缺失的数据Primary 会通过Push操作推送缺失数据,对于Primary PG缺失的数据会通过Pull操作从副本获取缺失数据。在恢复操作过程中,PG会传输完整4M大小的对象。对于无法依靠PGLog进行Recovery的,PG将进行Backfill操作,进行数据的全量拷贝。待各个副本的数据完全同步后,PG被标记为Clean状态,副本数据保持一致,数据恢复完成。下图为PG状态机。
故障B:这些PG会重新分配副本到其他OSD上。上面的流程的前提故障 OSD 在 PGLog 保存的最大条目数以内加入集群都会利用 PGLog 恢复,那么如果在 N 天之后或者发生了永久故障需要新盘加入集群时,PGLog 就无法起到恢复数据的作用,这时候就需要 Backfill(全量拷贝) 流程介入。Backfill 会将所有数据复制到新上线的 PG,这里的流程跟上述过程基本一致,唯一的差异就是在Primary PG 发现 PGLog 已经不足以恢复数据时,这时候同样分为两种情况:
(1)故障 OSD 拥有 Primary PG,该 PG 在对比 PGLog 后发现需要全量拷贝数据,那么毫无疑问 Primary PG 在复制期间已经无法处理请求,它会发送一个特殊请求给 Monitor 告知自己需要全量复制,需要将 Replicate PG 临时性提升为 Primary,等到自己完成了复制过程才会重新接管 Primary 角色
(2)故障 OSD 拥有 Replicate PG,该 PG 的 Primary 角色会发起 backfill 流程向该 PG 复制数据,由于故障 OSD 是 Replicate 角色,因此不影响正常 IO 的处理。
一个PG中包含的object数量是不限制的,这时会将PG中所有的object进行复制,可能会产生很大的数据复制,因此为了避免产生数据迁移风暴,Monitor通过 一个名为 mon_osd_down_out_subtree_limit 的配置项来限制自动数据迁移的粒度,例如设置为主机,则当某个主机上的OSD全部宕掉时,这些OSD不再会被自动标记为Out,也就无法自动进行数据迁移,从而避免数据迁移风暴。
四.扩容时的数据再均衡 当Ceph OSD添加到Ceph存储集群时,集群映射会使用新的 OSD 进行更新。因为在CRUSH算法计算PG到OSD的映时,OSD_ID是参数之一,新加入的OSD改变了计算的输入,因此会有一部分PG根据CRUSH算法的计算原则进行迁移。下图粗略的展现了数据再均衡过程,假设之前某个PG计算出来straw值(CRUSH算法结果,PG选择OSD中最大的结果进行映射)分别为:straw1,straw2,straw3,增加OSD4之后计算,只有当straw4 > max(straw1, straw2, straw3),这种情况需要将PG数据迁移到OSD4上,会有w4/(w1+w2+w3+w4)的PG移动到osd4上(w为ODS权重),随着PG数量增多,理论上OSD上的PG分布比例为w1:w2:w3:w4。






