
前言
最近在开发一个基于Nessus的自动化漏扫工具,来和大家分析一下关于Nessus API的使用心得。
Nessus提供了非常完善的API,可以帮助我们实现很多事情,无论是对接其他运维系统,还是用来编写自动化的漏扫工具都十分方便。
Nessus为这些api提供了详细的文档,你可以在Settings->My Account->API Keys->API documentation里看到。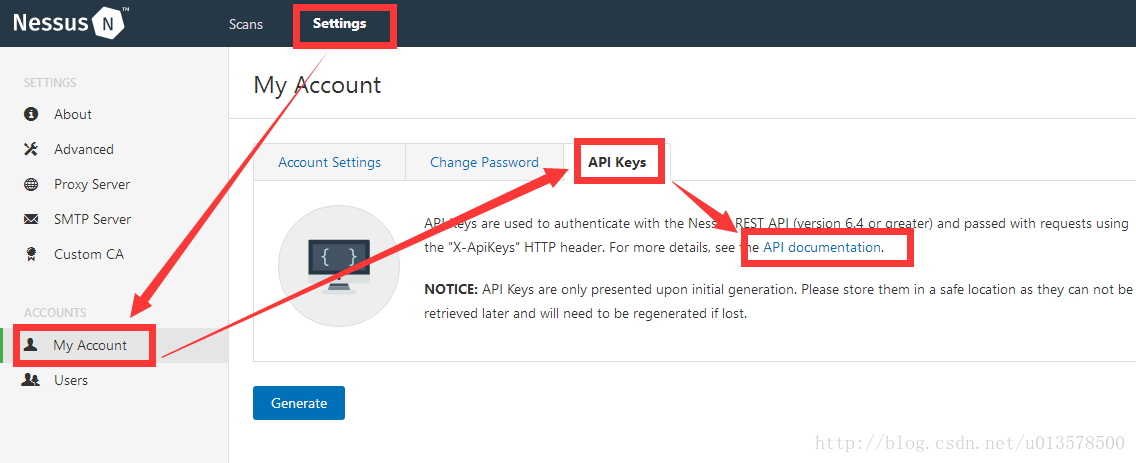
当然,你也可以直接在url后面加上‘api’来访问,像这样https://localhost:8834/api
一、登录
无论是发起一次扫描,还是获取扫描的结果,首先都需要进行登录,nessus在这里提供了两种登录方式。相关内容可以在API文档的https://localhost:8834/api#/resources/session条目中找到。
1、session create
第一种方式是使用Nessus的用户名密码,使用/session接口:
POST /session
向/session接口发送post请求,请求的payload参数为用户名和密码。代码如下:
# coding=utf-8
import requests
import json
def login_create():
# 登录成功则返回token,否则返回空
token = ''
# 调用/session接口
url = "https://localhost:8834/session"
# nessus的用户名密码作为post的payload
data = {
'username': 'admin',
'password': 'admin'
}
# 发送请求
respon = requests.post(url, data=data, verify=False)
# 如果请求成功则返回token值
if respon.status_code == 200:
# 返回值是一个json字符串,用json.loads解析成字典取值
token = json.loads(respon.text)['token']
return token若用户名和密码正确,/session接口会返回一个token,将这个token放入请求的头信息中,之后的请求中带上这个头信息就可以使用了。举一个例子:
def get_scans_list():
# 返回结果
result = ''
# 首先获取一下token
token = login_create()
if token != '':
# 调用/folders接口
url = "https://localhost:8834/scans"
# 组装一个请求的头,把刚刚拿到的token放入请求头
header = {'X-Cookie': 'token={token};'.format(token=token),
'Content-type': 'application/json',
'Accept': 'text/plain'}
respon = requests.get(url, headers=header, verify=False)
# 请求成功,则返回结果,否则返回空值
if respon.status_code == 200:
result = json.loads(respon.text)
return result2、API Key
除了使用用户名密码的方式,Nessus还提供了API key的方式,只需将Nessus生成的accessKey和secretKey放入请求头信息中即可。之后的例子都会使用API key的方式来调用。
API key可以通过Settings->My Account->API Keys->Generate获取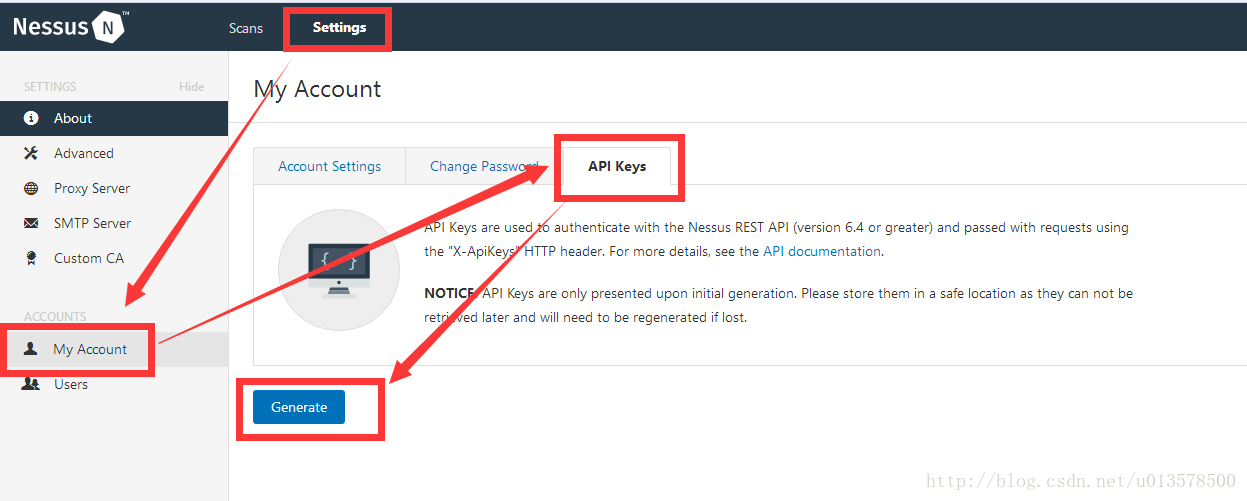
还是用get_scans_list做例子:
def get_scans_list():
# 返回结果
result = ''
# 调用/folders接口
url = "https://localhost:8834/scans"
# Nessus生成的API key
accesskey = 'b901cfe7e184801952db08795fa23f48f1f6c50732f0765e229975354aa58f92'
secretkey = '860ad22d0536dd8fd88d3f93901d78cfe4cbc4dbd37bc17ba72a7e989f160739'
# 组装请求头
header = {'X-ApiKeys': 'accessKey={accesskey};secretKey={secretkey}'.format(accesskey=accesskey, secretkey=secretkey),
'Content-type': 'application/json',
'Accept': 'text/plain'}
respon = requests.get(url, headers=header, verify=False)
# 请求成功,则返回结果,否则返回空值
if respon.status_code == 200:
result = json.loads(respon.text)
return result二、开始一次扫描
1、定位扫描任务
发起扫描的API接口为:
POST /scans/{scan_id}/launch
可以看到,进行扫描需要提供一个scan_id。如何获取scan_id呢?
这里给大家分享一种利用任务名获取scan_id的方法。
首先,利用接口/scans接口获取一个所有任务的列表,可以参看刚才的get_scans_list()函数,这里就不重复了,让我们看一下它的返回值,可以看到返回值中有一个sacns的字典列表, 里面有name和id这两个字段
{
"folders": [
folder Resource
],
"scans": [
{
"id": {integer},
…
"name": {string},
…
}
],
