
本文通过一封618前的R2M(公司内部缓存组件,可以认为等同于Redis)告警,由浅入深的分析了该告警的直接原因与根本原因,并根据原因提出相应的解决方法,希望能够给大家在排查类似问题时提供相应的思路。
一、问题排查
1.1 邮件告警
正值618值班前夕,某天收到了邮件告警,告警内容如下:
您好,R2M监控报警,请您及时追踪一下! 报警信息:告警ID:6825899, 应用:zr_credit_portal, 负责人:zhangsan, 告警类型:内存使用率, 时间:2023-06-15 16:00:04。实例:(10.0.0.0:5011-slave), 当前:9212MB 超过警戒值:8748MB 实例最大内存:10800 MB,内存使用率:85 % ;实例:(10.0.0.0:5023-master), 当前:9087MB 超过警戒值:8748MB 实例最大内存:10800 MB,内存使用率:84 % ;实例:(10.0.0.0:5017-master), 当前:9214MB 超过警戒值:8748MB 实例最大内存:10800 MB,内存使用率:85 % ;
大概内容是说,R2M集群使用率已经达到85%,需要紧急处理下。
我们的缓存集群配置如下,总共32400MB容量,三主三从,每个主节点10800M容量,目前使用最高的已经达到9087M。R2M使用集群模式进行部署。

首先的思路就是使用大key统计,查看是哪些缓存占用了容量。因为大key统计是从节点进行扫描,所以不用担心会影响线上主流程。

1.2 代码分析
