
初步认识Java8
需求: 给定一个字符串列表:
["1","2","bilibili","of","xiaoming","5","at","BILIBILI","xiaoming","23","CHEERS","6"]找出所有长度>=5的字符串,并且忽略大小写、去除重复字符串,然后按字母排序,最后用“❤”连接成一个字符串输出!
思路: 1、首先判断输入字符是字母还是数字 2、遍历字符串存入Set集合去重,同时进行大小写转换、长度判断 3、遍历用“❤”拼接结果字符串
方法:使用Java8的Stream流式操作:
public class Test1 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("bilibili");
list.add("of");
list.add("xiaoming");
list.add("5");
list.add("at");
list.add("BILIBILI");
list.add("23");
list.add("CHEERS");
String result = list.stream()
.filter(i -> !isNum(i))
.filter(i -> i.length() >= 5)
.map(i -> i.toLowerCase())
.distinct()
.sorted(Comparator.naturalOrder())
.collect(Collectors.joining("❤"));
System.out.println(result);
}
private static boolean isNum(String str) {
for (int i = 0; i < str.length(); i++) {
if (!Character.isDigit(str.charAt(i))){
return false;
}
}
return true;
}
}阅读书籍《Java8函数式编程》
1. Lambda表达式
1.1 辨别Lambda表达式
public class Test01 {
public static void main(String[] args) {
Button button = new Button();
// 给Button注册一个事件监听器
button.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
System.out.println("button clicked");
}
});
// 1、实现了actionPerformed方法
button.addActionListener(e -> System.out.println("button clicked!"));
// 2、无参,实现了Runnable接口,重写了内部run()方法
Runnable noArguments = () -> System.out.println("Hello World");
// 3、一个参数,和1一样
ActionListener oneArguments = e -> System.out.println("button clicked");
// 4、Lambda表达式的主体还可以是一段代码块
Runnable multiStatement = () -> {
System.out.println("Hello");
System.out.println("World");
};
// 5、变量 add 的类型是 BinaryOperator<Long>, 它不是两个数字的和,而是将两个数字相加的那行代码。
BinaryOperator<Long> add = (x, y) -> x + y;
// 6、上述所有Lambda表达式中的参数类型都是依赖于上下文环境由编译器推断得出的,也可以使用()显式声明参数类型
BinaryOperator<Long> addExplicit = (Long x, Long y) -> x + y;
}
}1.2 引用值,而不是变量
Lambda表达式中引用的局部变量必须是final或既成事实上的final变量,否则编译器会报错,其中既成事实上的final是指只能给该变量赋值一次。
// 正确引用:
String name = getUserName();
button.addActionListener(e -> {System.out.println("hi " + name)});
// 试图给该变量多次赋值,然后在Lambda表达式中引用它,编译器就会报错
// 并显示出错信息: local variables referenced from a Lambda expression must be final or effectively final
String name = getUserName();
name = formatUserName(name);
button.addActionListener(event -> System.out.println("hi " + name));1.3 函数接口
定义:函数接口是只有一个抽象方法的接口,用作Lambda表达式的类型。
例如:
public interface ActionListener extends EventListener {
/**
* Invoked when an action occurs.
*/
// 由于actionPerformed定义在一个接口里,因此 abstract 关键字不是必需的
public void actionPerformed(ActionEvent e);
}Java中重要的函数接口:
|接口|参数|返回类型|示例|
|-|-|-|-|
|Predicate
1.4 类型推断
Lambda表达式中的类型推断,实际上是Java 7中就引入的目标类型推断的扩展。
Java 7中的菱形操作符:
Map<String, Integer> map1 = new HashMap<String, Integer>();
Map<String, Integer> map2 = new HashMap<>();Java 8中的类型推断:
Predicate<Integer> atLeast5 = x -> x > 5;
// 源码:
public interface Predicate<T> {
boolean test(T t);
}
BinaryOperator<Long> addLongs = (x,y) -> x + y;
BinaryOperator add = (x, y) -> x + y; // 编译错误,无法判定类型2. Stream流
2.1 从外部迭代到内部迭代
例子:使用for循环计算来自伦敦的艺术家人数
int count = 0;
for(Artist artist : allArtists){
if(artist.isFrom("London")){
count++;
}
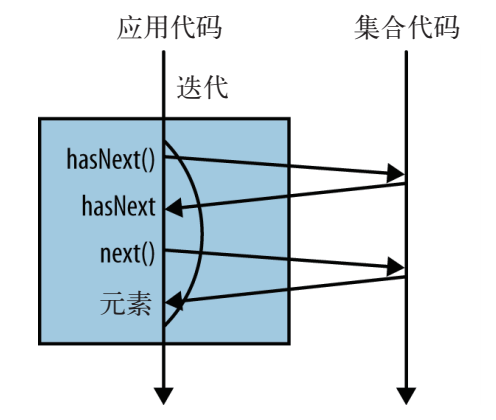
}for循环本质上是一个封装了迭代的语法糖,其工作原理如下:首先调用iterator方法,产生一个新的Iterator对象,进而控制整个迭代过程,即外部迭代。迭代过程通过显式调用 Iterator 对象的 hasNext 和 next方法完成迭代。
int count = 0;
Iterator<Artist> iterator = allArtists.iterator();
while(iterator.hasNext()){
Artist artist = iterator.next();
if(artist.isFrom("London")){
count++;
}
}
内部迭代: 首先调用stream()方法,返回内部迭代中的相应接口:Stream
long count = allArtists.stream()
.filter(artist -> artist.isFrom("London"))
.count();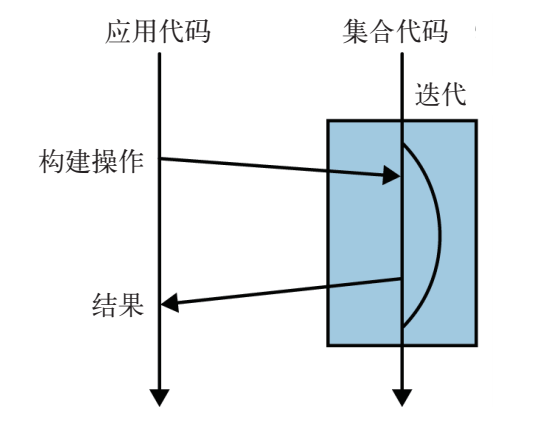
::: warning Stream是用函数式编程方式在集合类上进行复杂操作的工具。 :::
2.2 实现机制
惰性求值:返回值是Stream 及早求值:返回值是另一个值或空
// 该行码中并未做什么实际性的工作, filter只刻画出了Stream,但没有产生新的集合
allArtists.stream()
.filter(artist -> artist.isFrom("London"));2.3 常用的流操作
| 流操作 | 解释 |
|---|---|
| collect(toList()) | 由 Stream 里的值生成一个列表, 是一个及早求值操作。 |
| map | 将一个流中的值转换成一个新的流 |
| filter | 遍历数据并检查其中的元素时使用 |
| flatMap | 用Stream替换值,然后将多个Stream连接成一个Stream |
| max & min | 求流中的最大值和最小值 |
| 通用模式 | |
| reduce | 可以实现从一组值中生成一个值 |
| 整合操作 | 结合多个流操作 |
| ```java | |
| public class Test01 { | |
| public static void main(String[] args) { | |
| // of:将一组初始值生成新的Stream | |
| // collect:将Stream中的值生成一个列表 | |
| List |
|
| Assert.assertEquals(Arrays.asList("a", "b", "c"), list1); |
// map:将字符转换为大写形式
List<String> list2 = Stream.of("a", "b", "helloWorld")
.map(str -> str.toUpperCase())
.collect(toList());
Assert.assertEquals(Arrays.asList("A","B","HELLOWORLD"), list2);
// filter:找出以数字开头的字符串
List<String> list3 = Stream.of("1abc", "abc")
.filter(str -> Character.isDigit(str.charAt(0)))
.collect(toList());
Assert.assertEquals(Arrays.asList("1abc"), list3);
// flatMap:将多个Stream流连接成一个Stream流
List<Integer> list4 = Stream.of(Arrays.asList(1, 2), Arrays.asList(3, 4))
.flatMap(numbers -> numbers.stream())
.collect(toList());
Assert.assertEquals(Arrays.asList(1,2,3,4), list4);
// min:找出最短的字符串
String res1 = Stream.of("a", "ab", "abc")
.min(Comparator.comparing(str -> str.length()))
.get();
Assert.assertEquals("a" , res1);
// max:找出最长的字符串
String res2 = Stream.of("a", "ab", "abc")
.max(Comparator.comparing(str -> str.length()))
.get();
Assert.assertEquals("abc" , res2);
// reduce:实现累加求和
// 0 :初始值
// acc :累加器
// element:当前元素
int count1 = Stream.of(1,2,3)
.reduce(0, (acc, element) -> acc + element);
Assert.assertEquals(6, count1);
// 展开reduce操作
BinaryOperator<Integer> accumulator = (acc, element) -> acc + element;
int count2 = accumulator.apply(accumulator.apply(accumulator.apply(0, 1), 2), 3);
Assert.assertEquals(6, count2);
}
// 计算字符串中小写字母的个数
public static int countLowerCaseLetters(String string){
return (int) string.chars()
.filter(Character::isLowerCase)
.count();
}
// 在一个字符串列表中,找出包含最多小写字母的字符串。对于空列表,返回Optional<String>对象。
public static Optional<String> mostLowerCaseString(List<String> strings){
return strings.stream()
.max(Comparator.comparingInt(Test01::countLowerCaseLetters));
}}
## 2.4 链式调用
例:找出专辑上所有演出乐队的国籍
```java
Set<String> origins = album.getMusicians()
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.collect(toSet());2.5 高阶函数
定义:如果函数的参数列表里包含函数接口,或该函数返回一个函数接口,那么该函数就是高阶函数。 例如:map 是一个高阶函数, 因为它的 mapper 参数是一个函数。
2.6 总结
- 内部迭代将更多控制权交给了集合类。
- 和 Iterator 类似, Stream 是一种内部迭代方式。
- 将 Lambda 表达式和 Stream 上的方法结合起来, 可以完成很多常见的集合操作。
3. 类库
...
4. 高级集合类和收集器
4.1 方法引用
Lambda表达式经常调用参数,例如:artist -> artist.getName() Java 8为其提供了一个简写语法,叫作方法引用,例如:Artist::getName 标准语法为 Classname::methodName 凡是使用 Lambda 表达式的地方, 就可以使用方法引用
4.2 元素顺序
直观上看, 流是有序的, 因为流中的元素都是按顺序处理的。 这种顺序称为出现顺序。
List<Integer> numbers = asList(1, 2, 3, 4);
List<Integer> sameOrder = numbers.stream()
.collect(toList());
Assert.assertEquals(numbers, sameOrder);如果集合本身就是无序的, 由此生成的流也是无序的。 HashSet 就是一种无序的集合,下面程序不一定每次都通过
Set<Integer> numbers = new HashSet<>(asList(4, 3, 2, 1));
List<Integer> sameOrder = numbers.stream()
.collect(toList());
// 该断言有时会失败
Assert.assertEquals(asList(4, 3, 2, 1), sameOrder);一些中间操作会产生顺序, 比如对值做映射时, 映射后的值是有序的
Set<Integer> numbers = new HashSet<>(asList(4, 3, 2, 1));
List<Integer> sameOrder = numbers.stream()
.sorted()
.collect(toList());
