
CAP理论被很多人拿来作为分布式系统设计的金律,然而感觉大家对CAP这三个属性的认识却存在不少误区,那么什么是CAP理论呢?CAP原本是一个猜想,2000年PODC大会的时候大牛Brewer提出的,他认为在设计一个大规模可扩放的网络服务时候会遇到三个特性:一致性(consistency)、可用性(Availability)、分区容错(partition-tolerance)都需要的情景,然而这是不可能都实现的。之后在2003年的时候,Mit的Gilbert和Lynch就正式的证明了这三个特征确实是不可以兼得的。
CAP是Consistency、Availablity和Partition-tolerance的缩写。分别是指:
1)一致性(Consistency):每次读操作都能保证返回的是最新数据。也就是说所有的节点数据一致!
2)可用性(Availablity):任何一个没有发生故障的节点,会在合理的时间内返回一个正常的结果。也就是说一个或者多个节点失效,不影响服务请求!
3)分区容忍性(Partition-torlerance):当节点间出现网络分区,照样可以提供服务。也就是说节点间的网络连接失效,仍然可以处理请求!
其实,任何一个分布式系统,需要满足这三个中的两个。CAP理论指出:CAP三者只能取其二,不可兼得。其实这一点很好理解,理由如下:
1- 首先,单机都只能保证CP。
**2- ** 有两个或以上节点时,当网络分区发生时,集群中两个节点不能相互通信(也就是说不能保证可用性A)。此时如果保证数据的一致性C,那么必然会有一个节点被标记为不可用的状态,违反了可用性A的要求,只能保证CP。
3- 反正,如果保证可用性A,即两个节点可以继续各自处理请求,那么由于网络不通不能同步数据,必然又会导致数据的不一致,只能保证AP。
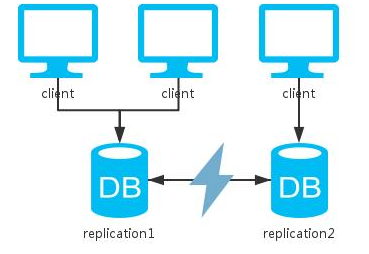
一、单实例
单机系统和显然,只能保证CP,牺牲了可用性A。单机版的MySQL,Redis,MongoDB等数据库都是这种模式。
实际中,我们需要一套可用性高的系统,即使部分机器挂掉之后仍然可以继续提供服务。
二、多副本
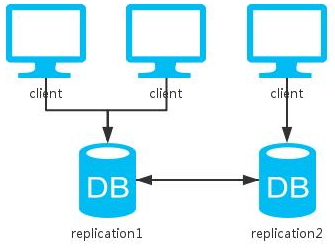
相比于单实例,这里多了一个节点去备份数据。
对于读操作来说,因为可以访问两个节点中的任意一个,所以可用性提升。
对于写操作来说,根据更新策略分为三种情况:
1)同步更新:即写操作需要等待两个节点都更新成功才返回。这样的话如果一旦发生网络分区故障,写操作便不可用,牺牲了A。
2)异步更新:即写操作直接返回,不需要等待节点更新成功,节点异步地去更新数据(FastDFS文件系统的存储节点就是用这种方式,写完一份数据之后立即返回结果,副本数据由同步线程写入其他同group的节点)。这种方式,牺牲了C来保证A,即无法保证数据是否更新成功,还有可能会由于网络故障等原因,导致数据不一致。
3)折衷:更新部分节点成功后便返回。
三、分片
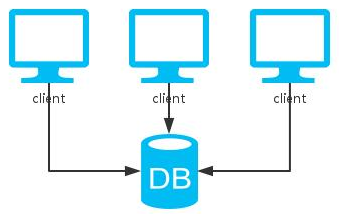
相比于单实例,这里多了一个节点去分割数据。
由于所有数据只有一份,一致性得以保证;节点间不需要通信,分区容忍性也有。
然而,当任意一个节点挂掉,丢失了一部分的数据,系统可用性得不到保证。
综上,这和单机版的方案一样,都只能保证CP。
那么,有哪些好处呢?
1)某个节点挂掉只会影响部分服务,即服务降级;
2)由于分片了数据,可以均衡负载;
3)数据量增大/减小后可以相应的扩容/缩容。
大多数的数据库服务都提供了分片的功能。如Redis的slots,Cassandra的patitions,MongoDB的shards等。
基于分片解决了数据量大的问题,可是我们还是希望我们的系统是高可用的,那么,如何牺牲一定的一致性去保证可用性呢?
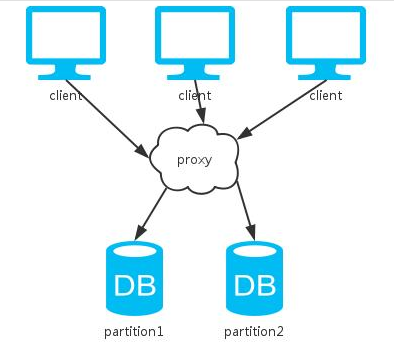
四、集群
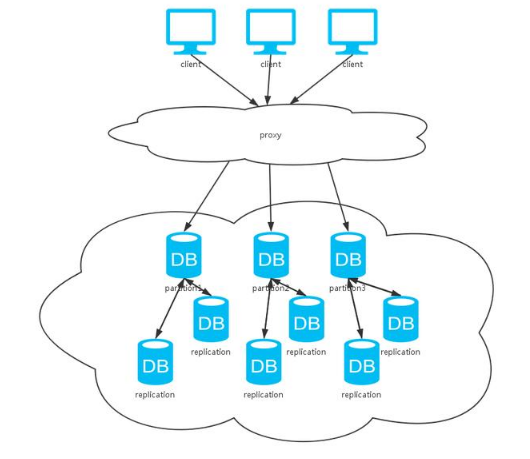
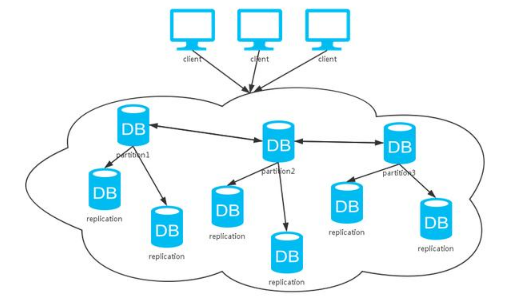
可以看到,上面这种方式综合了前两种方式。同上分析,采用不同的数据同步策略,系统CAP保证各有不同。不过,一般数据库系统都会提供可选的配置,我们根据不同的场景选择不同的特性。
其实,对于大多数的非金融类互联网公司,要求并非强一致性,而是可用性和最终一致性的保证。这也是NoSQL流行于互联网应用的一大原因,相比于强一致性系统的ACID原则,它更加倾向于BASE:
- Basically Available:基本可用性,即允许分区失败,除了问题仅服务降级;
- Soft-state:软状态,即允许异步;
- Eventual Consistency:最终一致性,允许数据最终一致性,而不是时刻一直。
五、总结
基本上,上面讨论的几种方式已经涵盖了大多数的分布式存储系统了。
其实对于大规模分布式系统来说,CAP是非常稳固的,可以扩展的地方也不多。
它很大程度上限制了大规模计算的能力,通过一些设计方式来绕过CAP管辖的区域或许是下一步大规模系统设计的关键。
可以看到,这些个方案总是需要通过牺牲一部分去换取另一部分,总没法达到100%的CAP。选择哪种方案,依据就是在特定场景下,究竟哪些特性是更加重要的了。









