
一、k8s组成部分
Master
1、 kube-apiserver
封装了核心对象的增删改查操作,以REST API接口方式提供给外部和内部组件调用。它维护的REST对象将持久化到Etcd中
2、 kube-controller
负责执行各种控制器,目前已经实现很多控制器来保证Kubernetes的正常运行,部分控制器如下:
Replication Controller(简称RC):
关联RC和Pod,保证RC定义的副本数量与实际pod的数量是一致的。
Deployment Controller:
关联RC和Deployment,保证运行指定数量的的pod,当Deployment更新时,控制实现RC和pod的更新。
3、 kube-scheduler
负责集群的资源调度,为新建的Pod分配机器。这部分工作分出来变成一个组件,意味着可以很方便地替换成其他的调度器
Etcd
k8s重要数据都是持久化在Etcd中的
Node
1、kubelet
负责管控容器,Kubelet会从Kubernetes API Server接收Pod的创建请求,启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。
2、kube-proxy
负责为Pod创建代理服务,Kubernetes Proxy会从Kubernetes API Server获取所有的Service,并根据iptables转发Service信息到对应的pod。NOTE: kube-proxy 要求 NODE 节点操作系统中要具备 /sys/module/br_netfilter 文件,而且还要设置 bridge-nf-call-iptables=1,如果不满足要求,那么 kube-proxy 只是将检查信息记录到日志中,kube-proxy 仍然会正常运行,但是这样通过 Kube-proxy 设置的某些 iptables 规则就不会工作
二、k8s的基本概念
Pod
pod是什么?
一个Pod是一个容器环境下的“逻辑主机”,包含一个或者多个相关的容器,一个node节点下可以有多个pod。
pod下的容器共享资源,包括:
PID 命名空间(同一个Pod中应用可以看到其它进程)
网络 命名空间(同一个Pod的中的应用对相同的IP地址和端口有权限)
IPC 命名空间(同一个Pod中的应用可以通过VPC或者POSIX进行通信)
UTS 命名空间(同一个Pod中的应用共享一个主机名称)
pod中的网络
Pod中的所有容器网络都是共享的,每个pod都有一个ip。通过PodIP,Pod就能够跨网络与其他物理机和容器进行通信
Service
service是什么?
Kubernetes提供了强大的服务编排能力,微服务化应用的每一个组件都以Service进行抽象,组件和组件之间只需要访问Service即可以互相通信,而无须感知组件的集群变化。同时Kubernetes 为Service提供了服务发现的能力,组件和组件之间可以简单地互相发现.
集群外部默认不能访问service ip。若需要外部访问service,Kubernetes提供了NodePort Service、LoadBalancer Service和Ingress可以发布Service
Service由多个pod组成。
两种服务发现方法:环境变量和DNS
环境变量
原理:环境变量中记录了Service的虚拟IP以及端口和协议信息。这样一来,Pod中的程序就可以使用这些环境变量发现Service。
缺点:环境变量是租户隔离的,即Pod只能获取同Namespace中的Service的环境变量。另外,Pod和Service的创建顺序是有要求的,即Service必须在Pod创建之前被创建,否则Service环境变量不会设置到Pod中。DNS服务发现方式则没有这些限制
DNS
原理:DNS服务发现方式需要Kubernetes提供Cluster DNS支持,Cluster DNS会监控Kubernetes API,为每一个Service创建DNS记录用于域名解析,这样在Pod中就可以通过DNS域名获取Service的访问地址。
Pod中的容器使用容器宿主机的DNS域名解析配置/etc/resolv.conf,称为默认DNS配置,另外,如果Kubernetes部署并设置了Cluster DNS支持,那么在创建Pod的时候,默认会将Cluster DNS的配置写入Pod中容器的DNS域名解析配置中,称为Cluster DNS配置。
数据卷
数据卷的作用
数据卷用于实现容器持久化数据,Kubernetes对于数据卷重新定义,提供了丰富强大的功能。数据卷按照功能划分为三类:本地数据卷、网络数据卷和信息数据。
本地数据卷
1、EmptyDir:
Pod被删除,EmptyDir数据卷也会被删除,并且永久丢失
2、HostPath
将容器宿主机上的文件系统挂载到Pod中
网络数据卷
1、NFS
2、iSCSI
信息数据卷
1、Secret
处理敏感数据,比如密码、Token和密钥,相比于直接将敏感数据配置在Pod的定义或者镜像中,Secret提供了更加安全的机制,防止数据泄露
Namespace命名空间
Namespace是Kubernetes提供的多租户,不同的项目、团队或者用户可以通过Namespace进行区分管理,并且设置安全控制和其他策略,实现资源隔离。绝大部分API对象(除了Node)归属于Namespace,API对象通过.metadata.namespace指定Namespace,如果没有指定Namespace,那么归属于默认default。
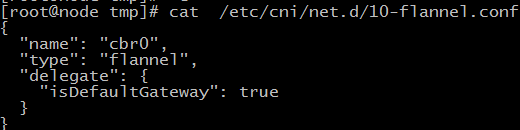
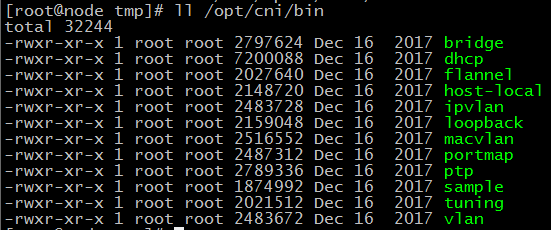
CNI
通过Kubelet传递--network-plugin=cni命令行选项来选择CNI插件。Kubelet从--cni-conf-dir(默认/etc/cni/net.d)读取文件,并使用该文件中的CNI配置来设置每个pod的网络。CNI配置文件必须与CNI规范匹配,并且配置引用的任何所需CNI插件必须存在于--cni-bin-dir(默认/opt/cni/bin)中。
如果目录中有多个CNI配置文件,则使用文件名的词典顺序中的第一个。
除了配置文件指定的CNI插件外,Kubernetes还需要标准的CNI lo插件,最低版本为0.2.0
访问k8s API
使用命令行工具kubectl:
查看pod:kubectl get pod
查看具体pod:kubectl describe pod pod名 --namespace=*
创建资源:kubectl create –f res.yaml
更新资源:kubectl apply –f res.yaml
删除资源:kubectl delete pod pod名
回滚到某个版本 kubectl rollout undo deployment/nginx-deployment --to-revision=2
扩容 kubectl scale deployment nginx-deployment --replicas 10
自动扩容 kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
暂停Deployment kubectl rollout pause deployment/nginx-deployment
恢复Deployment kubectl rollout resume deploy nginx
PS:Deployment的rollout当且仅当Deployment的pod template(例如.spec.template)中的label 更新或者镜像更改时被触发。其他更新,例如扩容Deployment不会触发rollout。
helm管理软件包
Helm之于Kubernetes好比yum之于RHEL。Helm是由helm CLI和Tiller组成,是典型的C/S应用。helm运行与客户端,提供命令行界面,而Tiller应用运行在Kubernetes内部。Helm管理的kubernetes资源包称之为Chart
Endpoints
创建Service的同时,会自动创建跟Service同名的Endpoints
三种ip
Node IP:Node节点的IP地址。 节点物理网卡ip
Pod IP:Pod的IP地址。 Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络
Cluster IP:Service的IP地址。 属于Kubernetes集群内部的地址,无法在集群外部直接使用这个地址
端口
Yaml配置文件中的几种port如下:
targetPort :是pod上的端口
containport:容器的port
port:service的port
将Service的端口号映射到物理机
方式一:nodeport:service的 port,kube-proxy开通宿主机的端口 默认端口范围30000-32768 实现集群外访问内容应用,但是这种方式无法解决负载均衡问题。可以使用经过反向代理kube-proxy流入后端pod的targetport,能实现负载均衡
方式二: 通过设置LoadBalancer映射到云服务商提供的LoadBalancer地址, 被提供的负载均衡器的信息将会通过 Service 的 status.loadBalancer 字段被发布出去。
访问多集群
将当前上下文更改为 exp-scratch:
kubectl config --kubeconfig=config-demo use-context exp-scratch
安全性
访问api验证授权具体步骤
1、 认证
认证模块包括客户端证书,密码,明文token,初始token,和JWT token(用于服务账号)。可以同时指定多个认证模块,对于这种情况,会按照指定的顺序一个个尝试认证,直到有一个认证成功为。
2、 授权
一个请求必须包含请求者的用户名,请求的动作,影响动作的对象。如果有存在的策略声明这个用户有权限完成这个动作,那么该请求就会被授权。当配置多个授权模块时,按顺序检查每个模块,如果有任何模块授权请求,则可以继续执行该请求。如果所有模块拒绝请求,则拒绝该请求(HTTP状态代码403)。
3、 准入控制
如果准入控制插件序列中任何一个拒绝了该请求,则整个请求将立即被拒绝并且返回一个错误给终端用户。
用户账号 vs 服务账号(Service account)
1、 用户账号是给人使用的。服务账号是给 pod 中运行的进程使用的
2、 用户账号为全局设计的。命名必须在一个集群的所有命名空间中唯一,未来的用户资源不会被设计到命名空间中。 服务账号是在命名空间里的。
服务账号自动化
服务账号的自动化由三个独立的组件共同配合实现:
一、 服务账号准入控制器(Service account admission controller)
在pod被创建或者更改时,它会做如下操作:
1、 如果pod没有配置ServiceAccount,它会将ServiceAccount设置为default。
2、 确保被pod关联的ServiceAccount是存在的,否则就拒绝请求。
3、 如果pod没有包含任何的ImagePullSecrets,那么Serviceaccount的 ImagePullSecrets就会被添加到pod。
4、 它会把volume添加给pod,该pod包含有一个用于API访问的令牌。
5、 它会把volumeSource 添加到pod的每个容器,挂载到/var/run/secrets/kubernetes.io/serviceaccount。
二、令牌控制器(Token controller)
三、 服务账号控制器(Service account controller)
DaemonSet
DaemonSet能够让所有(或者一些特定)的Node节点运行同一个pod。当节点加入到kubernetes集群中,pod会被(DaemonSet)调度到该节点上运行,当节点从kubernetes集群中被移除,被(DaemonSet)调度的pod会被移除,如果删除DaemonSet,所有跟这个DaemonSet相关的pods都会被删除。
例如如下场景:
每个Node上运行一个分布式存储的守护进程,例如glusterd,ceph
每个Node上运行日志采集器,例如fluentd,logstash
每个Node上运行监控的采集端,例如Prometheus Node Exporter, collectd等
Taints和Tolerations
Taints定义在Node节点上,声明污点及标准行为Tolerations定义在Pod,声明可接受得污点具有 taint 的 node 和 pod 是互斥关系
annotations:
scheduler.alpha.kubernetes.io/taints:'[{"key":"dedicated","value":"master","effect":"NoSchedule"}]'
亲和性和反亲和性
亲和性:应用A与应用B两个应用频繁交互,所以有必要利用亲和性让两个应用的尽可能的靠近,甚至在一个node上,以减少因网络通信而带来的性能损耗。
反亲和性:当应用的采用多副本部署时,有必要采用反亲和性让各个应用实例打散分布在各个node上,以提高HA。
NodeName和NodeSelector
Pod.spec.nodeName用于强制约束将Pod放到到指定的Node名字节点上
Pod.spec.nodeSelector是通kubernete的label-selector机制进行节点选择,由scheduler调度策略MatchNodeSelector进行label匹配,调度pod到目标节点,该匹配规则是强制约束。
四、 通过yaml文件创建资源
比如创建RC资源
RC通过spec.selector关联pod的label,
RS和RC通spec.template设置Pod。
RS比RC的区别:RS使用基于集合的标签选择器
五、 kubectl常用命令
查看部署状态
kubectl rollout status deployment/email
更新镜像
kubectl set image deployment/email email=10.15.37.119/hic/email:tag4 busybox=busybox
将部署的email容器镜像设置为'email:tag4',其busybox容器映像设置为'busybox'。
PS:如果本地制作镜像,启动或更新pod时,对应node上必须有镜像才行
回滚上一次版本
kubectl rollout undo deployment/email
#查看pod运行在那个节点
kubectl get po -o wide