大key主要分为两类,一类是xxx_data,一类是xxx_interfacecode_01,按照此规律去代码中寻找存放key的地方
String dataKey = task.getTaskNo() + "_data";
cacheClusterClient.setex(dataKey.getBytes(), EXPIRATION, DataUtil.objectToByte(paramList));
key = task.getTaskNo() + "_" + item.getInterfaceCode() + "_" + partCount;
cacheClusterClient.setex(key.getBytes(), EXPIRATION,DataUtil.objectToByte(dataList));
找到了代码位置后,分析其业务流程:
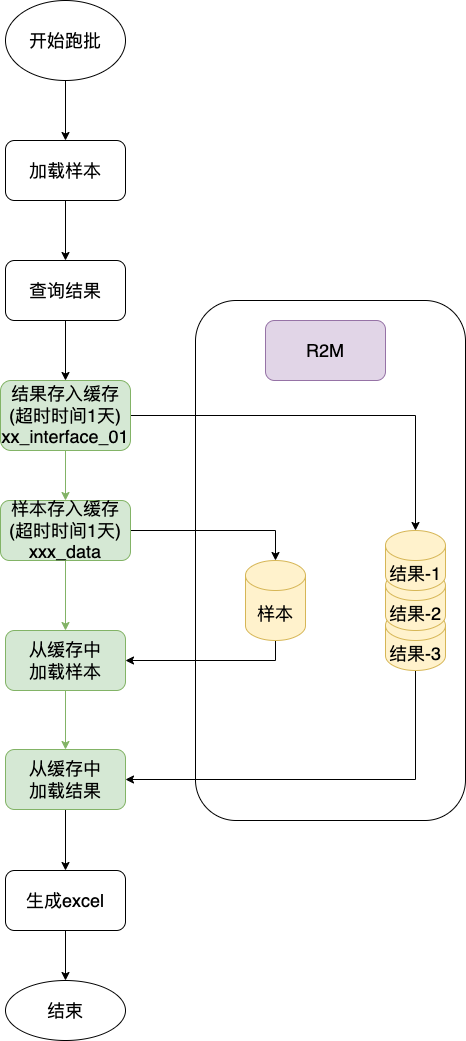
1.3 告警原因
综合上图分析,此次占用率过高的原因可以分为直接原因与根本原因:
1.3.1 直接原因
查看运营后台确实发现有用户在此前三天创建了大量的跑批任务,导致缓存中样本与结果数量增加,从而导致缓存使用率过高。
1.3.2 根本原因
分析代码后,根据上文描述缓存中主要有两块数据:样本与结果
首先是样本在缓存中存了一下随机又取出,本操作毫无意义,只会占用缓存容量。
结果分批分片存储,此步骤有意义,主要是为了防止在多任务并行处理时,如果不将数据分片存入缓存,很有可能导致数据在JVM中占用大量空间,进而导致FULL GC的问题。(之前文章已分析)
跑批结束后,中间数据正常来说已经无用,但是业务流程并没有主动删除无用数据,而是等待超时后自动删除,本操作会导致数据在缓存中额外存储较长时间。
至此,已经分析出了本次缓存使用率过高的原因(其实还没有,直接原因只分析出了表象,直接原因的“根本原因”还未有结论)。
二、问题解决
上文分析了本次告警的排查过程,以下是如何解决问题,也是分为如何解决直接原因与解决根本原因。
2.1 直接原因
2.1.1 原因分析
正值618前夕,最好不考虑操作会对系统产生的影响,因此只能先考虑让对应的用户暂时停止创建跑批,以免继续占用内存导致影响线上业务。
此时观察监控图又发现: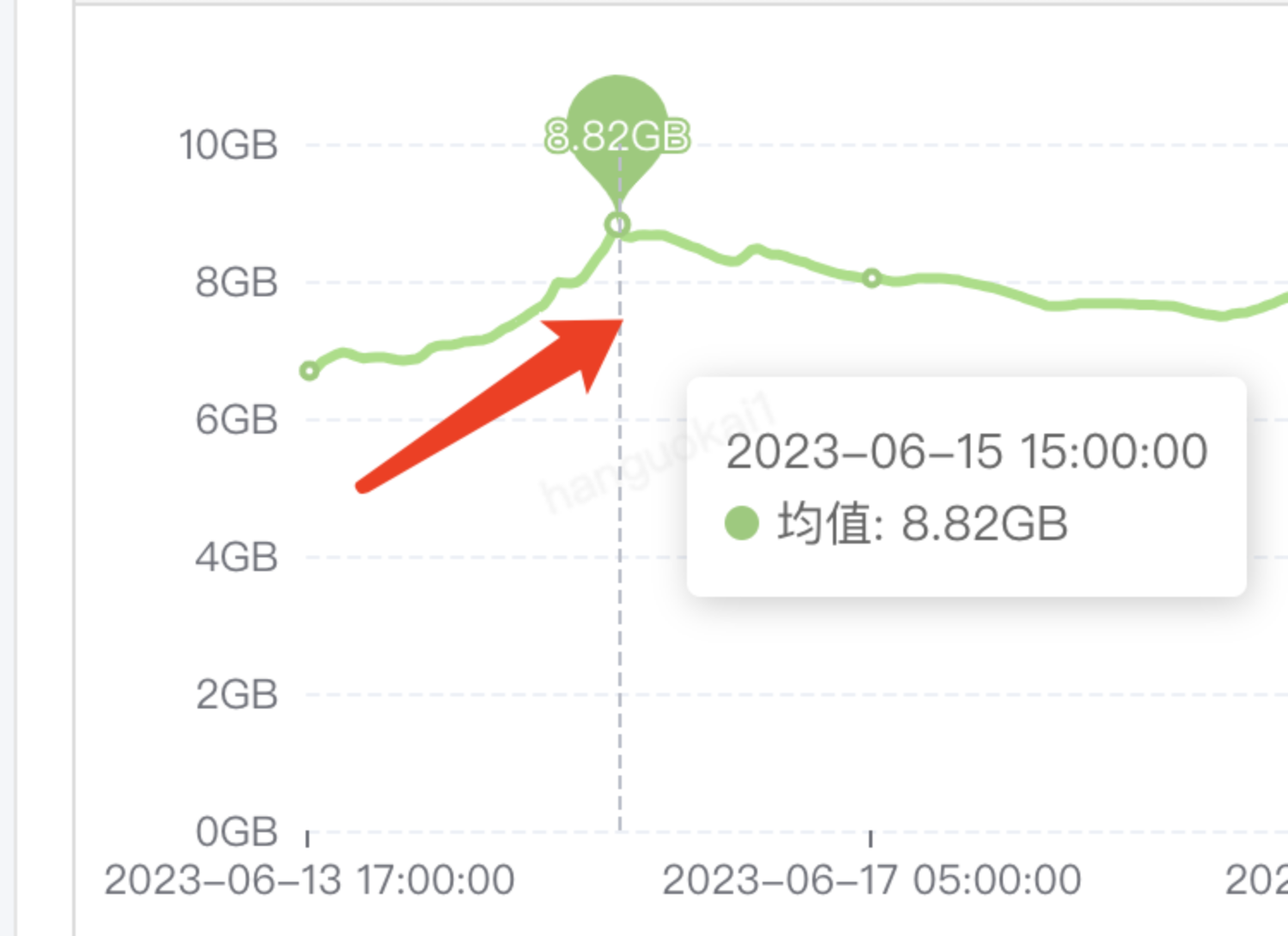
用户是从三天前就开始创建跑批任务的(对应缓存开始增长的时间点),但是缓存的有效期只有一天,按道理来说从第二天开始每天的缓存都应该下降不少才对(因为前一天的已经过期了),为什么看监控图这三天的缓存使用率近乎直线上升呢?
此处可以思考30s,与Redis特性有关。
根据之前刚系统的学完Redis的相关特性,关注到此问题点后,开始思考有没有可能是虽然我们设置了超时时间是一天,但是实际上数据并没有被物理删除呢(Redis的缓存淘汰策略)?
随后查看R2M相关文档:

其中:
如果带有生存时间的键非常多的话, 那么在键的生存时间变为
0, 直到键真正被删除这中间, 可能会有一段比较显著的时间间隔。
这不就是我们的特性吗,从刚刚的我们搜索大key的图中可以看到,我们有很多带超时的key并且size都很大,很有可能虽然已经超时了(即TTL变为0)但该数据并没有访问,并且由于R2M渐进式删除,某一个Key可能会在超时后很久才会被真正的物理删除。
至此,直接原因的根本原因已经找到了。
2.1.2 解决
那么如何解决呢?根据一个Key过期时被物理删除的两种策略:
注意:
Redis 使用以下两种方式删除过期的键
当一个键被访问时,程序会对这个键进行检查,如果键已经过期,那么该键将被删除。
底层系统会在后台渐进地查找并删除那些过期的键,从而处理那些已经过期、但是不会被访问到的键。
首先通过访问的形式去删除数据肯定是愚蠢且没必要的(都能访问并且知道要过期了不如直接删除),那么可以选择提高渐进的查找速率。从而将那些超时的数据物理删除
于是我们联系了R2M对应运维:
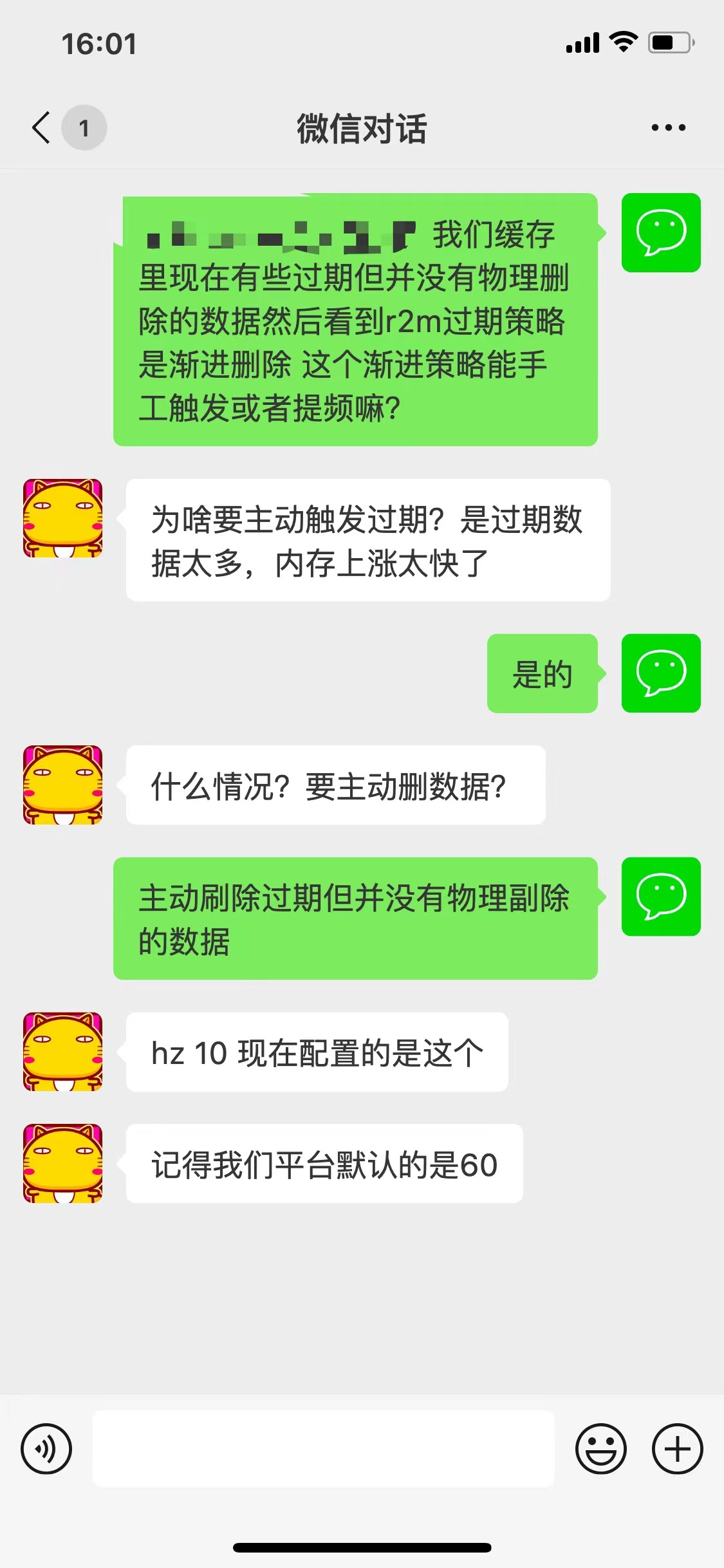
根据上述聊天记录可知,确实有参数可以调整渐进式物理删除的频率,而我们的缓存集群则之前因为不知名原因(项目团队做过更换)被调整为了10,大约降低了六倍,此结果也符合我们的预期,从侧面印证了我们的猜想是正确的。
当时处于618前夕,我们没有并没有修改该参数,在618之后,我们随即提了工单修改该参数,将该参数从10提高到80:
审批通过之后,我们观察r2m的下降速率:
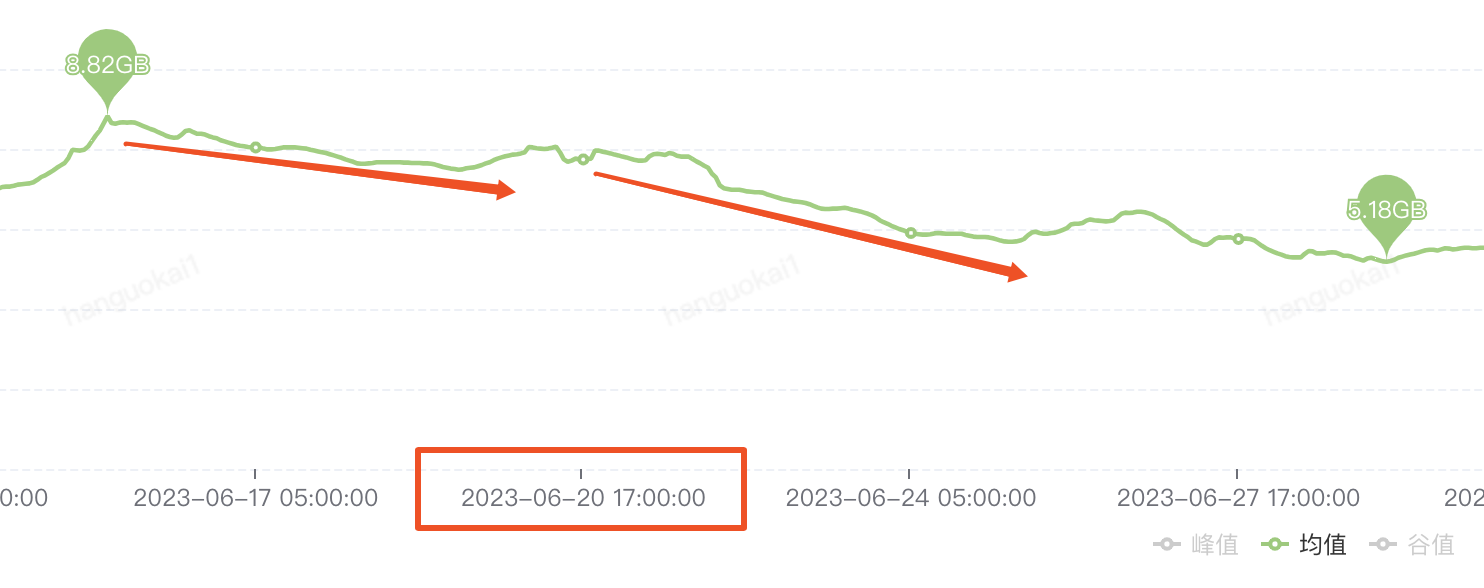
可以看到,在6.20号我们调整了参数后,在没有大批量数据添加后,r2m使用率的下降速率明显变快。
