
楔子
你是否想要尝试进行 Node.js 应用开发但是又总听人说它不安全、稳定性差,想在公司推广扩张大前端的能力范畴和影响又说服不了技术领导。
JavaScript 发展到今天,早已脱离原本浏览器的战场,借助于 Node.js 的诞生将其触角伸到了服务端、PC 跨平台客户端方案等各个领域,但是与此同时,JS Runtime 对于绝大部分的开发者来说又一如既往的处于黑盒状态——开发者无法感知其运行状态,出现一些性能、内存问题时也没有很好的工具链进行更深入的支持。
本书将在基于 Node.js 性能平台 的基础上,从多个大家开发上线过程中可能遇到的疑难杂症的视角,观察如何去发现、定位和解决这些问题,帮助读者构建对 Node.js 这门语言的更多信心。
因为本书将属于 Node.js 开发进阶的内容,因此我们希望本书的读者具备以下的基本技能:
- 常规的 Node.js 应用开发的能力
- 常规的服务器性能指标参数的理解,比如 CPU、Memory、Load、文件打开数等
- 常见的数据库、缓存等操作
- 负载均衡、多进程模型
- 如果使用容器,容器的基本知识,资源管理等
本书首发在 Github,仓库地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,云栖社区会同步更新。
常规排查的指标
当我们第一次遇到线上异常时,很多人会感觉无从下手。本节作为预备篇,将从服务器异常时常见的排查指标开始,帮助大家建立一个更加直观的问题处理体系。
毕竟如果我们面对线上异常时,如果连系统哪里有问题都不知道,那么后续的借助 Node.js 性能平台 更深入定位问题代码就更加无从谈起了。
错误日志
当我们的应用出现问题时,首先需要去查看我们应用的错误日志,观察在这段时间内是不是有错误在一直抛出,导致了我们的服务不稳定。
这一块的信息显然是因各个应用而异的,当我们的项目比较大(Ecs/Docker 节点比较多)的时候,就需要对错误日志的进行统一的采集收集来保证出问题时的快速定位。一个比较简单的统一日志平台可以设计如下:
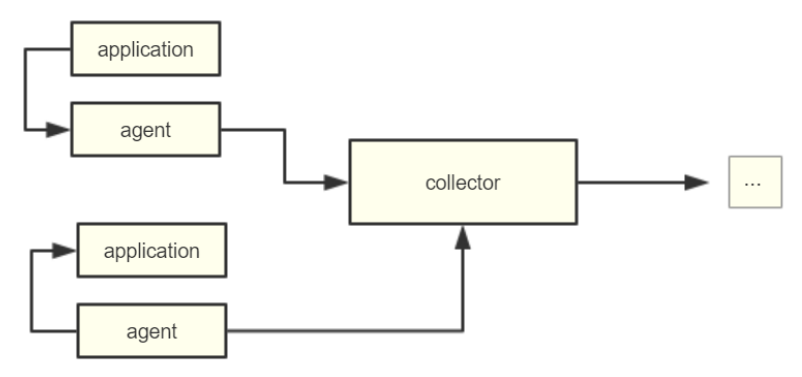
其中的采集服务器和 Agent 上报之间一般会采用消息队列(Kafka)来作为缓冲区减轻双方的负载,ELK 就是一个比较成熟的日志服务。
有了统一的日志平台后,当我们的应用出现问题时,首先应该去日志平台上查看当前的错误日志信息,特别是对于那些在 频繁出现 的错误日志应当引起警惕,需要去仔细地结合产生错误的代码段进行回溯确认是否是造成当前服务不稳定的元凶,Node.js 性能平台 也实现了一个简单的错误日志回溯 + 告警的系统,本书第二部分会更详细说明。
系统指标
如果在上述的错误日中没有看到可疑的信息(实际上错误日志以及本节的系统指标排查先后顺序并无固定,大家可以视自己的需求进行),那么接下来我们就应该关注下问题是不是因为服务器或者 Node.js 应用本身的负载到了极限导致的问题。一些比较常见的大家需要关注的系统指标如下所示:
- CPU & Memory
- Disk 磁盘占用率
- I/O 负载
- TCP 连接状态
下面逐一讲解这些可能存在问题的系统指标。
I. CPU & Memory
使用 top 命令来观察和 Node.js 应用进程的 CPU 和 Memory 负载情况。一般来说,对于 CPU 很高 Node.js 进程,我们可以使用 Node.js 性能平台 提供的 CPU Profiling 工具来在线 Dump 出当前的 Javascript 运行情况,进而找到热点代码进行优化,具体在本书第二部分会有更详细地说明。
那么对于 Memory 负载很高的情况,正常来说就是发生了内存泄漏(或者有预期之外的内存分配导致溢出),那么同样的我们可以用性能平台提供的工具来在线 Dump 出当前的 Javascript 堆内存和服务化的分析来结合你的业务代码找到产生泄漏的逻辑。
这里需要注意的是,目前性能平台能够进行详尽分析的地方集中在你的 JS 代码上,对于完全是 C++ 扩展执行的或者完全的 V8/Libuv 底层执行(这部分功能后面会补上)的逻辑,以及不分配在 V8 Heap 上的内存,性能平台目前没有更好的办法来进行分析处理。而实际上在我们遇到的案例中,大家编写的 JS 代码出问题占了绝大部分,也就是性能平台目前针对 JS 部分比较完善的在线 Dump + 服务化分析基本上能够解决开发者 95% 甚至以上的问题了。
