

作者:吉玉
智能化测试
在互动中经常需要维护大量的状态,对这些状态进行测试验证成本较高,尤其是当有功能变动需要回归测试的时候。为了降低开发测试的成本,在这方面使用强化学习模拟用户行为,在两个方面提效:
- mock接口:将学习过程中的状态作为服务接口的测试数据;
- 回归测试:根据mock接口数据回溯到特定状态,Puppeteer根据强化学习触发前端操作,模拟真实用户行为;
什么是强化学习呢?
强化学习是机器学习的一个领域,它强调如何基于环境行动,获取最大化的预期利益。强化学习非常适用于近几年比较流行的电商互动机制:做任务/做游戏 -> 得到不同的奖励值 -> 最终目标大奖,在这类型的互动游戏中,奖励是可预期的,用户的目标是使得自己的奖励最大化。这个过程可以抽象为马尔科夫决策模型:玩家(agent)通过不同的交互行为(action),改变游戏(environment)的状态(state),反馈给玩家不同的奖励 (reward);这个过程不断循环迭代, 玩家的最终目标是奖励最大化。
接下来,我们使用比较简单的Q-learning,来实现类似的智能化测试目的。
Q-learning
对于不同状态下,Q-learning的Q(s,a)表示在某一个时刻的s状态下,采取动作a可以得到的收益期望,算法的主要思想是将state和ation构建一张Q-table来存储Q值,根据Q值来选取能够获得最大收益的动作。Q值的公式计算如下:
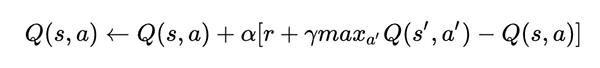
其中,s表示state,a表示action,α为学习率,γ为衰减率,r表示action能带来的收益。
这个公式表示当前状态的Q值由“记忆中”的利益(max Q[s',a])和当前利益(r)结合形成。衰减率γ越高,“记忆中”的利益影响越大;学习率α越大,当前利益影响越大。Q-learning的目标是通过不断训练,最后得到一个能拿到最多奖励的最优动作序列。
在赛车游戏中,玩家的交互行为包含购买车厢、合成车厢、做任务获得金币(为了方便理解,此处简化为一个任务);玩家从初始化状态开始,通过重复“action -> 更新state”的过程,以下的伪代码简单的说明我们怎么得到一个尽量完美的Q表格:
// action: [ 购买车厢,合成车厢,做任务获得金币 ]
// state: 包含等级、拥有车厢等级、剩余金币表示
初始化 Q = {}
while Q未收敛:
初始化游戏状态state
while 赛车没有达到50级:
使用策略π,获得动作a = π(S)
使用动作a,获得新的游戏状态state
更新Q,Q[s,a] ← (1-α)*Q[s,a] + α*(R(s,a) + γ* max Q[s',a])
更新状态state
简单的demo地址:
https://github.com/winniecjy/618taobao
Puppeteer
由上面Q-learning的训练过程,我们可以得到一系列的中间态接口作为mock数据,可以很快的回溯到特定状态进行测试,这一点在回归测试的时候十分有用。但是仅仅只是自动mock数据对效率提升还是有限,在618互动中,友商的互动团队结合Puppeteer对整个流程进行自动化测试。Puppeteer是chrome团队推出的一个工具引擎,提供了一系列的API控制Chrome,可以自动提交表单、键盘输入、拦截修改请求、保存UI快照等。
结合Puppeteer的一系列操作逻辑,部分是可以沉淀成为一个通用的测试环境的,比如:
- 不同用户类型,如登录、非登录、风险、会员等;
- 接口拦截mock逻辑;
- 页面快照留存;
- 页面性能数据留存;
- 其他常见的业务逻辑,如互动任务体系,跳转后等几秒后返回,加积分;
- ...
弹窗规模化
在互动中,弹窗一直是视觉表现的一个重要组成部分,对UI有比较强的定制需求。
友商的思路是将所有的逻辑尽可能的沉淀。对于电商场景来说,弹窗的业务逻辑是可穷举、可固化的,而互动场景之下,UI定制化需求很高,所以将UI层抽离, 仅对可复用的逻辑进行固化,以DSL + Runtime的机制动态下发。
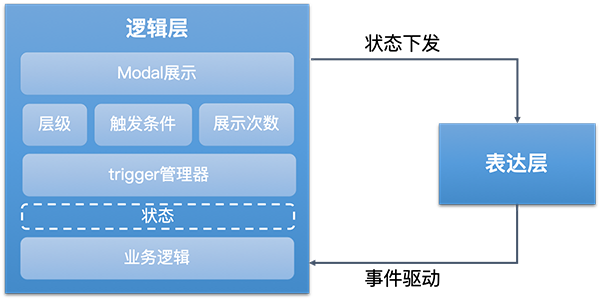
结合这一套逻辑层模型,表达层/UI层也可以相应的结构化。根据项目 > 场景 > 图层的维度,静态配置和动态绑定相结合,搭配对应的配置平台就可以实现动态下发。
总结
对于智能化测试,80%的流程其实成本是相对较低的,从测试用例的生成到puppeteer自动化测试,都是可以参考学习的,图像对比的部分需要较多训练,对于固化的功能可以进行探索,如果是新的模式性价比较低。
对于弹窗规模化,部门内部的做法是将弹窗沉淀成一个通用的组件,只包含通用的兼容逻辑,包括显示/隐藏、弹窗出现底层禁止滚动、多弹窗层级问题等。对于UI和其他业务逻辑,复用性较低,所以每次都是重写。这种做法尽可能地保持了组件的通用性,在会场线比较适用,因为会场线的弹窗一般不包含业务逻辑(如抽奖、PK等),但是对于互动线来说,复用的内容相较于弹窗的“重量”来说显得有些微不足道。 友商的沉淀思路前提在于上游接口的逻辑需要可复用,上游逻辑如果无法固定下来,前端的互动逻辑也较难固化。总体来说,友商在互动方面的沉淀思路大部分是从开发提效出发,主要供给内部使用;京东内部已有类似的互动提效方案终极目标是盈利,如京喜的社交魔方平台和最近正在成型的满天星平台,所以沉淀方式都是以成套的H5。
参考
[1] 生产力再提速,618互动项目进化之路
[2] 机器学习相关教程 - 莫烦
[3] Puppeteer docs
欢迎关注凹凸实验室博客:aotu.io
或者关注凹凸实验室公众号(AOTULabs),不定时推送文章。