assertEquals(asList(1, 2, 3, 4), sameOrder);一些操作在有序的流上开销更大, 调用 unordered 方法消除这种顺序就能解决该问题。 大多数操作都是在有序流上效率更高, 比如 filter、 map 和 reduce 等。
4.3 收集器
定义:一种通用的、 从流生成复杂值的结构。 只要将它传给 collect 方法, 所有的流就都可以使用它了。
4.3.1 转换成其他集合
使用toCollection,用定制的集合收集元素
stream.collect(toCollection(TreeSet::new));4.3.2 转换成值
maxBy 和 minBy 允许用户按某种特定的顺序生成一个值。
// 找出成员最多的乐队
public Optional<Artist> biggestGroup(Stream<Artist> artists){
Function<Artists, Long> getCount = artist -> artist.getMembers().count();
return artists.collect(maxBy(comparing(getCount)));
}有些收集器实现了一些常用的数值运算
// 找出一组专辑上曲目的平均值
public double averageNumberOfTracks(List<Alum> albums){
return albums.stream()
.collect(averagingInt(album -> album.getTrackList().size()));
}4.3.3 数据分块
收集器 partitioningBy, 它接受一个流, 并将其分成两部分。
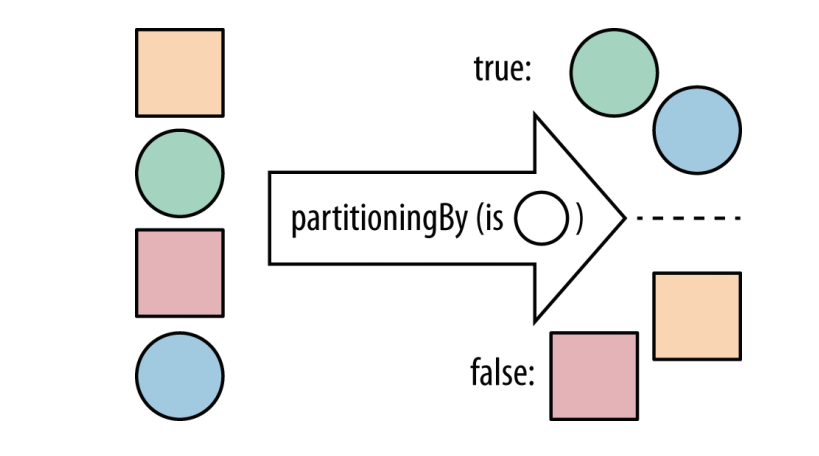
// 假设有一个艺术家组成的流, 你可能希望将其分成两个部分,
// 一部分是独唱歌手, 另一部分是由多人组成的乐队。
public Map<Boolean, List<Artist>> bandsAndSolo(Stream<Artist> artists){
rerurn artists.collect(partitioningBy(artist -> artist.isSolo()));
// 方法引用
// rerurn artists.collect(partitioningBy(Artist::isSolo));
}4.3.4 数据分组
groupingBy 收集器,接受一个分类函数,用来对数据分组,就像 partitioningBy一样,接受一个Predicate 对象将数据分成 ture 和 false 两部分。

// 现在有一个由专辑组成的流, 可以按专辑当中的主唱对专辑分组
public Map<Artist, List<Album>> albumsByArtist(Stream<Album> albums){
return albums.collect(groupingBy(album -> album.getMainMusician()));
}4.3.5 字符串
Collectors.joining 收集流中的值,该方法可以方便地从一个流得到一个字符串,允许用户提供分隔符( 用以分隔元素)、前缀和后缀。
// 格式化艺术家姓名
String result = artists.stream()
.map(Artist::getName)
.collect(Collectors.joining(",","[","]"));4.3.6 组合收集器
groupingBy + countin收集器
// 计算每个艺术家的专辑数量:
// 1、groupingBy先将元素分组,每块都与分类函数 getMainMusician 提供的键值相关联
// 2、然后使用下游的另一个收集器收集每块中的元素
// 3、最后将结果映射为一个 Map。
public Map<Artist, Long> numberOfAlbums(Stream<Album> albums){
return albums.collect(groupingBy(album -> album.getMainMusician(), counting()));
}groupingBy + mapping收集器
// 计算每个艺术家的专辑名
public Map<Artist, List<String>> nameOfAlbums(Stream<Album> albums){
return albums.collect(groupingBy(Album::getMainMusician,
mapping(Album::getName, toList())));
}4.3.7 重构和定制收集器
...
4.4 其他细节
Lambda 表达式的引入也推动了一些新方法被加入集合类,例如Map:
构建 Map 时, 为给定值计算键值是常用的操作之一,一个经典的例子就是实现一个缓存。 传统的处理方式是先试着从 Map 中取值, 如果没有取到, 创建一个新值并返回。
假设使用 Map<String, Artist> artistCache 定义缓存, 我们需要使用费时的数据库操作查 询艺术家信息:
// 使用显式判断空值的方式缓存
public Artist getArtist(String name){
Artist artist = artistCache.get(name);
if(artist == null){