"timestamp": {integer}
}注:scans列表中大部分内容我都隐去了,具体的内容大家可以参看:
https://localhost:8834/api#/resources/scans/list:
接下来我们首先确定任务名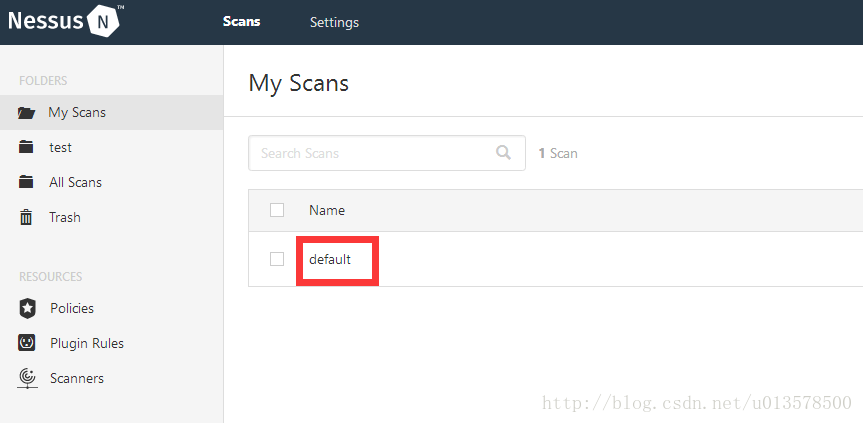
然后遍历任务列表,获取指定任务的ID,代码如下:
def get_scan_id(scanname):
# 任务ID
scan_id = 0
# 获取任务列表
scans_list = get_scans_list()['scans']
if scans_list != '':
# 遍历任务列表
for scan in scans_list:
# 判断是否是指定的任务
if scan['name'] == scanname:
scan_id = scan['id']
break
# 如果未找到,则返回0
return scan_id由于不同的文件夹下允许存在同名的任务,所以为了更精确的定位任务,也可以加入folder_id来查询,调用接口/scan时加入查询字符串folder_id=3即可。folder_id也可以用和scan_id相同的方法获取,大家可以自己试一下。
2、发起任务
有了scan_id,我们就可以使用/scans/{scan_id}/launch接口来发起一个任务了。
另外这个接口需要用POST方法调用,扫描的目标需要放在请求的payload里。代码如下:
# iplist为扫描目标IP的列表
def scan_luanch(iplist):
# header信息在全局变量中,之后的实例中将不再重复
# 调用/scans/{scan_id}/launch
url = 'https://localhost:8834/scans/{scan_id}/launch'.format(scan_id=get_scan_id('default'))
# 扫描目标放在请求的payload里
data = {
'alt_targets': iplist
}
# 发送请求
respon = requests.post(url, headers=header, data=data, verify=False)
# 是否请求成功
if respon.status_code == 200:
return True
else:
return False我们可以调用一下scan_launch()看看效果
scan_luanch(['1.1.1.0', '1.1.1.1'])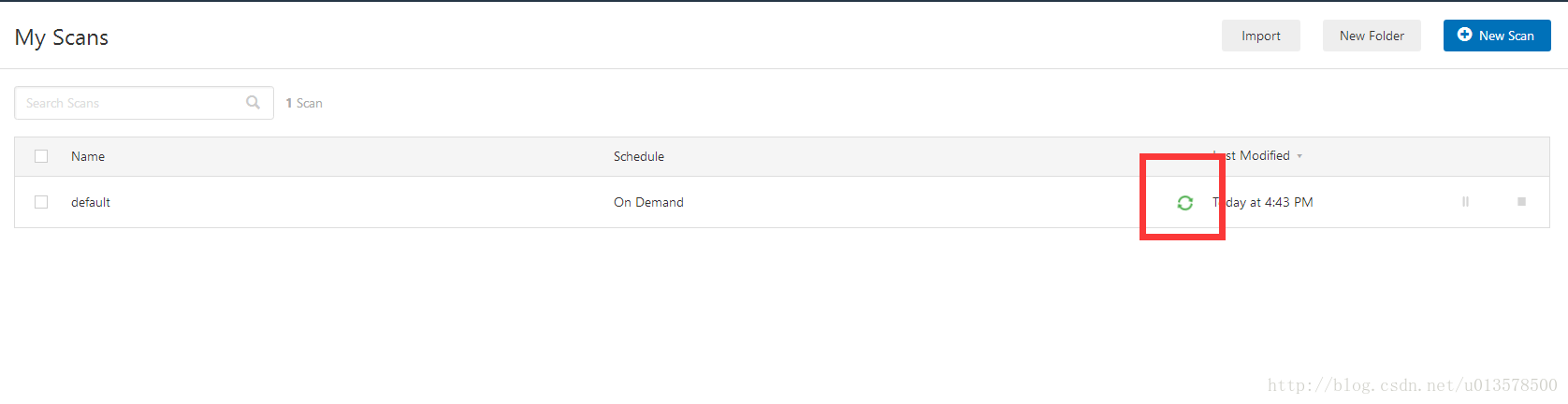
可以看到我们已经成功的发起了一次任务了。
至此我们就完成了登录和发起任务的工作,之后还有许多内容可以完善,例如监听任务状态,获取任务结果,以及动态创建任务等,将在后续的文章中为大家分享。
本文转自 https://blog.csdn.net/u013578500/article/details/78702532,如有侵权,请联系删除。