II. Disk 磁盘占用率
使用 df 命令可以观察当前的磁盘占用情况,这个也是非常常见的问题,很多开发者会忽略对服务器磁盘的监控告警,当我们的日志/核心转储等大文件逐渐将磁盘打满到 100% 的时候,Node.js 应用很可能会无法正常运行,Node.js 性能平台 目前也提供了对磁盘的监控,在本书第二部分同样会有更详细地说明。
III. I/O 负载
使用 top/iostat 和 cat /proc/${pid}/io 来查看当前的 I/O 负载,这一项的负载很高的话,也会使得 Node.js 应用出现卡死等情况。
IV. TCP 连接状态
绝大部分的 Node.js 应用实际上是 Web 应用,每个用户的连接都会创建一个 Socket 连接,在一些异常情况下(比如遭受半连接攻击或者内核参数设置不合理),服务器上会有大量的 TIME_WAIT 状态的连接,而大量的 TIME_WAIT 积压会导致 Node.js 应用的卡死(内核无法为新的请求分配创建新的 TCP 连接),我们可以使用 netstat -ant|awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}' 命令来确认这个问题。
核心转储(Core dump)
线上 Node.js 应用故障往往也伴随着进程的 Crash,借助于一些守护进程的自检重启拉起,我们的服务依旧在运行,但是我们不应该去忽略这些意外的 Crash —— 当流量增大或者造成服务器的问题用户访问被别有用心之人抓住时,我们集群就变得岌岌可危了。
绝大部分情况下,会造成 Node.js 应用 Crash 掉的错误日志往往并不会记录到我们的错误日志文件中,幸运的是,服务器内核提供了一项机制帮助我们在应用 Crash 时自动地生成核心转储(Core dump)文件,让开发者可以在事后进行分析还原案发现场。
核心转储
核心转储(Core dump)实际上是我们的应用意外崩溃终止时,计算机自动记录下进程 Crash 掉那一刻的内存分配信息、Program counter 以及堆栈指针等关键信息来生成核心转储文件,因此获取到核心转储文件后,我们可以通过 MDB、GDB、LLDB 等工具即可实现解析诊断实际进程的 Crash 原因。
生成文件
触发核心转储生成转储文件目前主要有两种方式:
I. 设置内核参数
使用 ulimit -c unlimited 打开内核限制,并且考虑到默认运行模式下,Node.js 对 JS 造成的 Crash 是不会触发核心转储动作的,因此我们可以在 Node 应用启动时加上参数 --abort-on-uncaught-exception 来对出现未捕获的异常时也能让内核触发自动的核心转储动作。
II. 手动调用
手动调用 gcore <pid> (可能需要 sudo 权限)的方式来手动生成,因为此时 Node.js 应用依旧在运行中,所以实际上这种方式一般用于 「活体检验」,用于 Node.js 进程假死状态 下的问题定位。
这里需要注意的是,以上的生成核心转储的操作都 并没有那么安全务必记得对服务器磁盘进行监控和告警**。
获取到 Node.js 应用生成的核心转储文件后,我们可以借助于 Node.js 性能平台 提供的在线 Core dump 文件分析功能进行分析定位进程 Crash 的原因了,具体用法会在本书第二部分进行说明。
小结
本节从常见的几个服务器问题点,给大家对线上 Node.js 应用出现故障时如何去排查定位有了一些大概的印象,本章也是后续内容的一个预备知识,了解了这部分内容,才能在后面的一些实战案例中明白为何我们忽略了其它而选择详尽地服务化分析其中的一些要点。
而核心转储的深入分析则能够帮助我们解决 Node.js 应用的绝大部分底层故障,因为其可以还原出问题 JavaScript 代码和引发问题的参数,功能非常地强大。
原文链接
本文为云栖社区原创内容,未经允许不得转载。