artist = readArtistFromDB(name);
artistCache.put(name, artist);
}
return artist;
}
// Java 8新方法:computIfAbsent
// 该方法接受一个 Lambda 表达式, 值不存在时使用该 Lambda 表达式计算新值。
public Artist getArtist(String name){
return artistCache.computeIfAbsent(name, this::readArtistFromDB(name));
}迭代Map
// 普通迭代遍历Map,代码冗余
Map<Artist, Integer> countOfAlbums = new HashMap<>();
for(Map.Entry<Artist, List<Album>> entry : albumsByArtist.entrySet()){
Artist artist = entry.getKey();
List<Album> albums = entry.getValue();
countOfAlbums.put(artist, albums.size());
}
// Java 8内部迭代遍历Map
Map<Artist, Integer> countOfAlbums = new HashMap<>();
albumsByArtist.forEach((artist, albums) -> {
countOfAlbums .put(artist, albums.size());
});5. 数据并行化
5.1 并行和并发
并行:两(多)个任务在同一时间发生
并发:两(多)个任务共享时间段
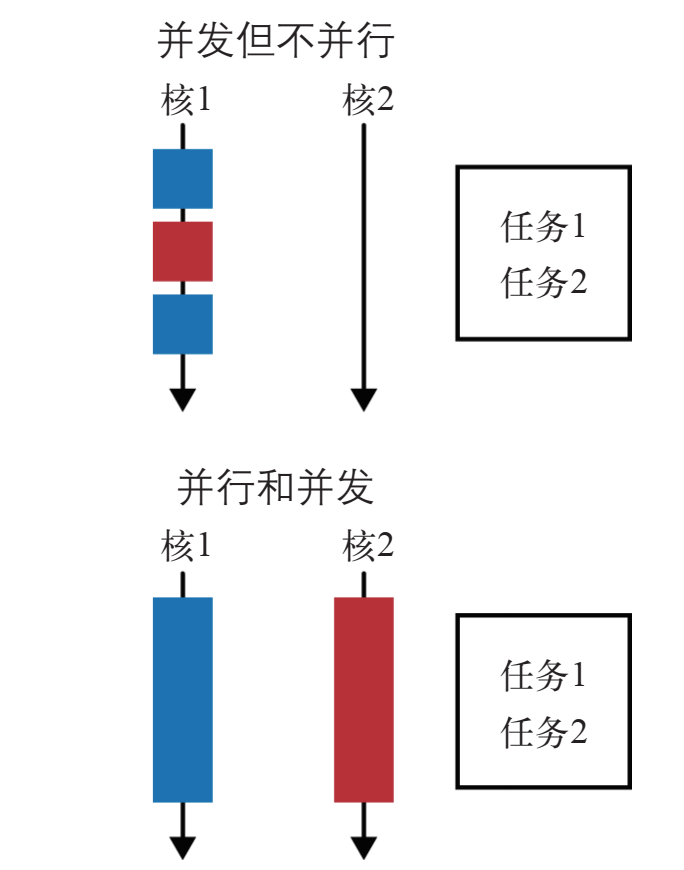
5.2 并行化流操作
- 如果已经有一个Stream对 象,调用它的parallel方法就能让其拥有并行操作的能力。
- 如果想从一个集合类创建一个流,调用parallelStream就能立即获得一个拥有并行能力的流。
// 串行化计算专辑曲目长度
public int serialArraySum(){
return albums.stream()
.flatMap(Album::getTracks)
.mapToInt(Track::getLength)
.sum();
// 并行化计算专辑曲目长度
public int serialArraySum(){
return albums.parallelStream()
.flatMap(Album::getTracks)
.mapToInt(Track::getLength)
.sum();
}5.3 限制
为了发挥并行流框架的优势, 写代码时必须遵守一些规则和限制。
限制一: 调用 reduce 方法,初始值可以为任意值,为了让其在并行化时能工作正常,初值必须为组合函数的恒等值。 reduce 操作求和,组合函数为(acc, element) -> acc + element,则其初值必须为 0,因为任何数字加 0,值不变。 reduce 操作求积,组合函数为(acc, element) -> acc * element,则其初值必须为 1,因为任何数字乘 1,值不变。
限制二: reduce 操作的另一个限制是组合操作必须符合结合律。 这意味着只要序列的值不变, 组合操作的顺序不重要。
与 parallel 对应的是 sequential
5.4 性能
使用串行流还是并行化,取决于以下5个主要因素:
- 数据大小:分解数据并行处理后合并会带来额外开销
- 源数据结构:
- 装箱:处理基本类型比处理装箱类型要快
- 核的数量:指运行时机器能使用多少核
- 单元处理开销:花在流中每个元素身上的时间越长,并行操作带来的性能提升越明显
// 并行求和
private int addIntegers(List<Integer> values) {
return values.parallelStream()
.mapToInt(i -> i)
.sum();
}在底层,并行流还是沿用了fork/join框架。 fork递归式地分解问题,然后每段并行执行,最终由 join 合并结果,返回最后的值。
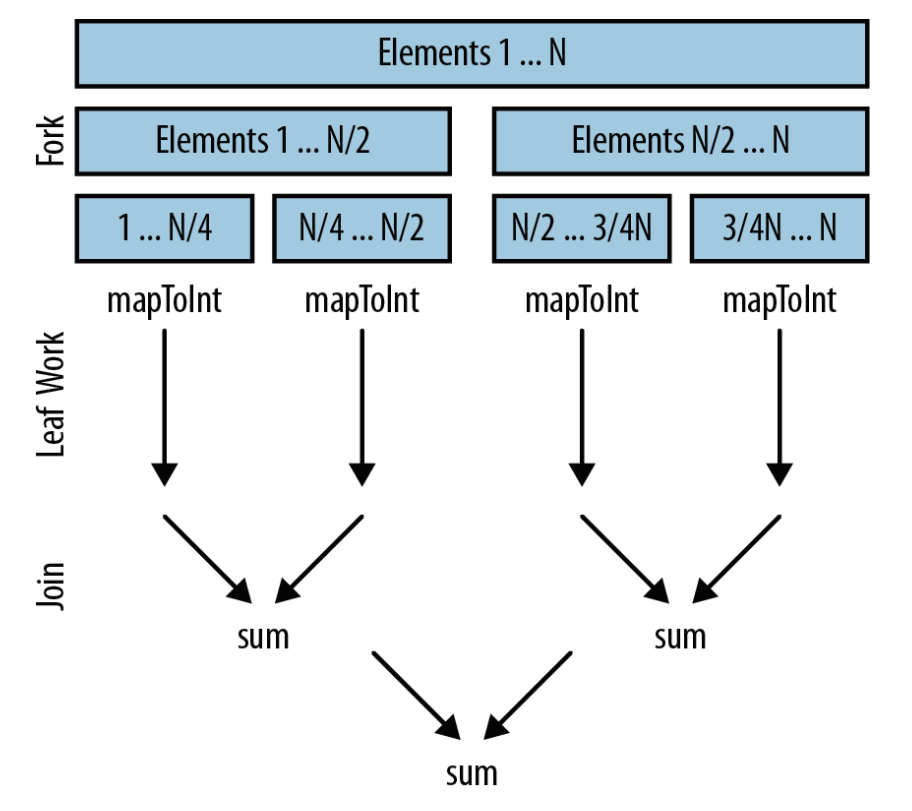 根据问题的分解方式, 初始的数据源的特性变得尤其重要, 它影响了分解的性能。
根据性能的好坏, 将核心类库提供的通用数据结构分成以下 3 组:
根据问题的分解方式, 初始的数据源的特性变得尤其重要, 它影响了分解的性能。
根据性能的好坏, 将核心类库提供的通用数据结构分成以下 3 组:
- 性能好
- 类似ArrayList、 数组或 IntStream.range数据结构支持随机读取,能轻而易举地被任意分解。
- 性能一般
- HashSet、TreeSet,这些数据结构不易公平地被分解
- 性能差
- LinkedList、Streams.iterate 和 BufferedReader.lines难于分解
在讨论流中单独操作每一块的种类时, 可以分成两种不同的操作: 无状态的和有状态的。
- 无状态操作整个过程中不必维护状态,
- map、filter 和 flatMap
- 有状态操作则有维护状态所需的开销和限制。
- sorted、 distinct 和 limit
5.5 并行化数组操作
|方法名|操作| |-|-|-| |parallelPrefix|任意给定一个函数, 计算数组的和| |parallelSetAll|使用 Lambda 表达式更新数组元素| |parallelSort|并行化对数组元素排序|
parallelPrefix操作擅长对时间序列数据做累加,它会更新一个数组,将每一个元素替换为当前元素和其前驱元素的和,这里的“ 和” 是一个宽泛的概念,它不必是加法,可以是任意一个 BinaryOperator
// 计算简单滑动平均数(n为滑动窗口的大小)
public static double[] simpleMovingAverage(double[] values, int n){
// 并行操作会改变原有数组内容,为不修改原有数据,复制一份
double[] sums= Arrays.copyOf(values, values.length);
Arrays.parallelPrefix(sums, Double::sum);
int start = n - 1;
return IntStream.range(start, sums.length)
.mapToDouble(i -> {
double prefix = i == start ? 0 : sums[i-n];
return (sums[i] - prefix) / n;
})
.toArray();
}// 使用并行化数组操作初始化数组(改变了传入的数组,没有创建一个新的数组)
public static double[] parallelInitialize(int size){
double[] values = new double[size];
Arrays.parallelSetAll(values, i -> i);
return values;
}Double[] values = new Double[]{3.0,1.0,2.0};
Arrays.parallelSort(values, ((o1, o2) -> (int) (o2 - o1)));6. 测试、调式和重构
6.1 Lambda表达式的单元测试
通常,在编写单元测试时,怎么在应用中调用该方法,就怎么在测试中调用。给定一些输入或测试替身,调用这些方法,然后验证结果是否和预期的行为一致。
局限性:因为Lambda 表达式没有名字,无法直接在测试代码中调用。 解决: 1、将Lambda表达式放入一个方法测试,这种方式要测那个方法,而不是Lambda表达式本身
// 将字符串转换为大写形式
public static List<String> allToUpperCase(List<String> words){
return words.stream()
.map(string -> string.toUpperCase())
.collect(Collectors.<String>toList());
}
// 测试大写转换
@Test
public void multiWordsToUppercase(){
List<String> input = Arrays.toList("a","b","hello");
List<String> result = Testing.allToUpperCase(input);
Assert.assertEquals(asList("A", "B","HELLO"), result);
}// 将列表中元素的第一个字母转换成大写
public static List<String> elementFirstToUpperCaseLambdas(List<String> words){
return words.stream()
.map(word -> {
char firstChar = Character.toUpperCase(word.charAt(0));
return firstChar + word.substring(1);
})
.collect(Collector.<String>toList());
}
// 测试,这样测试必须创建一个列表,将所有可能的边界情况考虑到,太繁琐了!
@Test
public void twoLetterStringConvertedToUppercaseLambdas() {
List<String> input = Arrays.asList("ab");
List<String> result = Testing.elementFirstToUpperCaseLambdas(input);
assertEquals(asList("Ab"), result);
}
// 解决:将Lambda表达式改写成普通方法,在流操作中使用引用
public static List<String> elementFirstToUppercase(List<String> words) {
return words.stream()
.map(Testing::firstToUppercase)
.collect(Collectors.<String>toList());
}
public static String firstToUppercase(String value) {
char firstChar = Character.toUpperCase(value.charAt(0));
return firstChar + value.substring(1);
}
// 测试单独的方法
@Test
public void twoLetterStringConvertedToUppercase() {
String input = "ab";
String result = Testing.firstToUppercase(input);
Assert.assertEquals("Ab", result);
}6.2 在测试替身时使用Lambda表达式
测试代码时, 使用 Lambda 表达式的最简单方式是实现轻量级的测试存根。 对于countFeature方法的期望行为是为传入的专辑返回某个数值。这里传入 4 张专辑, 测试存根中为每张专辑返回 2,然后断言该方法返回 8,即 2× 4。如果要向代码传入一个Lambda 表达式,最好确保 Lambda 表达式也通过测试。
// 使用 Lambda 表达式编写测试替身, 传给 countFeature 方法
@Test
public void canCountFeatures() {
OrderDomain order = new OrderDomain(asList(
newAlbum("Exile on Main St."),
newAlbum("Beggars Banquet"),
newAlbum("Aftermath"),
newAlbum("Let it Bleed")));
Assert.assertEquals(8, order.countFeature(album -> 2));
}多数的测试替身都很复杂,使用Mockito这样的框架有助于更容易地产生测试替身。 让我们考虑一种简单情形,为List生成测试替身。我们不想返回List本上的长度,而是返回另一个 List 的长度,为了模拟 List 的 size 方法 我们不想只给出答案, 还想做一些操作, 因此传入一个 Lambda 表达式:
// 结合 Mockito 框架使用 Lambda 表达式
List<String> list = mock(List.class);
when(list.size()).thenAnswer(inv -> otherList.size());
Assert.assertEquals(3, list.size());6.3 日志和打印消息
以“找出专辑上每位艺术家来自哪个国家”为例
for循环打印中间值
Set<String> nationalities = new HashSet<>();
for(Artist artist : album.getMusicianList()){
if(artist.getName().startWith("The")){
String nationality = artist.getNationality();
System.out.println("Found nationality :" + nationality);
nationalities.add(nationality);
}
}可以使用 forEach 方法打印出流中的值,这同时会触发求值过程。但是这样的操作有个缺点:我们无法再继续操作流了,流只能使用一次。如果我们还想继续,必须重新创建流。
album.getMusicians()
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.forEach(nationality -> System.out.println("Found: " + nationality));
Set<String> nationalities
album.getMusicians()
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.collect(Collectors.<String>toSet());解决办法:peek能查看每个值,同时能继续操作流
// 使用 peek 方法记录中间值
Set<String> nationalities
album.getMusicians()
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.peek(nation -> System.out.println("Found nationality: " + nation))
.collect(Collectors.<String>toSet());使用 peek 方法还能以同样的方式,将输出定向到现有的日志系统中,比如 log4j、java.util.logging 或者 slf4j。
7. 设计和架构的原则
7.1 Lambda表达式改变了设计模式
7.2 使用Lambda表达式的SOLID原则
SOLID原则:
- Single responsibility
- Open/closed
- Liskov substitution
- Interface segregation
- Dependency inversion
7.2.1 单一功能原则
程序中的类或方法只能有一个改变的理由。
// 计算质数个数, 一个方法里塞进了多重职责
public long countPrimes(int upTo){
long tally = 0;
for(int i = 1; i < upTo; i++){
boolean isPrime = true;
