1.1 关于Apache Shiro
Apache shiro是一个Java安全框架,提供了认证、授权、加密和会话管理功能,为解决应⽤安全提供了相应的API:
1.认证-⽤用户身份识别,常被称为用户”登录”
2.授权-访问控制
3.密码加密-保护或隐藏数据防止被偷窥
4.会话管理-用户相关的时间敏感的状态
1.2 Shiro反序列化
1.2.1 反序列化漏洞
Shiro550:
shiro≤1.2.4版本,默认使⽤了CookieRememberMeManager,由于AES使用的key泄露,导致反序列化的cookie可控,从而引发反序列化攻击。(理论上只要AES加密钥泄露,都会导致反序列化漏洞)
1.2.2 Shiro识别
要想识别Apache Shiro反序列列化漏洞,首先应该判断相关的Web站点是否使⽤了shiro框架。主要有以下⽅式:
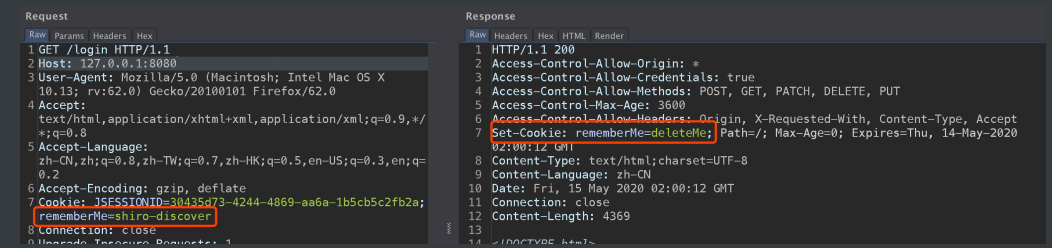
● rememberMe
可以在 cookie 追加一个 rememberMe=xx 的字段,这个字段是rememberMeManager默认的,然后看响应头部可以看看是否有 Set-Cookie: rememberMe=deleteMe; 的字段则可判断使⽤了shiro框架:
● 自定义的 rememberMe字段
前⾯通过在Cookie追加rememberMe字段进⾏判断,实际上这个默认字段的命名是可以修改的,Shiro支持在rememberMe管理器中自定义名称,可以通过在配置⽂件进⾏配置,例如下⾯的例子,将rememberMe设置成了了rememberMeTK:

同理,在springboot集成Shiro时也可以通过在shiro配置类中添加rememberMeManager的配置,修改默认命名为rememberMeTK:

然后在securityManager中注册:

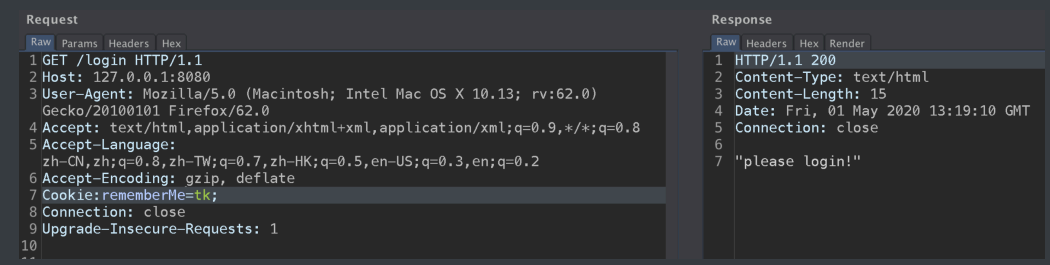
通过上述方式配置后,在cookie中添加rememberMe就不会有deleteMe返回了:
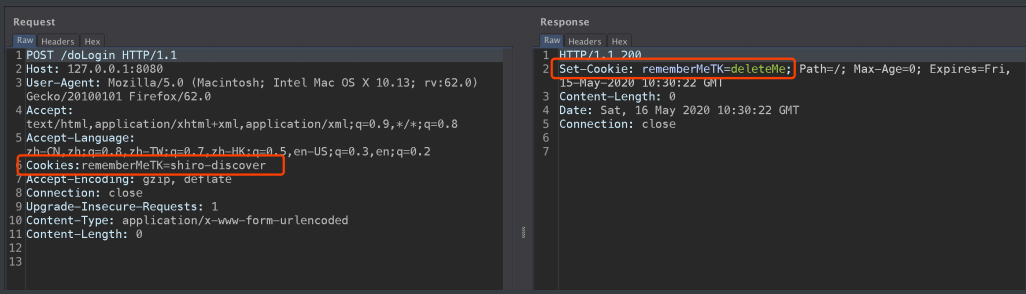
当使⽤我们设置的rememberMeTK字段尝试探测时,响应中成功返回熟悉的deleteMe:
这种方式从一定程度上增加了探测识别shiro框架的难度,但是如果可以正常登录的话,是可以得到相关的值的,
因为这个rememberMe本身是Shiro 提供了记住我(RememberMe)的功能,比如访问如淘宝等一些站时,关闭了浏览 器下次再打开时还是能记住你是谁,下次访问时需再登录即可访问。
基本流程是先在登录页面选中 RememberMe 然后登录成功;如果是浏览器登录一般会把 相关 的Cookie字段,也就是我们探测的关键字段(例例如rememberMeTK)写到客户端并保存下来。那么此时只要去浏览器本地查看即可。
可以通过burp插件的⽅方式,在每一个请求发起时自动在cookie中追加探测字段(例如rememberMe=tkswifty),如果响应中包含=deleteMe则直接亮显示,那么就可以很便捷的发现使⽤了shiro的站点,进一步进行漏洞发现利了:
● 相关cms
一些cms本身就是基于shiro进⾏开发的,例如jeesite、 jeecg、 ......
1.2.3 关键因素
整个漏洞简单的cookie处理流程是:得到rememberMe的cookie值-->Base64解码-->AES解密-->反序列化。除了找到相关的参数(默认rememberMe)以外,还需要结合如下因素:
● key
shiro在1.4.2版本之前, AES的模式为CBC, IV是随机生成的,并且IV并没有真正使用起来。所以整个AES加解密过程的key就很重要了,正是因为AES使用默认的KEY/常见的KEY/KEY泄露导致反序列化的cookie可控,从⽽引发反序列化漏洞。
常见的key如下:

有时候可能存在未知key的情况,那么可以采取 Shiro-721 的报错逻辑来进⾏遍历key(前提是正常登录得到一个rememberMe的值):
Shiro721:
rememberMe cookie通过AES-128-CBC模式加密,易受到Padding Oracle攻击。可以通过结合有效的rememberMe cookie作为Padding Oracle攻击的前缀,然后精⼼制作rememberMe来进⾏反序列化攻击。
Tip:可以结合JRMP gadget使⽤用,可以⼤大幅减少生成序列化数据的长度,同时在1.4.2版本后,shiro已经更换 AES-CBC AES-CBC 为 AES-GCM AES-GCM ,无法再通过Padding Oracle遍历key。
● 可用gadget
利⽤链(gadget chains),俗称gadget。通俗来说就是一种利⽤方法,它是从触发位置开始到执⾏命令的位置结束,也可以说是漏洞验证方法(POC)。shiro反序列化中常⽤的有(遇到过的):

1.2.4漏洞识别
● 基于OOB
可以使用ysoserial-URLDNS-gadget结合dnslog进⾏检测,其不受JDK版本和安全策略影响, 除非存在网络限制DNS不能出网。构造好对应的请求后,若dnslog成功记录到记录,则可以说明漏洞存在。
并且这种方式也是遍历key很不错的方法,通过在dnslog域名前加⼊对应key的randomNum,记录到对应请求时即可直接定位对应的key了:
● 基于时间延迟
在不出网的情况下,可以结合SQL盲注的思路,可以考虑结合时间延迟进⾏判断和获取数据,可以通过改写ysoserial,执⾏对应的时间延迟代码,例如这里如果系统不是windows类型的话则会进行时间延迟:

具体效果
● 基于报错
在不出⽹的情况下,若相关web应⽤未屏蔽报错信息,可以考虑结合触发Java异常进⾏判断和获取数据,可以通过改写ysoserial,执⾏对应的代码进⾏异常抛出,例如下⾯的代码,通过抛出NoClassDefFoundError异常,在异常信息中输出shiro-vul-discover关键字进⾏判断

具体效果
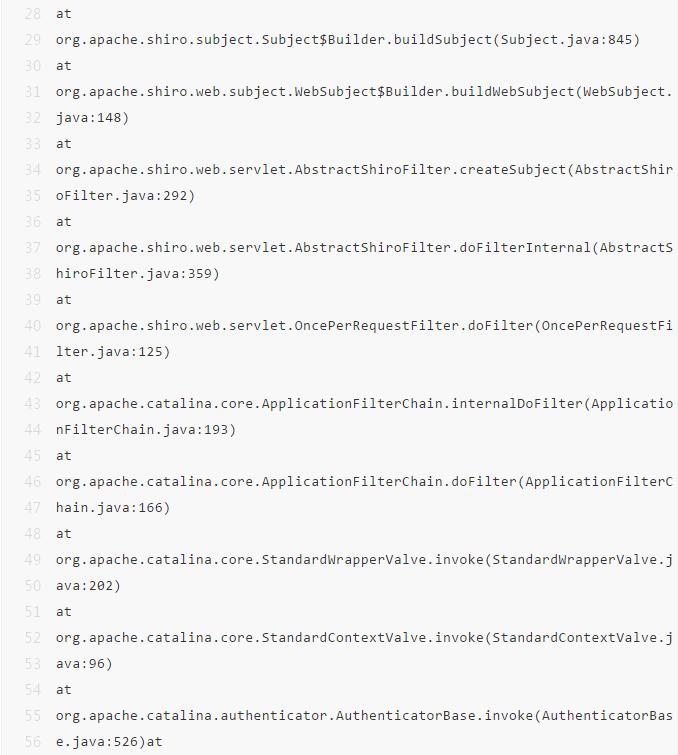
1.3日志审计
在⽇志信息⾥是可以看到序列化报错的信息的,可以根据相关日志查看相关应⽤是否遭到shiro反序列化攻击尝试
以在Tomcat的报错⽇志 catalina.out 为例,关注RememberMeManager的相关信息可以看到相关的异常: