
搜索引擎的基本数据结构是反向索引,也就是为每个关键词建立了到文档的映射,然后所有的关键词是一个有序列表。
搜索的时候,只要先从有序列表中匹配到关键词,就能搜索到包含该关键词的所有文档,反向索引的数据结构对于关键词搜索的场景是非常高效的。
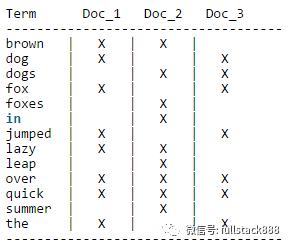
但聚合分析和搜索有很大的不同。典型的场景,比如计算某个文档中每个关键词的出现次数,反向索引就无能为力了,需要先扫描整个关键词映射表,才能找到该文档包含的所有关键词,然后再进行聚合统计(这个例子其实不太准确,因为Lucene在反向索引中冗余了词频的信息,用于计算搜索相关度),也就是要对整个反向索引做全扫描,在数据量大的时候,性能当然好不到哪里去。
所以,Elasticsearch为聚合计算引入了名为fielddata的数据结构,其实就是根据反向索引再次反向出来的一个正向索引,也就是文档到关键词的映射。因为聚合计算也好,排序也好,通常是针对某些列的,实际上生成的是文档到field的多个列式索引,所以叫做fielddata。

这样对文档内的关键词做聚合计算的时候,就只要从fielddata中根据文档ID查找就好。而且,fielddata是保存在内存中的,好处是不占用存储,坏处么,当然上内存不够用啦。而且这个内存是从JVM的Heap上分配的,因为JVM对于大内存的垃圾收集的影响,不能不说对稳定性有很大的挑战,数据量大的时候,时不时的OutOfMemory也不是闹着玩的。因为内存是有限的,所以不可能预先为所有的字段都建立fielddata,只能是由具体的搜索需求来触发。如果是未命中的搜索,还需要先在内存中建立fielddata,这会影响到响应时间。
fielddata的问题在于内存的有限性和JVM对于大内存的垃圾收集对系统带来的稳定性挑战。所以后来又引入了一个新的机制,就是DocValues,从数据结构上来说,它和fielddata是一样的按列的正向索引,但是实现方式不同,DocValues是持久化存储在文件中,并且是预先构建的,也就是数据进入到Elasticsearch时,就会同时生成反向索引和DocValues,这会消耗额外的存储空间,但对于JVM的内存需求会大幅度减少,剩余的内存可以留给操作系统的文件缓存使用。
加上DocValues是预先构建的,查询时也免去了不命中时构建fielddata的时间,所以总体来看,DocValues只比内存fielddata慢大概10~25%,稳定性则有了大幅度提升。从Elasticsearch2.0开始,除了分词过的字符串字段,其他字段已经默认生成DocValues了(可以在索引的Mapping中通过doc_values布尔值来设置)。
简单的说,Elasticsearch通过反向索引做搜索,通过DocValues列式存储做分析,将搜索和分析的场景统一到了一个分布式系统中,还是很有搞头的。
field data格式
按字段的类型的不同,字段对应的doc values的类型可以有不同:
1. String字段
paged_bytes (默认格式):不同的term顺序地存储在一个大的buffer中,每个文档被映射到它所包含的term在buffter中的索引。
fst:term以FST (finite state transducer) 格式存储,载入慢一些,但是在很多term有相同的前缀或者后缀的情况下能够减少内存的使用。
doc_values:索引建立时计算field data并将它存储在磁盘上,占用的内存最少,但是对应的字段必须是not_analyzed。
2. Numeric字段
array (默认格式):field data在内存中以数组的形式存储。
doc_values:索引建立时计算field data并将它存储在磁盘上,占用的内存最少。
3. Geo字段
array (default):经度和维度在内存中以数组的形式存储。
doc_values:索引建立时计算field data并将它存储在磁盘上,占用的内存最少。
打赏(长按扫二维码)

本文分享自微信公众号 - 互联网后端架构(fullstack888)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










