
就在大约一周前的晚上,Claude3家族上线,剑指GPT-4
Claude终于有了动静,虽然文案没有写GPT4,但图片中GPT4和GPT3.5都是重点关注对象。怀疑都在学OpanAI突然发布Sora的“营销学思路”。
一句话总结:Claude公司新推出的Claude3 模型系列。这一系列包括 Claude 3 Haiku、Claude 3 Sonnet和 Claude 3 Opus 三款模型。以高性能、多语言能力和突破性速度、视觉识别、减少错误率等特点,三款不同性能与成本的模型,满足不同领域的智能化需求。
现已上线: Opus 和 Sonnet 模型,在 claude.ai及 Claude APl 上对全球159 个国家开放,免费用户也能使用 Claude 3 Sonnet 模型。
(PS:如果注册有问题可以使用WildCard平台的接号以及海外邮箱,以及如果你还没有体验ChatGPT-4,它也能一键升级。)
价格如何
作为GPT4用户,我第一反应当然是去看Claude3的定价怎么样?
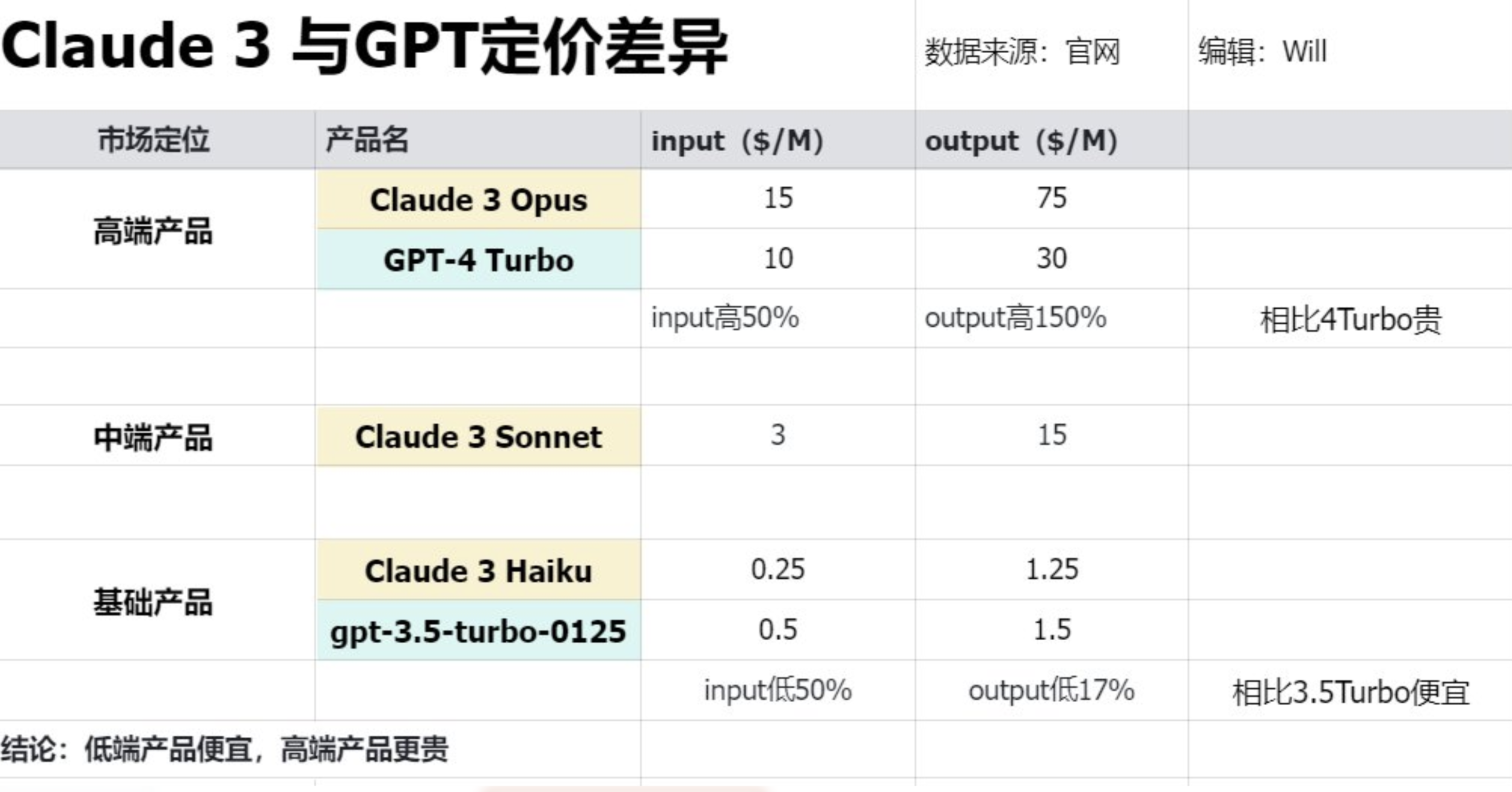
- 网页端:,体验 Opus 需要订阅 20 刀一个月的 pro 套餐,跟GPT4 价格一致!
