作者:京东零售 刘慧卿
一 前言
关于软件的高可用,是一个老生常谈的话题。“高可用性”(High Availability)通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性。其计算公式是:可用率=(总时间-不可用时间)/总时间。
本文重点从落地实践的视角作为切入点,带领大家从协作效率,技术落地和运营规范几个方面来展现高可用的实施步骤和落地细节。为了方便理解,先来统一语言话术,看一下软件交付过程中的各个阶段,如下图:
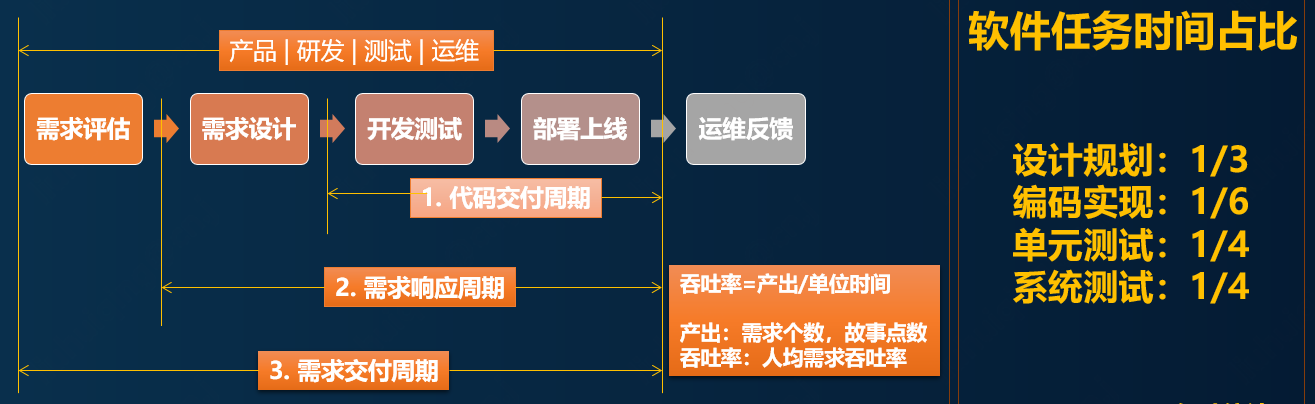
为什么说软件的高可用会面临着诸多挑战呢?
◦ 从需求交付链路来看,要完成目标交付,需要产品,研发,测试,运维,运营等多方利益相关者的密切配合。有些项目需求,合作者有时能够达到上百人,每个人职责分工各不相同,但却相互配合依赖,任何一个环节出现纰漏,可用率就有可能受到影响;
◦ 从时间角度来看,如果要达到全年99.99%的可用率,就意味着一年当中,允许有故障的时间为:365*24*60*(100%-99.99%)=52分钟,如果要达到5个9的可用率,允许故障的时间仅为5分钟,这差不多是我们发现问题后,重启应用的耗时;
◦ 从迭代效率来看,不迭代,不上线,问题出现的概率一定会小很多。软件的迭代效率和可用率之间存在着负相关的关系,平衡好两者之间的关系,也会面临着不小的挑战。
总结一下,我们具体面临的问题如下:
◦ 如何解决需求交付相关协作者多,链路长的问题?
◦ 如何应对故障时间容忍度低的问题?
◦ 如何在频繁需求迭代的现状下,保持可用率不受到大的冲击问题?
二 协作效率保障
认知误区
从整个需求交付链路我们可以发现,随着链路的逐级递增,信息的传递链路分支就会越多,传递层级就会越深。这会导致两个问题:
信息传递效率降低;
信息准确性变差。
这两个问题最终导致的结果,就是协作效率的降低。
一个没有实战经验的同学往往会认为增加人数,就会提高需求交付效率。其实这种想法不完全正确,具体关系参考下图:
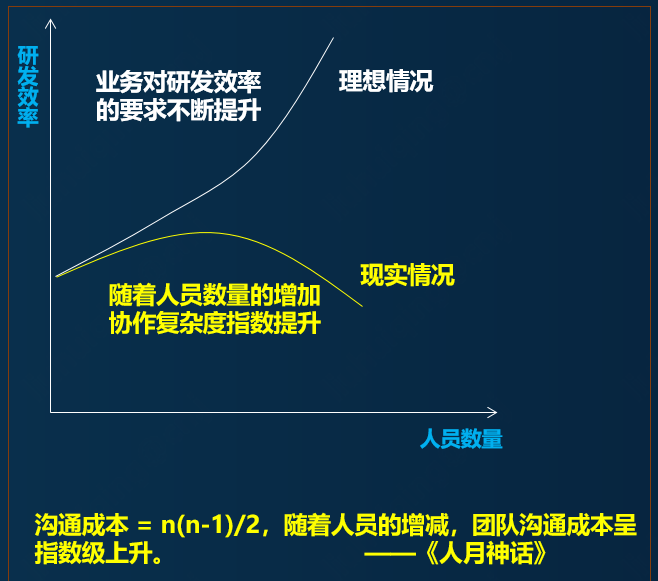
这就像盖楼房,如果一个人按部就班的建设,需要100天完成。如果请了100个人来帮忙,能否用1天的时间完成房子建设呢?答案是否定的。
这里面有协作的成本,比如:团队默契(设计师,瓦工,泥工,水电工),岗位匹配,风险控制;
这里面有流程的依赖,比如:施工依赖于设计,软装总在硬装之后;
这里面有成本预算,比如:整个组织的人才梯度,规模大小(承建方,代理商,承包商);
以上这些,都不是简单的通过人力铺设来解决的。
流程规范
提高协作效率的底层逻辑是通过减少交付链路层级,缩短信息传递链路,进而保证信息的准确性和传递效率。(组织建设层面的内容这里不做展开)
这就要求具有今日事,今日毕的行动力。组织层面这叫流程规范,个人层面这叫做事方法,责任心。
尽量避免将当下的事情拖延到下一个环节,否则就会影响后续链路的排期计划和交付效率,极端情况甚至会出现返工的情形。简言之,考虑清楚,不埋坑。产品需求对研发,研发设计对测试,测试用例对产品等各个交付节点都是如此,交付物一定是靠谱的。
三 技术落地保障
在需求响应周期中,高质量的落实架构设计,编码实现,安全上线,部署运营等生产阶段,是软件高可用落地保障的前提和基础。
架构设计
架构设计往往影响着系统的前期实现成本(即ROI)和后续运维难度,属于软件的顶层设计,这里面既包含宏观的设计方案,也包含落地细节里的范式约束。
• 流程保障
邀请架构师参与:核心交易节点、重大需求改动邀请架构师参与,这是闭坑最直接有效的方式;
重视设计文档:方案描述清楚了,并取得相关利益者的认可,是走在正确道路上的前提。
• 设计保障
容灾设计:要预留后路,提前想清楚,做好容灾设计。可回滚,可熔断,可重试,可降级。
鲁棒性设计:无状态设计,防重设计,幂等设计,数据一致性设计
编码实现
如果说架构设计是骨架,那么编码实现就是神经,血管和肌肉。前者决定了能走多稳,走多久,后者决定着走多快,走多远。落实到编码层面,就是代码的衰老腐败程度。
• 流程规范
代码评审机制:代码评审不仅仅是发现系统中存在的问题这么简单。它是一种长期行为,是进行组织文化贯彻和传承的一种形式和载体。评审的过程中,明确了业务职责边界,设计与编码共识,优秀的标准导向等研发共识。相当于通过具象化的案例,给出针对性的指导,这些都是保证团队战斗力的基石。
研发过程中的很多问题,通过代码评审机制可以被发现和解决,比如:
◦ 如何对待临时需求的设计与实现?
◦ 如何看待“Hello World!”的N中写法?
◦ 如何理解设计模式和过度设计的边界?
◦ 如何评价当前阶段的交付物?
◦ 是否有必要引入单元测试?
• 编码规范
◦ 有没有对错误进行处理?对于调用的外部服务,是否检查了返回值或处理了异常?
◦ 设计是否遵从已知的设计模式或项目中常用的模式?
◦ 开发者新写的代码能否用已有的SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以调用而不用全部重新实现?
◦ 工程中是否引入了无用的,功能重复的,不同版本的jar包依赖?(json类库,各种utils)
◦ 有没有无用的代码可以清除?
◦ 代码可读性如何?有没有足够的注释?
◦ 参数传递有无错误,有没有使用断言(Assert)或判断来保证我们认为不变的条件真的得到满足?
◦ 边界条件是如何处理的? switch语句的default分支是如何处理的?循环有没有可能出现死循环?