for(int j = 2; j < i; j++){
if(i % j == 0){
isPrime == false;
}
}
if(isPrime){
tally++;
}
}
return tally;
}// 将 isPrime 重构成另外一个方法后, 计算质数个数的方法
public long countPrimes(int upTo) {
long tally = 0;
for (int i = 1; i < upTo; i++) {
if (isPrime(i)) {
tally++;
}
}
return tally;
}
private boolean isPrime(int number) {
for (int i = 2; i < number; i++) {
if (number % i == 0) {
return false;
}
}
return true;
}// 使用 Java 8 的集合流重构上述代码
public long countPrimes(int upTo){
return IntStream.range(1, upTo)
.filter(this::isPrime)
.count();
}
public boolean isPrime(int number){
return IntStream.range(2, number)
.allMatch(x -> (number % x) != 0);
}// 并行流处理
public long countPrimes(int upTo){
return IntStream.range(1, upTo)
.parallel()
.filter(this::isPrime)
.count();
}
public boolean isPrime(int number){
return IntStream.range(2, number)
.allMatch(x -> (number % x) != 0);
}7.2.2 开闭原则
软件应该对扩展开放,对修改闭合。 借助于抽象实现!
例:我们有描述计算机花在用户空间、 内核空间和输入输出上的时间散点图。 我将负责显示这些指标的类叫作 MetricDataGraph
class MetricDataGraph {
public void updateUserTime(int value);
public void updateSystemTime(int value);
public void updateIoTime(int value);
}如果添加新的时间点,需要修改MetricDataGraph类,这里新建一个“时间点”的抽象类TimeSeries接口
public interface TimeSeries{
}每种时间点都实现这个抽象类
public class UserTimeSeries implments TimeSeries{
...
}
public class SystemTimeSeries implments TimeSeries{
...
}
public class IoTimeSeries implments TimeSeries{
...
}
// 新增时间点
public class StealTimeSeries implments TimeSeries{
...
}// 重构
class MetricDataGraph {
public void addTimeSeries(TimeSeries values);
}对于高阶函数,比如 ThreadLocal 有一个特殊的变量, 每个线程都有一个该变量的副本并与之交互。 该类的静态方法 withInitial 是一个高阶函数, 传入一个负责生成初始值的Lambda 表达式。
// ThreadLocal 日期格式化器
// 实现
ThreadLocal<DateFormat> localFormatter
= ThradLocal.withInitial(() -> new SimpleDateFormat());
// 使用
DateFomat formatter = localFormatter.get();通过传入不同的 Lambda 表达式, 可以得到完全不同的行为。
// ThreadLocal 标识符
// 实现
AtomicInteger threadId = new AtomicInteger();
ThreadLocal<Integer> localId
= ThreadLocal.withInitial(() - > threadId.getAndIncrement());
// 使用
int idForThisThread = localId.get();对开闭原则的另外一种理解和传统的思维不同, 那就是使用 不可变对象 实现开闭原则
不可变性:
- 观测不可变:指在其他对象看来, 该类是不可变的
- 实现不可变:指对象本身不可变
java.lang.String 宣称是不可变的,但事实上只是观测不可变,因为它在第一次调用hashCode 方法时缓存了生成的散列值。在其他类看来,这是完全安全的,它们看不出散列值是每次在构造函数中计算出来的,还是从缓存中返回的。
7.2.3 依赖反转原则
抽象不应依赖细节, 细节应该依赖抽象。 ...
8. 使用Lambda表达式编写并发程序
待更新...