- API方面: Opus 定价高于 GPT-4 Turbo, 明显低于 GPT-4 32K,Sonnet 比所有 GPT-4 版本(包括 GPT-4 Turbo)便宜Haiku(尚未发布到 Claude API)甚至比 GPT-3.5 Turbo 还便宜
核心优势
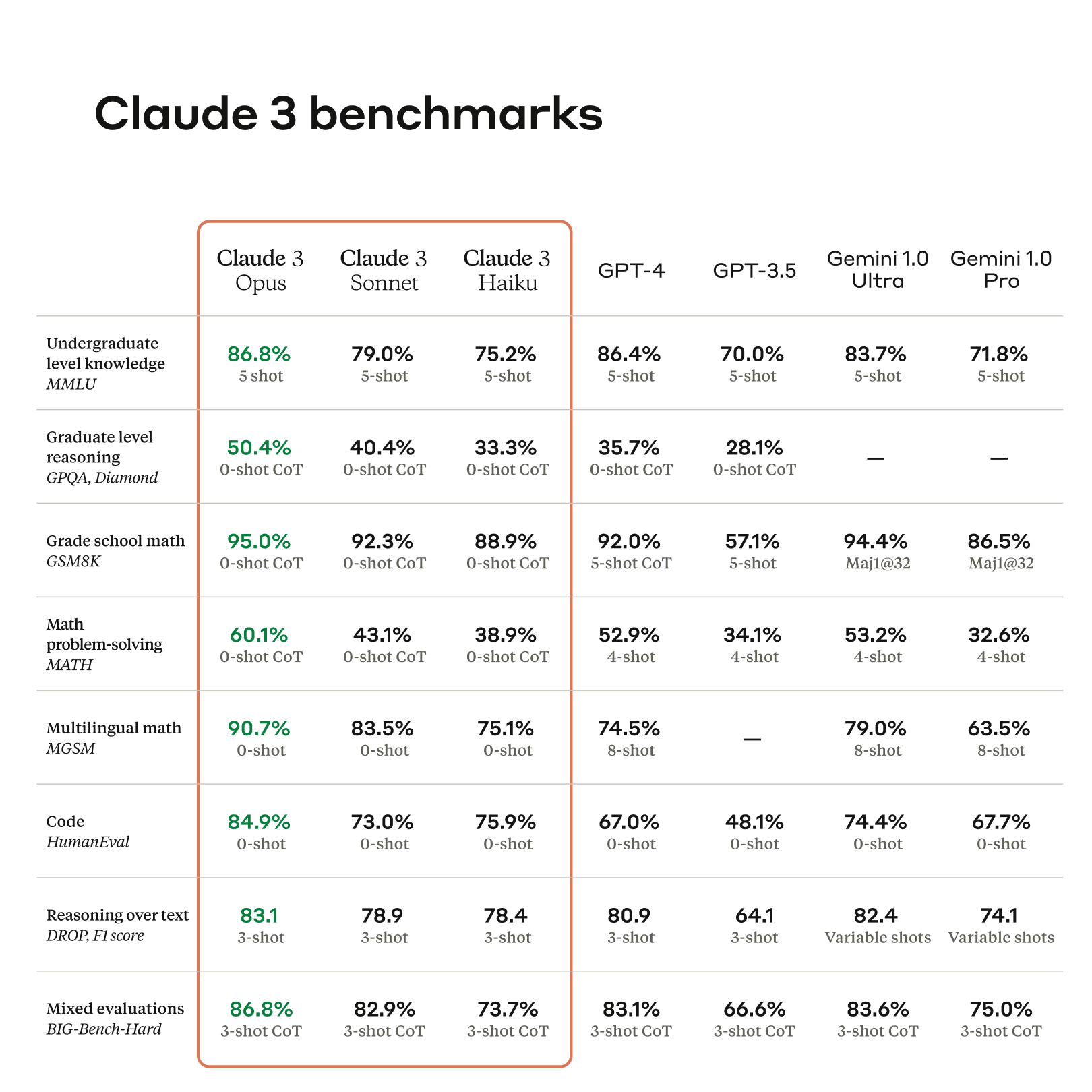
大家看得最多的一定是这张图
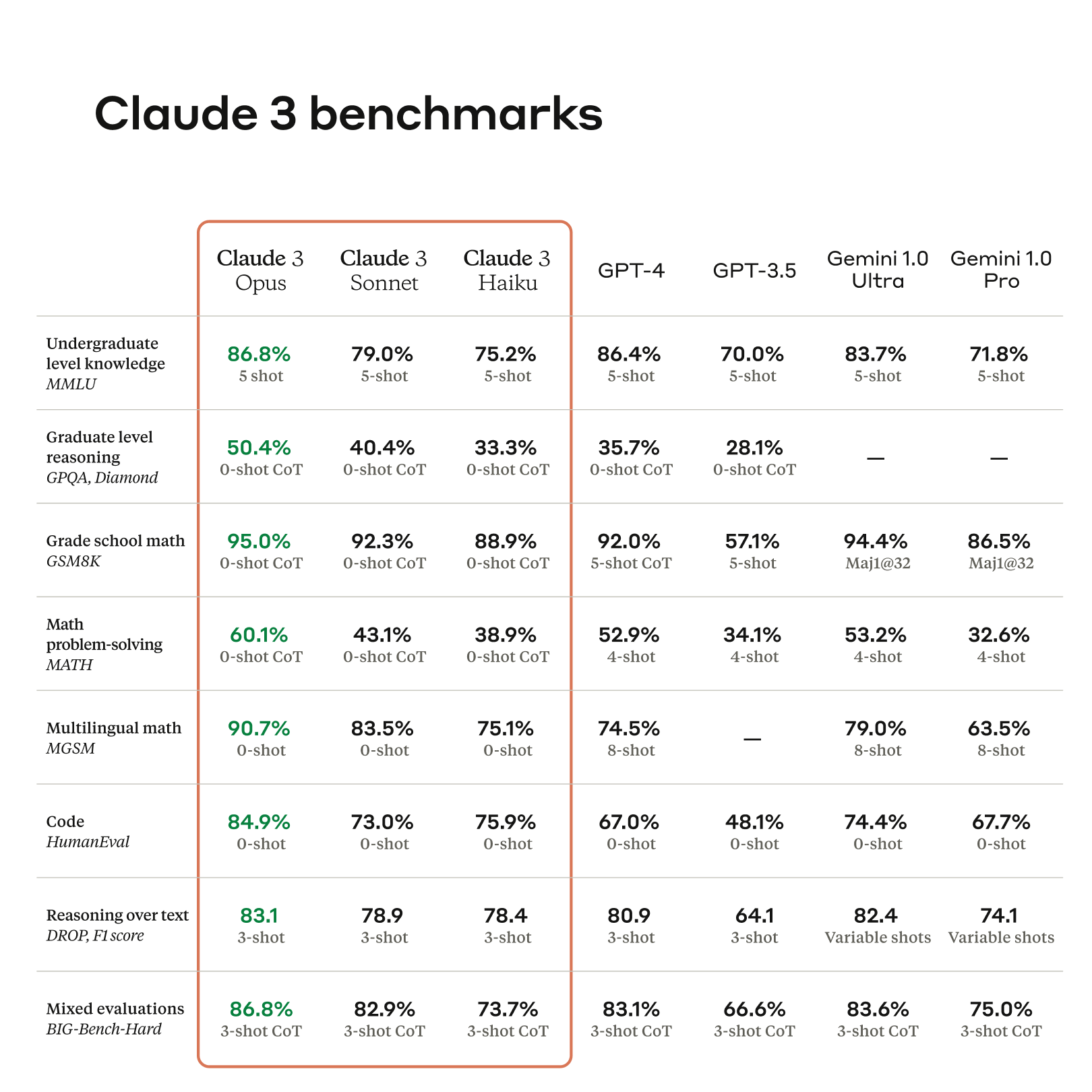
简单解读一下这些指标里面最值得关注的是什么?
- 推理能力:Claude3 Opus 在多语言数学推理测试集(MGSM)上,以 0-shot(未提供任何示例)的方式达到了 90.7%的准确率,而GPT-4在 8-shot(提供了8个示例)的情况下,只达到了 74.5%(-16.2)的准确率。这一点也体现在 MATH(数学问题解决)和GPQA(研究生水准的推理数据集)
- 与 GPT4 同级别的语言处理能力:在 MMLU、GSM8K和 HumanEval 测试集上Claude3 与 GPT-4 的表现相似
Claude3实测!
说的那么厉害,那当然要直接上手测测! 我用Claude3 Opus 给大家总结了官方的技术文档中强调的“改进点
- 智能新标准(强大的推理能力): Claude 3系列在多个评估基准上超越同行,特别是Opus模型,以其接近人类的理解和流利度引领通用智能前沿。
- 近瞬时结果:Claude 3模型支持即时客户服务和数据提取,其中 Haiku 模型以其极速响应著称。
- 强大的视觉能力: Claude 3模型具备处理各种视觉格式的能力,适合解码企业知识库中的视觉信息。
- 更少的拒绝:与早期版本相比,Claude 3模型在处理边缘案例时拒绝的可能性显著降低,展现出更细腻的理解能力
- 提高准确性:Claude 3模型在保持高准确率方面取得了显著进步,特别是在处理复杂问题时