◦ 对资源的利用,是在哪里申请,在哪里释放的?有无可能存在资源泄漏(包括超时时间,内存、文件、对象引用,大对象,线程数等)?有没有优化的空间?
◦ 代码的效能如何?最坏的情况是怎样的?
◦ 代码中,特别是循环中是否有明显可优化的部分(string的操作是否能用StringBuilder来优化)?
◦ 对于系统和网络的调用是否会超时?如何处理?
◦ 代码是否易于测试(方法行数,圈复杂度,出入参定义是否合理)?
◦ 改动是否影响到旧版本、历史数据、上游能否兼容?
◦ 接口设计是否有考虑幂等、并发、越权,降级等问题?
◦ 是否存在缓存、数据库性能问题以及多数据源数据一致性的问题?
◦ 上线方案是否考虑了灰度方案,数据状态不一致问题?
安全上线
线上70%的故障都是由某种变更而触发的,其中相当一部分占比是不规范的上线引起的。所以安全上线这一环节至关重要。
• 流程规范
◦ 严禁频繁上线:比如,每周不大于2次;
◦ 严禁高峰期上线:降低问题影响范围;
◦ 严禁私自上线:有改动,必须通过测试验证,产品回归确认;
• 过程规范
◦ 摘流量:选择第一批机器jsf下线/np摘流量(选为冷备);
◦ 看日志:观察日志确认摘除机器无流量;
◦ 服务预热:确认机器启动成功,核心业务接口需要接口预热;
◦ 挂流量:挂载上线机器流量;
◦ 看指标:观察上线机器mdc指标是否异常(cpu、内存、负载)、日志是否有异常
部署运营
实现高可用的一个很重要的手段就是能力冗余。下面给出方向和思路,具体落地细节和策略,可以根据具体情况各自延展。
• 网络
◦ 运营商层面,联通,电信,移动等;
◦ 链路节点方面,VIP,CDN,路由器/交换机,反向代理,客户端,浏览器等;
• 存储
◦ 无论是数据库主从架构,还是ES的副本架构,都是实现存储高可用的手段,重要数据要利用好相关特性;
◦ 在进行数据结构设计时,同样也需要做好分流策略,容量规划,数据拆分或异构。比如:避免缓存热key,数据库表吞吐量瓶颈,数据库连接数限制等各种影响高可用的问题出现。
• 服务
◦ 横向扩容:服务要保证可以通过添加资源的方式进行能力扩容,这一点非常重要;
