
linux下作为服务
Elasticsearch创建了debian安装包和rpm安装包,可以在官网的下载页面中进行下载。安装包需要依赖JAVA,除此就没有任何依赖。
在debian系统下可以使用 标准的系统工具,init脚本放在 /etc/init.d/elasticsearch下,配置文件默认放在 /etc/default/elasticsearch下。从Debian软件包安装好后默认是不启动服务的。其原因是为了防止实例不小心加入群集。安装好后用dpkg -i命令来确保,当系统启动后启动Elasticsearch需要运行下面的两个命令:
sudo update-rc.d elasticsearch defaults 95 10
sudo /etc/init.d/elasticsearch start
当用户运行Debian8或者Ubuntu14或者更高版本的时候,系统需要用systemd 来代替update-rc.d,在这种情况下,请使用systemd来运行,参见下面的介绍。
Elasticsearch通常的建议是使用Oracle的JDK。可以用下面的命令安装。
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer
java -version
基于RPM的系统一般使用chkconfig来启用和禁用服务。init脚本位于/etc/init.d/elasticsearch下,配置文件放在/etc/sysconfig/Elasticsearch下。同Debian系统类似,安装好后也不会自动加入自启动服务中。需要手工指定。
sudo /sbin/chkconfig --add elasticsearch
sudo service elasticsearch start
systemd服务启动。
很多linux系统,例如Debian Jessie, Ubuntu 14等,系统不使用chkconfig来注册服务,取而代之的是用systemd来启动和停止服务。命令是 /bin/systemctl 来启动和停止服务。rpm包安装的配置文件在/etc/sysconfig/elasticsearch下,deb包安装的配置文件在 /etc/default/elasticsearch下。安装RPM之后,你必须改变系统配置,然后启动Elasticsearch。
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable elasticsearch.service
sudo /bin/systemctl start elasticsearch.service
同时注意改变在/etc/sysconfig/elasticsearch中的MAX_MAP_COUNT设置是没有任何效果的。需要改变/usr/lib/sysctl.d/elasticsearch.conf中的配置才起作用。
window下作为服务
Windows用户可以配置Elasticsearch作为服务运行在后台运行,或在没有任何用户交互启动时自动启动。这可以通过bin目录下的service.bat脚本来实现,可以安装,卸载,管理或配置服务命令行为:service.bat install|remove|start|stop|manager [SERVICE_ID]
SERVICE_ID是服务id可以不用指定用默认的值,系统可以安装多个服务。manager是启动图形界面的配置。例如运行:service install后显示的内容如下
Installing service : "elasticsearch-service-x64"
Using JAVA_HOME (64-bit): "C:\Program Files\Java\jdk1.7.0_79"
The service 'elasticsearch-service-x64' has been installed.
安装好后,有两种方法可以对服务进行设置。
1、图形化界面,可以用命令service manager来启动图形界面。执行后显示界面如下。
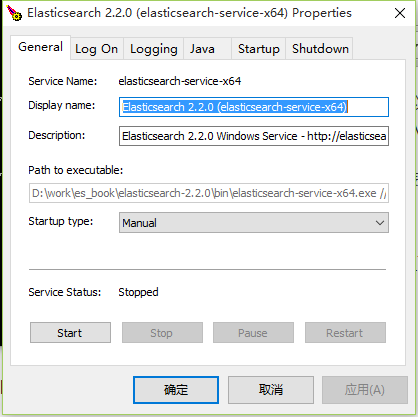
2、用命令service start ,service stop来启动停止服务。
还有一个社区支持的可定制MSI安装程序:https://github.com/salyh/elasticsearch-msi-installer也可以安装成服务。
赛克蓝德(secisland)后续会逐步对Elasticsearch的最新版本的各项功能进行分析,近请期待。也欢迎加入secisland公众号进行关注。