至此,缓存使用率告警的直接原因已经解决完毕,真正的原因就是有大量的key过期后并没有被删除,观察后续缓存使用率都没有太高。此外,即时有大量的跑批任务,如果不是在同一天内直接添加,一般不会造成使用率过高的问题。
2.2 根本原因
上文在调整参数后,基本可以满足用户的日常业务需求,但是如果用户确实有一天之内有大量跑批任务的需求,那么此方案仍不能解决根本问题,还会造成使用率过高有可能影响线上业务的风险。
那么要从根本上解决此问题,就需要对跑批流程进行优化,按照1.2中流程示意以及原因分析:
样本就已经完全没有必要存储在缓存中,所以在代码中直接采用参数传递的方式传入给下一步流程。
结果分片肯定是有意义的,原因上文中也提到了,但是redis缓存的空间(即内存)是比较宝贵的,而oss的空间成本(硬盘)则是比较廉价的,并且考虑本身业务就是离线业务,时效性以及查询速率并不是最关键的因素,因此综合考虑将跑批的结果分片数据存储至oss
在跑批流程结束后,主动删除oss中的结果分片数据,避免数据无用后仍占用存储空间。此外在oss端设置7天自动删除,防止系统原因异常导致数据未删除而永久存在
综上,结合以上的优化思想,重新设计的流程图如下:
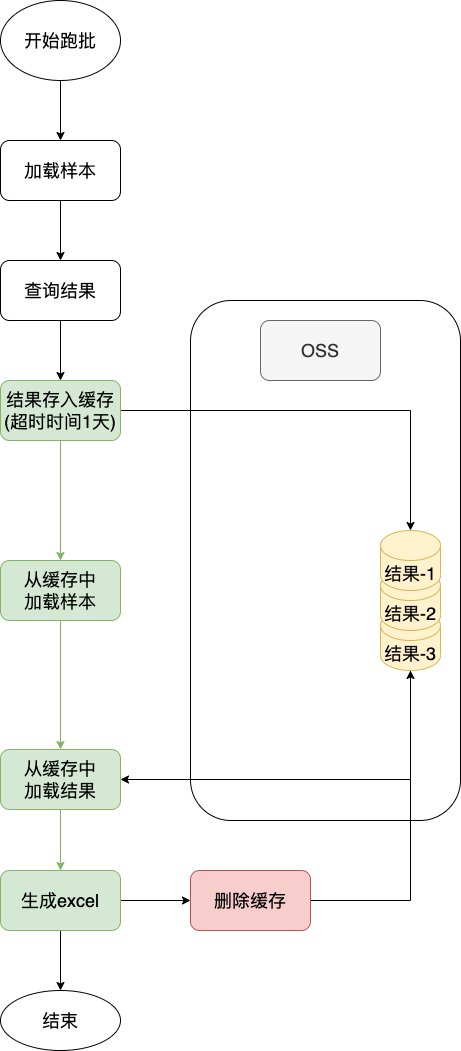
至此,即时后续用户数据量再大,也无论是分一天创建还是多天创建,都不会导致缓存使用率告警而有可能带来的线上业务问题。
2.3 优化率
上线完成后的缓存使用情况:
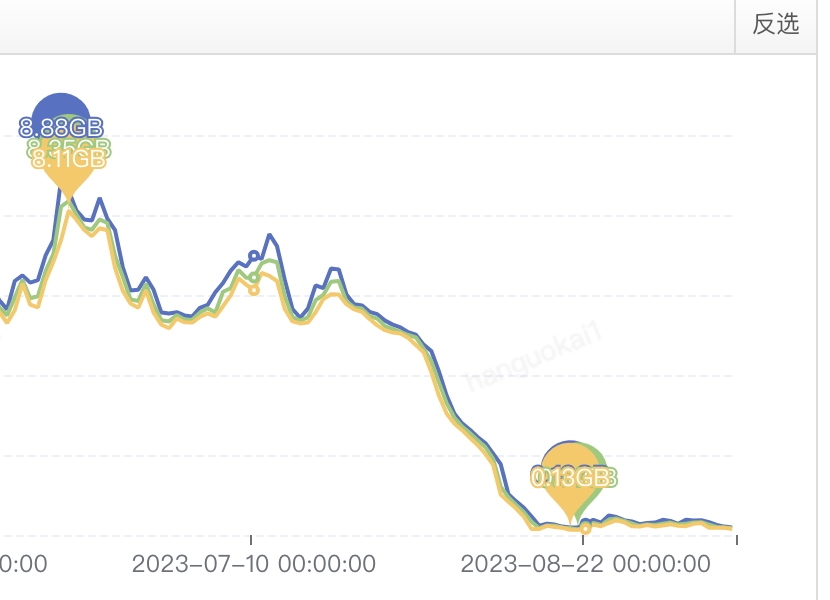
可以看到几乎是断崖式下降。
缓存优化率:
改造前

改造后

(8.35-0.17)/8.35≈97.96%
三、总结
本文主要通过一封告警邮件,由浅入深的将系统中存在的缓存问题与流程优化。在解决完实际问题后,我们应该都会有一些心得与总结,从而下次自己在开发过程中避免再犯这样的问题,也能够自己对自己再做一次总结与归档。要做到能够知其然更要知其所以然。以下总结是自己的由浅入深的一点点心得。
3.1 不同中间件应该负责不同的事
“韩信点兵,多多益善”,一名好的将军就是能将不同的士兵分配不同的职责,从而让士兵能够在自己擅长的领域内各尽其职。对我们研发来说,选择不同的中间件完成不同的功能则是能够反应我们研发的技术水平。
像本文来说,可供存储中间数据的有好多中间件,除了Redis、Oss,还有Mysql、Hive、ES、CK等,我们需要根据不同的业务需求选择不同的中间件完成对应的功能。本案例中很明显数据的特性为大量的、不要求速度的,而Redis的存储特性为少量的、快速的,很明显这两个是背道而驰的需求与业务,因此我们在选用时应该选择正确的中间件。
3.2 学习技术细节有没有用
其实之前也有学了很多的技术、框架的实现细节,但是绝大多数都是学完就学完了,并没有太多实践的环节。而这次案例分析正好处于之前刚刚学完Redis的相关细节,没隔多久就能够应用到本次的实践环节,算是理论与实践结合。此外这次案例也能够很大程度上提升自己的学习兴趣。
作者:京东科技 韩国凯
来源:京东云开发者社区 转载请注明来源