◦ 服务分组:按照业务方或使用场景,对服务进行不同粒度的隔离,防止极端情况导致服务相互影响;
◦ 极限策略:主要是一些极端异常情况下的防御策略,目的是意外发生后,尽量保持服务的可靠性。比如:限流,熔断,重试,快速失败等;
◦ 灰度策略:新功能上线,往往是最容易出现问题的时候,拥有成熟的流量灰度能力,是控制问题影响范围的关键;
四 运营规范保障
运营规范
可监控:系统运行状况
可报警:异常情况能够通知到系统相关人员
可定位:出现问题后,能够快速定位问题原因
可修复:出现异常情况,能够在第一时间进行问题修复;
应急预案
高可用意味着对故障时间的容忍性差,意味着没有时间进行故障排查和修复,更没有时间打开代码进行漏洞排查。这就要求我们有一套完备的应急预案,这套预案能够解决大部分可预见的故障问题。
• 流程规范
◦ 恢复生产第一;
◦ 排查问题第二;
详细事故应急处理手册,可以参照下图:
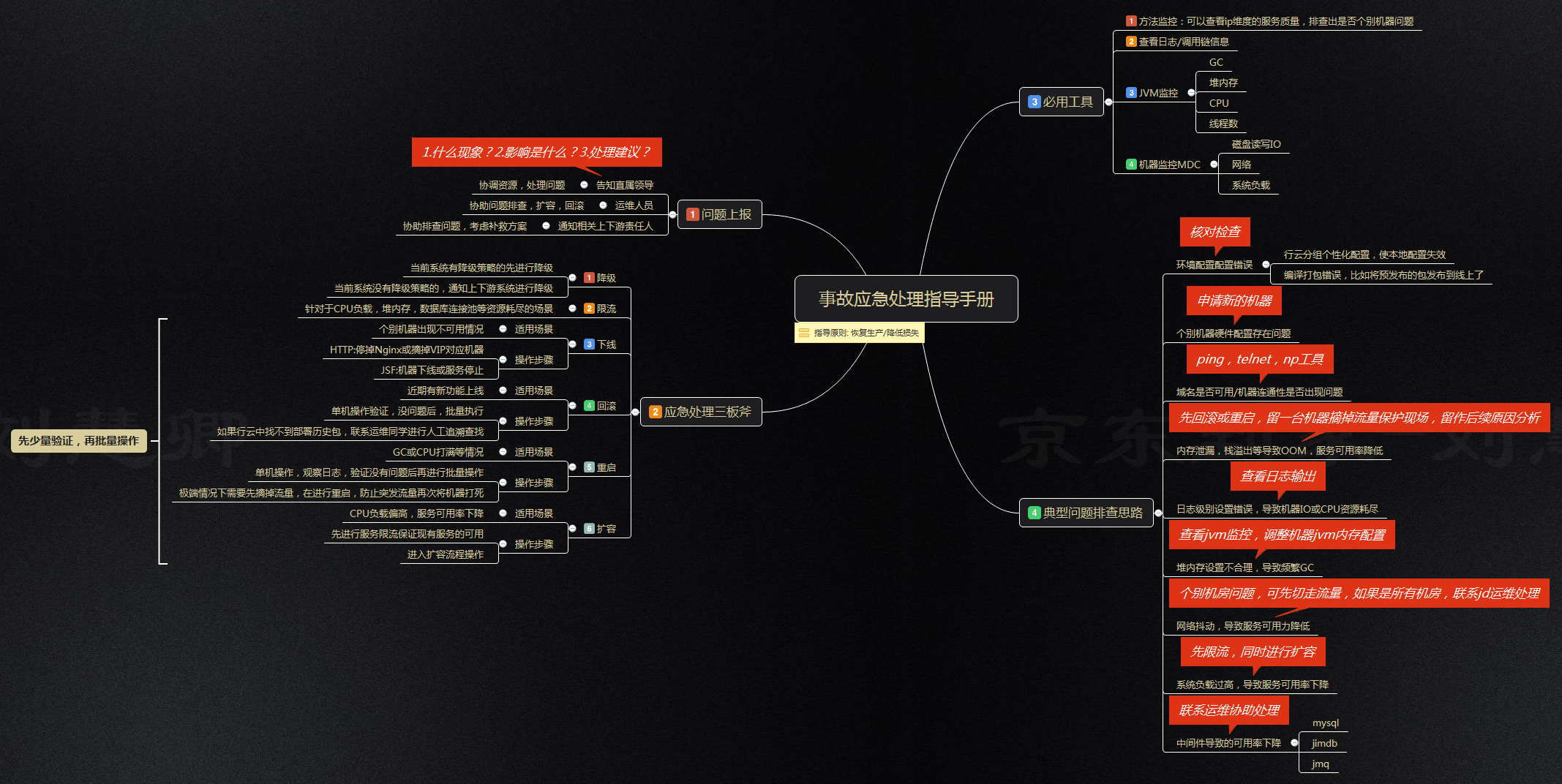
• 过程规范
◦ 网络,服务,存储分三个维度制定对应方案,并将应急预案清单(文件名:checklist)填写到自己的代码库中,保持内容传承和更新;
◦ 可预见性,即问题触发场景要写清楚。举例:按照当前进度(1万/天),随着数据库数据的增加,预计10个月后,数据库表(xxx表名)会出现慢查询;
◦ 可执行性,能够消除问题的解决方案。举例:启动历史数据归档任务(xxxWorker),将历史数据进行转移到归档数据库中;
规范达标
再好的流程和规范都需要有对应的机制来贯彻执行,否则就是镜中花,水中月,看着美好,实则没用。可执行,能度量,是按照目标变好的前提。所以这里给出一个《高可用达标定期自查表》的工具,辅助规范落地。


五 总结
本文从“高可用为什么存在着很大挑战?”的问题展开探讨,强调了需求交付过程中,协作效率的重要性,并指出了为什么要遵从“今日事,今日毕”的工作原则。又从架构设计,编码实现,安全上线,部署运营等几个方面,详细介绍了技术落地保障相关的指导规范和落地细节。最后又从上线后运营的角度,给出了应急预案三板斧,规范达标定期自查表等比较实用的运营保障工具。希望能够给读者带来帮助。