


(图片来源于网络)
场景:****Redis面试

(图片来源于网络)
面试官:我看到你的简历上说你熟练使用Redis,那么你讲一下Redis是干嘛用的?
小明:(心中窃喜,Redis不就是缓存吗?)Redis主要用作缓存,通过内存高效地存储非持久化数据。
面试官:Redis可以用作持久化的存储吗?
小明 :嗯...应该可以吧...
面试官:那Redis怎么进行持久化操作呢?
小明:嗯...不是太清楚。
面试官:Redis的内存淘汰机制有哪些?
小明:嗯...没了解过
面试官:我们还可以用Redis做哪些事情?分别利用了Redis的哪个指令?
小明:我只知道Redis还可以做分布式锁、消息队列...
面试官:好了,我们进入下一个话题...
思考:很明显,小明同学在面试过程中关于Redis的表现和回答肯定是比较失败的。Redis是我们工作中每天都会使用到的东西,为什么一到面试却变成了丢分项呢?
作为开发者,我们习惯了使用大神们已经封装好的东西,以此保障我们能够更专注于业务开发,却不知道这些常用工具的底层实现是什么,因此尽管平时应用起来得心应手,但一到面试还是无法让面试官眼前一亮。
本文总结了一些Redis的知识点,有原理有应用,希望可以帮助到大家。
Redis是什么
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI 、C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
这里我引用了Redis教程里对Redis的描述,很官方,但是很标准。 可基于内存亦可持久化的日志型、Key-Value数据库。 我认为这个描述很贴切很全面。
Redis的行业地位
Redis是互联网技术领域使用最为广泛的存储中间件,因超高的性能、完美的文档、多方面的应用能力以及丰富完善的客户端支持在存储方面独当一面,广受好评,尤其以其性能和读取速度而成为了领域中最受青睐的中间件。基本上每一个软件公司都会使用Redis,其中包括很多大型互联网公司,比如京东、阿里、腾讯、github等。因此,Redis也成为了后端开发人员必不可少的技能。
知识图谱
在我看来,学习每一项技术,都需要有一个清晰的脉络和结构,不然你也不知道自己会了哪些、还有多少没学会。就像一本书,如果没有目录章节,也就失去了灵魂。
因此我试图总结出Redis的知识图谱,也称为脑图,如下图所示,可能知识点不是很全,后续会不断更新补充。
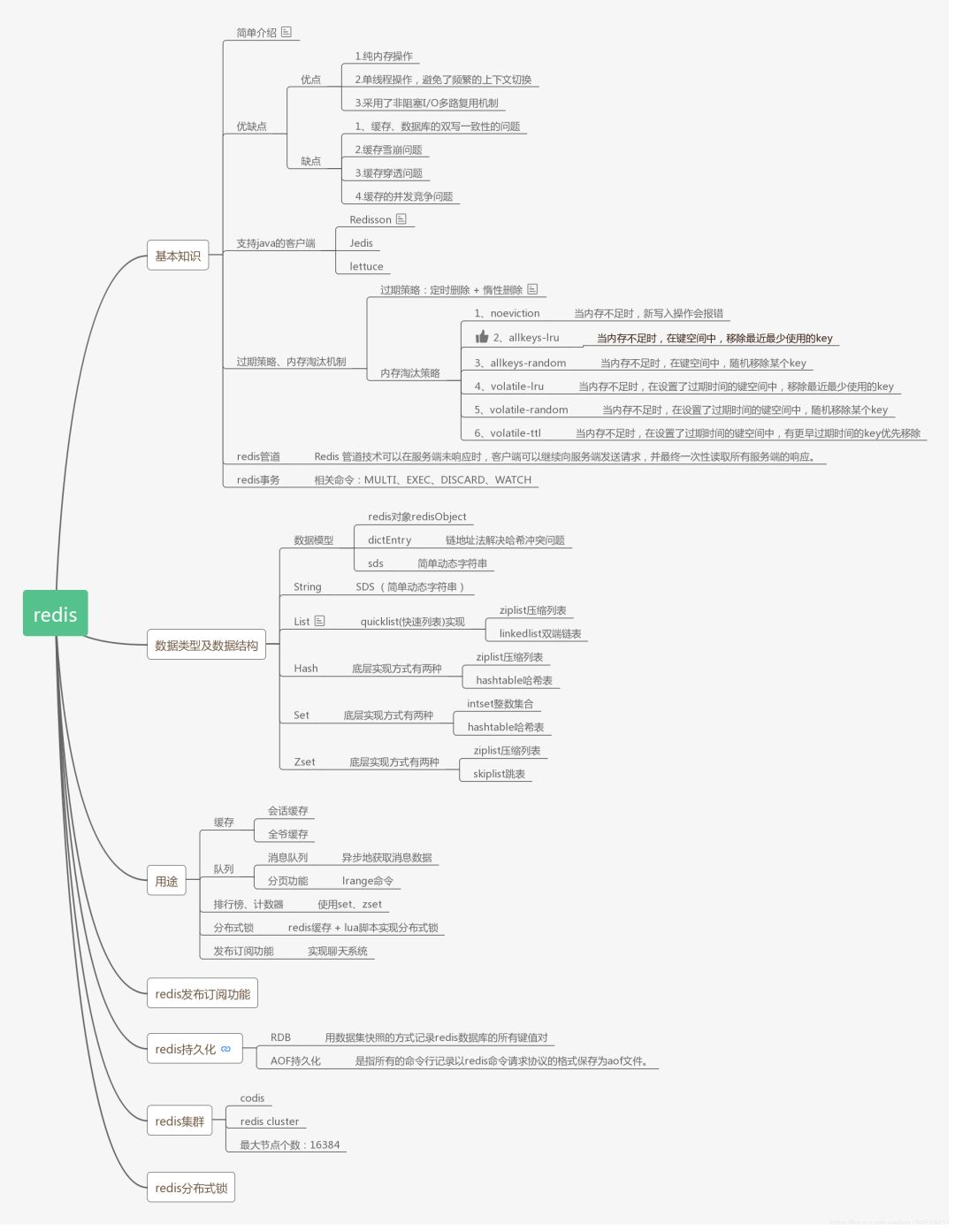
本系列文章的知识点也会和这个脑图基本一致,本文先介绍Redis的基本知识,后续文章会详细介绍Redis的数据结构、应用、持久化等多个方面。
Redis优点
速度快
作为缓存工具,Redis最广为人知的特点就是快,到底有多快呢?Redis单机qps(每秒的并发)可以达到110000次/s,写的速度是81000次/s。那么,Redis为什么这么快呢?
绝大部分请求是纯粹的内存操作,非常快速;
使用了很多查找操作都特别快的数据结构进行数据存储,Redis中的数据结构是专门设计的。如HashMap,查找、插入的时间复杂度都是O(1);
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁、释放锁操作,没有因为可能出现死锁而导致的性能消耗;
用到了非阻塞I/O多路复用机制。
丰富的数据类型
Redis有5种常用的数据类型:String、List、Hash、set、zset,每种数据类型都有自己的用处。
原子性,支持事务
Redis支持事务,并且它的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
丰富的特性
Redis具有丰富的特性,比如可以用作分布式锁;可以持久化数据;可以用作消息队列、排行榜、计数器;还支持publish/subscribe、通知、key过期等等。当我们要用中间件来解决实际问题的时候,Redis总能发挥出自己的用处。
Redis和Memcache对比
Memcache和Redis都是优秀的、高性能的内存数据库,一般我们说到Redis的时候,都会拿Memcache来和Redis做对比。(为什么要做对比呢?当然是要衬托出Redis有多好,没有对比,就没有伤害~)对比的方面包括:
1) 存储方式
Memcache把数据全部存在内存之中,断电后会挂掉,无法做到数据的持久化,且数据不能超过内存大小。
Redis有一部分数据存在硬盘上,可以做到数据的持久性。
2) 数据支持类型
Memcache对数据类型支持相对简单,只支持String类型的数据结构。
Redis有丰富的数据类型,包括:String、List、Hash、Set、Zset。
3) 使用的底层模型
它们之间底层实现方式以及与客户端之间通信的应用协议不一样。
Redis直接自己构建了VM机制 ,因为一般的系统调用系统函数,会浪费一定的时间去移动和请求。
4) 存储值大小
- Redis最大可以存储1GB,而memcache只有1MB。
看到这里,会不会觉得Redis特别好,全是优点,完美无缺?其实Redis还是有很多缺点的,这些缺点平常我们该如何克服呢?
Redis存在的问题及解决方案
缓存数据库的双写一致性的问题
问题:一致性的问题是分布式系统中很常见的问题。一致性一般分为两种:强一致性和最终一致性,当我们要满足强一致性的时候,Redis也无法做到完美无瑕,因为数据库和缓存双写,肯定会出现不一致的情况,Redis只能保证最终一致性。
解决:我们如何保证最终一致性呢?
第一种方式是给缓存设置一定的过期时间,在缓存过期之后会自动查询数据库,保证数据库和缓存的一致性。
如果不设置过期时间的话,我们首先要选取正确的更新策略:先更新数据库再删除缓存。但我们删除缓存的时候也可能出现某些问题,所以需要将要删除的缓存的key放到消息队列中去,不断重试,直到删除成功为止。
缓存雪崩问题
问题: 我们应该都在电影里看到过雪崩,开始很平静,然后一瞬间就开始崩塌,具有很强的毁灭性。这里也是一样的,我们执行代码的时候将很多缓存的实效时间设定成一样,接着这些缓存在同一时间都会实效,然后都会重新访问数据库更新数据,这样会导致数据库连接数过多、压力过大而崩溃。
解决:
设置缓存过期时间的时候加一个随机值。
设置双缓存,缓存1设置缓存时间,缓存2不设置,1过期后直接返回缓存2,并且启动一个进程去更新缓存1和2。
缓存穿透问题
问题: 缓存穿透是指一些非正常用户(黑客)故意去请求缓存中不存在的数据,导致所有的请求都集中到到数据库上,从而导致数据库连接异常。
解决:
利用互斥锁。缓存失效的时候,不能直接访问数据库,而是要先获取到锁,才能去请求数据库。没得到锁,则休眠一段时间后重试。
采用异步更新策略。无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
提供一个能迅速判断请求是否有效的拦截机制。比如利用布隆过滤器,内部维护一系列合法有效的key,迅速判断出请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存的并发竞争问题
问题:
缓存并发竞争的问题,主要发生在多线程对某个key进行set的时候,这时会出现数据不一致的情况。
比如Redis中我们存着一个key为amount的值,它的value是100,两个线程同时都对value加100然后更新,正确的结果应该是变为300。但是两个线程拿到这个值的时候都是100,最后结果也就是200,这就导致了缓存的并发竞争问题。
解决
如果多线程操作没有顺序要求的话,我们可以设置一个分布式锁,然后多个线程去争夺锁,谁先抢到锁谁就可以先执行。这个分布式锁可以用zookeeper或者Redis本身去实现。
可以利用Redis的incr命令。
当我们的多线程操作需要顺序的时候,我们可以设置一个消息队列,把需要的操作加到消息队列中去,严格按照队列的先后执行命令。
Redis的过期策略
Redis随着数据的增多,内存占用率会持续变高,我们以为一些键到达设置的删除时间就会被删除,但是时间到了,内存的占用率还是很高,这是为什么呢?
Redis采用的是定期删除和惰性删除的内存淘汰机制。
定期删除
定期删除和定时删除是有区别的:
定时删除是必须严格按照设定的时间去删除缓存,这就需要我们设置一个定时器去不断地轮询所有的key,判断是否需要进行删除。但是这样的话cpu的资源会被大幅度地占据,资源的利用率变低。所以我们选择采用定期删除,。
定期删除是时间由我们定,我们可以每隔100ms进行检查,但还是不能检查所有的缓存,Redis还是会卡死,只能随机地去检查一部分缓存,但是这样会有一些缓存无法在规定时间内删除。这时惰性删除就派上用场了。
惰性删除
举个简单的例子:中学的时候,平时作业太多,根本做不完,老师说下节课要讲这个卷子,你们都做完了吧?其实有很多人没做完,所以需要在下节课之前赶紧补上。
惰性删除也是这个道理,我们的这个值按理说应该没了,但是它还在,当你要获取这个key的时候,发现这个key应该过期了,赶紧删了,然后返回一个'没有这个值,已经过期了!'。
现在我们有了定期删除 + 惰性删除的过期策略,就可以高枕无忧了吗?并不是这样的,如果这个key一直不访问,那么它会一直滞留,也是不合理的,这就需要我们的内存淘汰机制了。
Redis的内存淘汰机制
Redis的内存淘汰机制一般有6种,如下图所示:

那么我们如何去配置Redis的内存淘汰机制呢?
在Redis.conf中我们可以进行配置
# maxmemory-policy allkeys-lru
小结
本文初探Redis,大概整理出了Redis的知识图谱,对照之下可以发现Redis居然有这么多的知识点需要学习;接着我们分析了Redis的优缺点,知道了其基于内存的高效的读写速度和丰富的数据类型,也分析了Redis面对数据一致性、缓存穿透、缓存雪崩等问题时该如何处理;最后我们了解了Redis的过期策略和缓存淘汰机制。
相信大家已经对Redis有了一些了解,下篇文章我们将分析Redis的数据结构、每一种数据类型是如何实现的、对应的命令有哪些。
⭐️⭐️⭐️欢迎加入“宜信技术交流群”。进群方式:请加小助手微信(微信号:creditease_tech)。
◆ ◆ ◆ ◆ ◆
如需转载请与小助手(微信号:creditease_tech)联系。****发现文章有错误、对内容有疑问,都可以通过关注宜信技术学院微信公众号(CE_TECH),在后台留言给我们。我们每周会挑选出一位热心小伙伴,送上一份精美的小礼品。快来扫码关注我们吧!
⏬点击“阅读原文”查看更多技术干货

本文分享自微信公众号 - 宜信技术学院(CE_TECH)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