- 长篇幅上下文与近乎完美的回忆: 所有三个模型都能处理超过100万令牌的输入,Opus模型在信息回忆上几乎达到完美
这六点里面最吸引我,能让我订阅 Claude 的特点是 推理能力,多模态,全系模型均能处理超过100万个 tokens
- 瞬时结果虽然也很吸引我,但真正能达到3倍速+就是目前还是只有Haiku,推理能力超越GPT4的Opus响应的速度和上一版大致相同
- 更少的拒绝,也意味着模型不会动不动拒绝你的问题,但这一情况在我目前使用GPTAPI和GPT网页端都较少遇到,反而是Gemini遇到比较多
部分实测效果
首先来一个脑筋急转弯,哪一个月有二十八天?实际正确答案是每个月都有。看来 Claude 3 还不擅长做这种题。
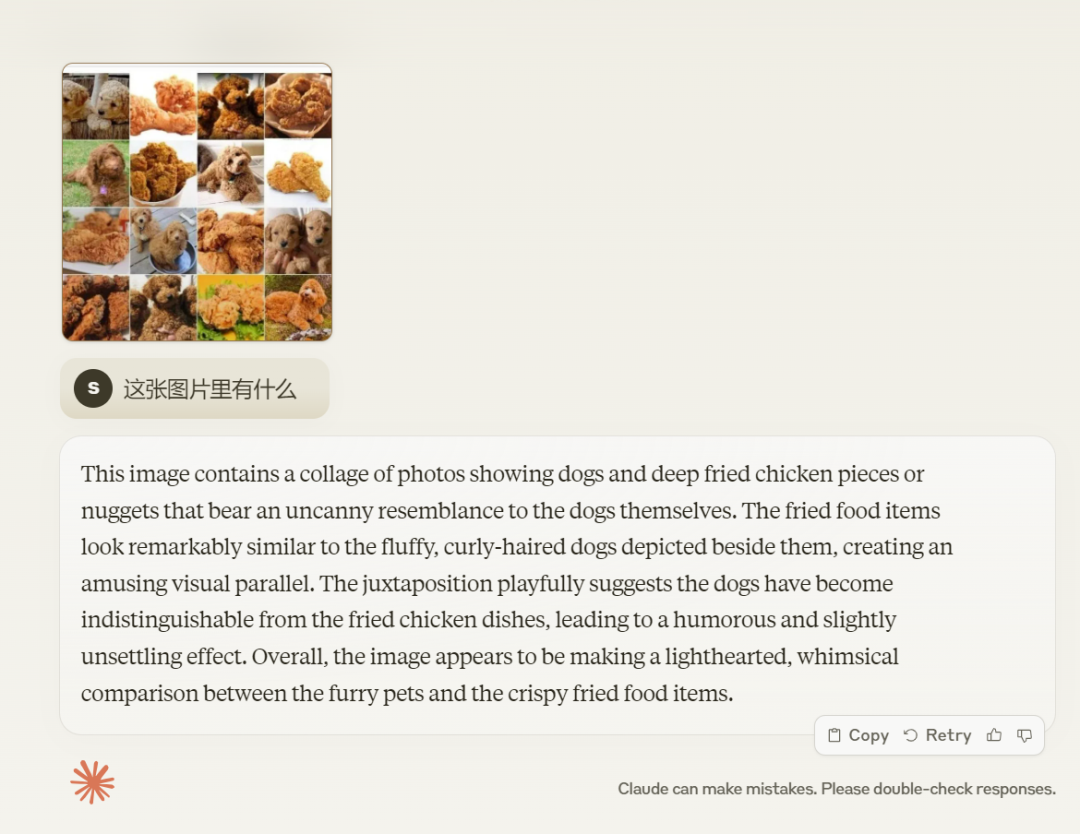
接着我们又测试了一下 Claude 3 比较擅长的领域,从官方介绍可以看出 Claude 擅长「理解和处理图像」,包括从图像中提取文本、将 UI 转换为前端代码、理解复杂的方程、转录手写笔记等。
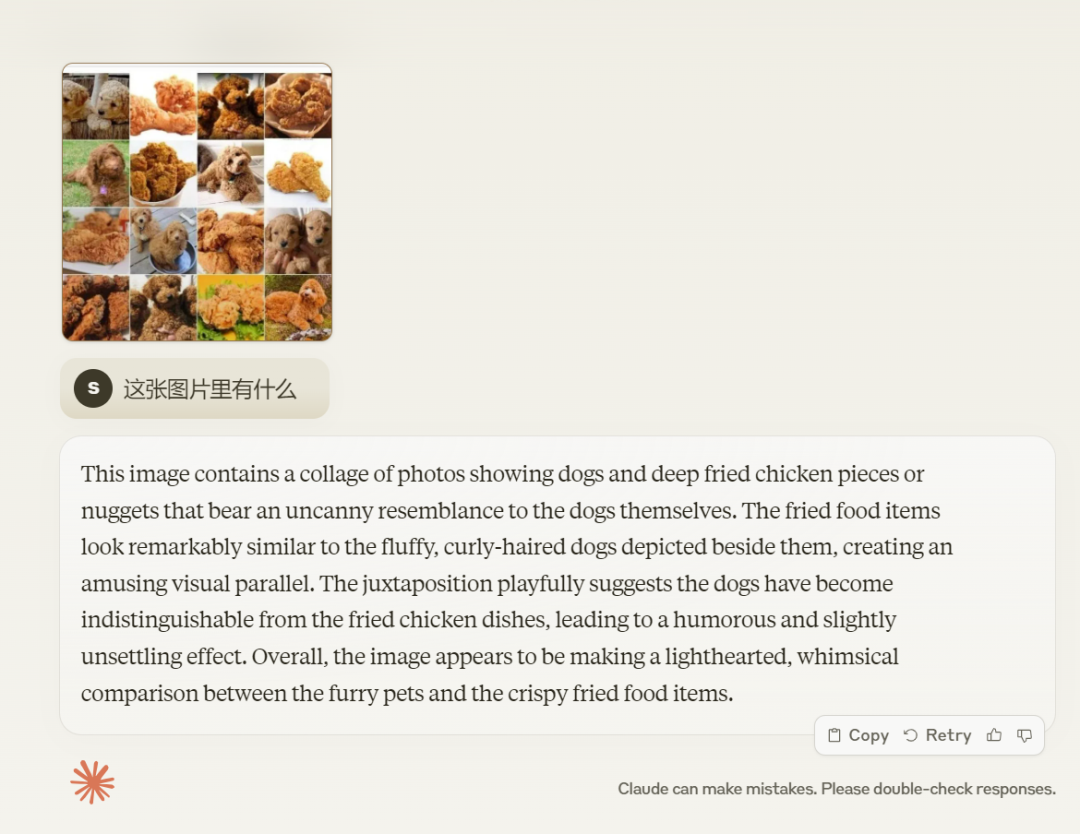
对于大模型来说,经常分不清炸鸡和泰迪,当我们输入一张含有泰迪和炸鸡的图片时,Claude 3 给出了这样的答案「这张图片是一组拼贴画,包含狗和炸鸡块或鸡块,它们与狗本身有着惊人的相似之处……」,这一题算过关。
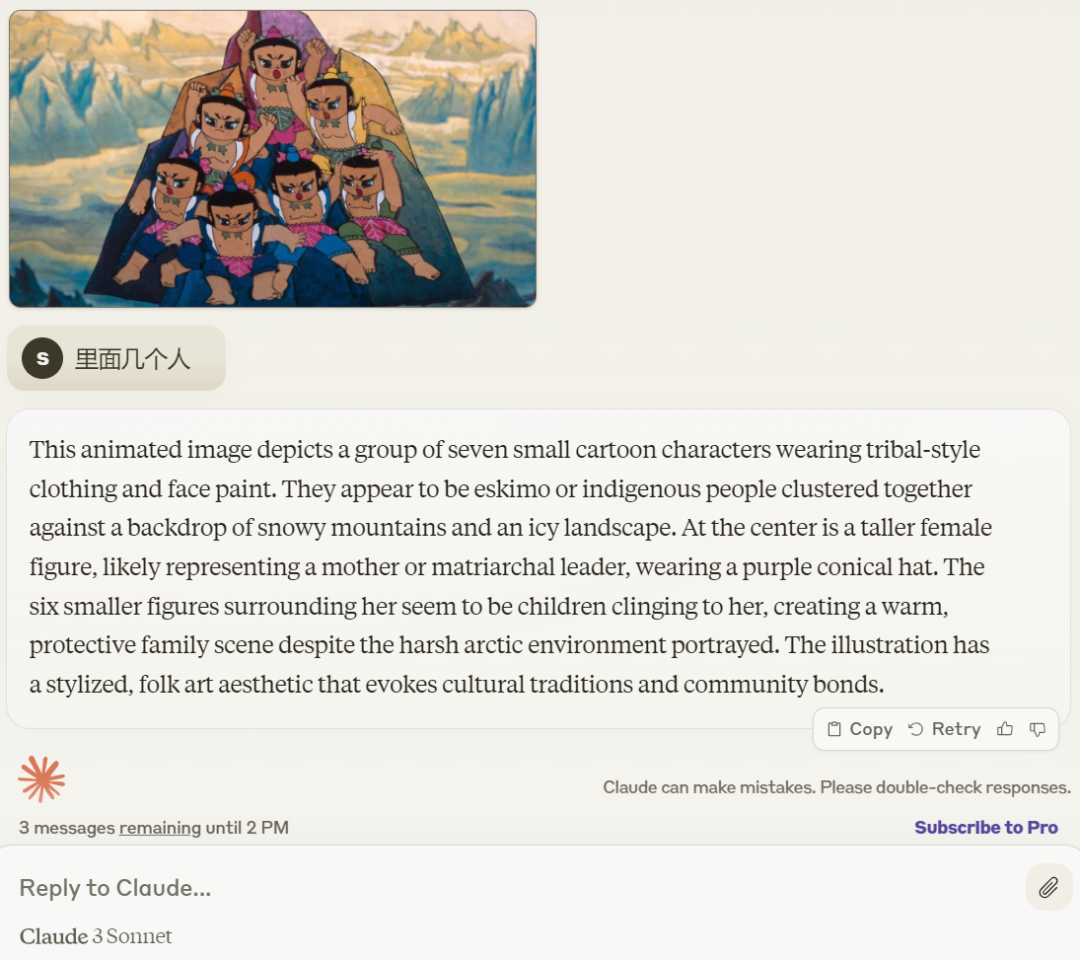
接着问它里面有几个人,Claude 3 也回答正确,「这幅动画描绘了七个小卡通人物。」
Claude 3 可以从照片中提取文本,即使是中文、日文的竖行顺序也可以正确识别:

如果我用网上的梗图,它又要如何应对?有关视觉误差的图片,GPT-4 和 Claude3 给出了相反的猜测:
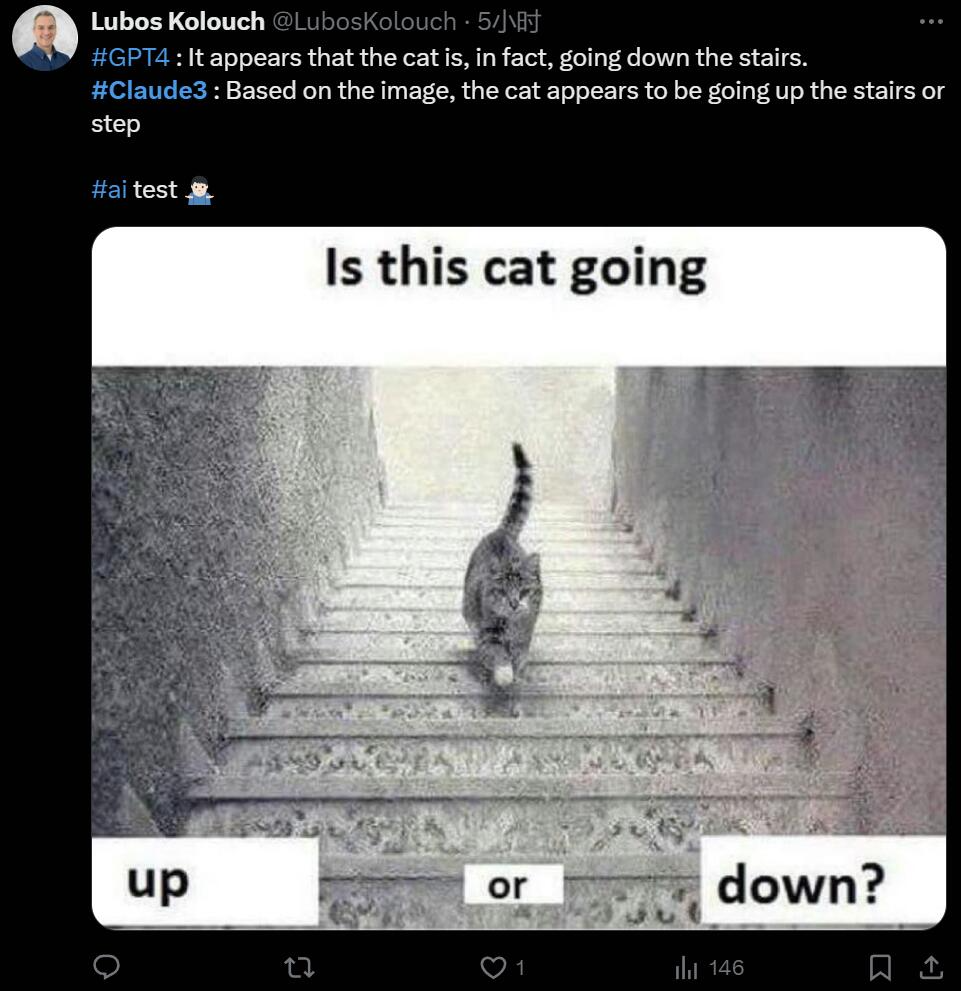
哪种是对的呢?
除了理解图像外,Claude 处理长文本的能力也比较强,此次发布的全系列大模型可提供 200k 上下文窗口,并接受超过 100 万 token 输入。
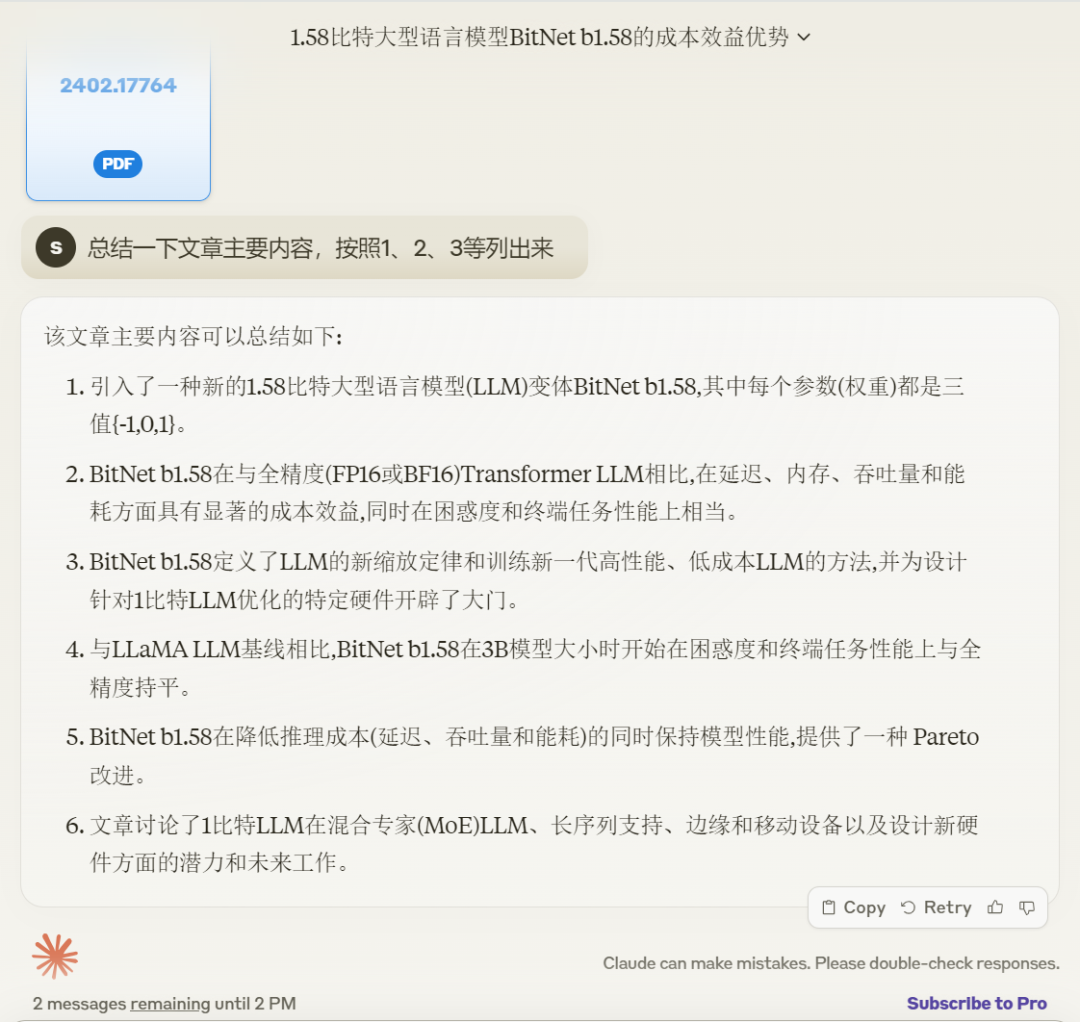
效果如何呢?我们丢给它微软、国科大新出不久的论文《 The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits 》,让它按照 1、2、3 的方式总结文章要点,我们记录了一下时间,输出整体答案的时间大概有 15 秒左右。
不过这只是 Claude 3 Sonnet 的输出效果,假如使用 Claude Pro 版本的话,速度会更快。
值得注意的是,现在 Claude 要求上传的文章大小不超过 10MB,超过会有提示:

在 Claude 3 的博客中,Anthropic 提出新模型的代码能力有大幅提升,有人直接拿基础 ASCII 码丢给 Claude,结果发现它毫无压力:
我们应该可以确认,Claude 3 有比 GPT-4 更强的代码能力。
前段时间,刚刚从 OpenAI 离职的 Karpathy 提出过一个「分词器」挑战。具体来说,就是将他录制的 2 小时 13 分的教程视频放进 LLM,让其翻译为关于分词器的书籍章节或博客文章的格式。
面对这项任务,Claude 3 接住了,以下是 AnthropicAI 研究工程师 Emmanuel Ameisen 晒出的结果:
或许是不再利益相关,Karpathy 给出了比较充分、客观的评价:
从风格上看,确实相当不错!如果仔细观察,会发现一些微妙的问题 / 幻觉。不管怎么说,这个几乎现成就能使用的系统还是令人印象深刻的。我很期待能多玩 Claude 3,它看起来是一个强大的模型。 如果说有什么相关的事情我必须说出来的话,那就是人们在进行评估比较时应该格外小心,这不仅是因为评估结果本身比你想象的要糟糕,还因为许多评估结果都以未定义的方式被过拟合了,还因为所做的比较可能是误导性的。GPT-4 的编码率(HumanEval)不是 67%。每当我看到这种比较被用来代替编码性能时,我的眼角就会开始抽搐。
根据以上各种刁钻的测试结果,有人已经喊出「Anthropic is so back」了。
官方彩蛋
anthropic 还推出了一个包含多个方向提示内容的 prompt 库。如果你想要深入了解 Claude 3 的新功能,可以尝试一下。
链接:https://docs.anthropic.com/claude/prompt-library
写在最后
实际体验下来,Claude 3 真的可以说是超越了 GPT4,但大家别忘记 GPT4 都已经是 2022 年训练完成 的了,OpenAl 会不会有什么秘密大招马上出! 截止到今天的中午两点OpenAl全量发布了两个小功能: 记忆能力和朗读能力来反应Claude3 的大招。

但这完全不够看啊!我最近是不是要深夜看看有没有 GPT5突然出现

24年,AI模型竞争势头依然强劲,这下我已经迫不及待要订阅了目前Claude 网页端已经被“卡爆”,无法体验Sonnet。想体验新版Claude3,需要订阅Pro 那普通用户是否应该订阅Claude 3呢? 如果你不是推理能力&长文本重度需求用户,我的建议是先等一等,等OpenAI大招,等更全的Claude3评测。
参考:












