
PP (Parallel Python)是基于Python的一个轻量级的,提供在SMP(多处理器或者多核系统)或者集群环境中并行执行Python代码的机制。
最简单和最常见的并行方式是使用多线程,然而如果应用程序使用Python提供的线程库, 它实际上并不能并行的运行Python的字节码(Byte-Code)。这是因为Pyton解释器使用GIL(全局解释器锁),这样的机制是的在同一时间,即使是多核的机器,也只能运行一个字节码指令。PP试图克服这样的限制,提供一种更简单的方式来编写并行应用。PP采用了多进程和进程间通信来处理并发,并隐藏所有的实现细节,使得其容易使用。
功能介绍
并行运行Python代码(废话)
易于理解的基于任务(Job)的并行技术
自动检测优化配置
动态处理器分配
负载均衡
容错
自动发现和动态分配计算资源
基于SHA的网络连接认证
跨平台(Windows,Linux, Unix, Mac OS)和架构(X86,X86-64)支持
开源 (BSD)
安装
wget
tar -xvf pp-1.6.4.tar.gz
cd pp-1.6.4
sudo python setup.py install
架构和设计
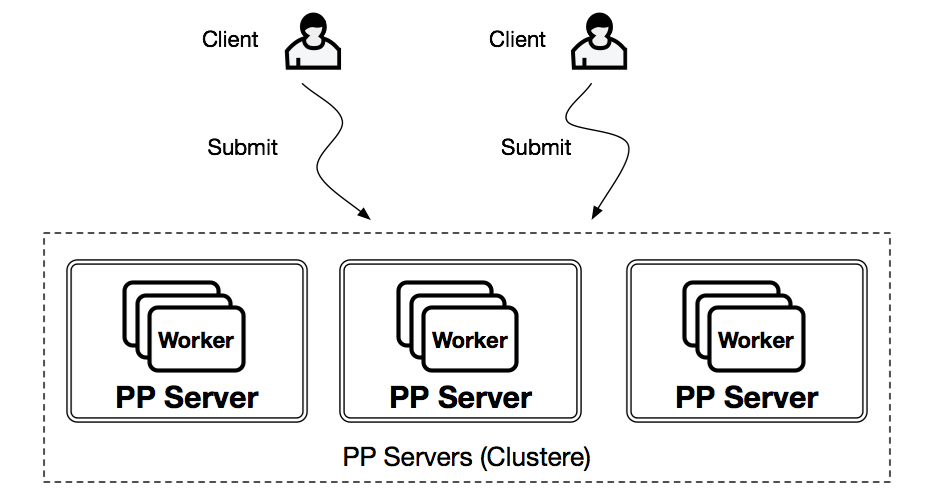
Server
PP server 包含并管理多个worker并行的执行客户端发送的任务
Client
客户端负责发送任务(Python Function)到服务器
Cluster
多个PP Server可以构成一个PP Cluster,在CLuster模式客户端提交任务到Cluster,cluster 找到合适的Server来运行任务。
使用方式
SMP
在SMP的模式下使用PP非常简单
import pp
# create a job serer
job_server = pp.Server()
# submit some jobs with python functions
f1 = job_server.submit(func1, args1, depfuncs1, modules1)
f2 = job_server.submit(func1, args2, depfuncs1, modules1)
f3 = job_server.submit(func2, args3, depfuncs2, modules2)
# Get result from each jobs
r1 = f1()
r2 = f2()
r3 = f3()
Cluster
在Cluster模式下,需要在不同的节点运行ppserver
node-1> ./ppserver.py
node-2> ./ppserver.py
node-3> ./ppserver.py
客户端代码和SMP模式类似
import pp
# create cluster
ppservers=("node-1", "node-2", "node-3")
# create a job serer
pp.Server(ppservers=ppservers)
# submit some jobs with python functions
f1 = job_server.submit(func1, args1, depfuncs1, modules1)
f2 = job_server.submit(func1, args2, depfuncs1, modules1)
f3 = job_server.submit(func2, args3, depfuncs2, modules2)
# Get result from each jobs
r1 = f1()
r2 = f2()
r3 = f3()
总结
PP是一个轻量级的并行框架,代码不多,安装使用起来也比较简单,并行方式是多进程,但是缺乏对任务的封装,也缺少调度的功能。适合于构造简单的并行分布式系统。











