
Celery (芹菜)是基于Python开发的分布式任务队列。它支持使用任务队列的方式在分布的机器/进程/线程上执行任务调度。
架构设计
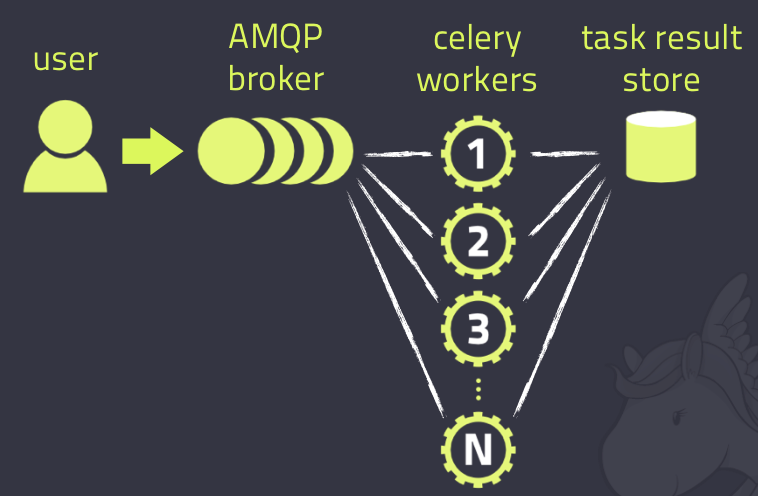
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis, MongoDB (experimental), Amazon SQS (experimental),CouchDB (experimental), SQLAlchemy (experimental),Django ORM (experimental), IronMQ
任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, Redis,memcached, MongoDB,SQLAlchemy, Django ORM,Apache Cassandra, IronCache
另外, Celery还支持不同的并发和序列化的手段
并发
序列化
pickle, json, yaml, msgpack. zlib, bzip2 compression, Cryptographic message signing 等等
安装和运行
Celery的安装过程略为复杂,下面的安装过程是基于我的AWS EC2的Linux版本的安装过程,不同的系统安装过程可能会有差异。大家可以参考官方文档。
首先我选择RabbitMQ作为消息中间件,所以要先安装RabbitMQ。作为安装准备,先更新YUM。
sudo yum -y update
RabbitMQ是基于erlang的,所以先安装erlang
# Add and enable relevant application repositories:
# Note: We are also enabling third party remi package repositories.
wget http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
wget http://rpms.famillecollet.com/enterprise/remi-release-6.rpm
sudo rpm -Uvh remi-release-6*.rpm epel-release-6*.rpm
# Finally, download and install Erlang:
yum install -y erlang
然后安装RabbitMQ
# Download the latest RabbitMQ package using wget:
wget
# Add the necessary keys for verification:
rpm --import
# Install the .RPM package using YUM:
yum install rabbitmq-server-3.2.2-1.noarch.rpm
启动RabbitMQ服务
rabbitmq-server start
RabbitMQ服务已经准备好了,然后安装Celery, 假定你使用pip来管理你的python安装包
pip install Celery
为了测试Celery是否工作,我们运行一个最简单的任务,编写tasks.py
from celery import Celery
app = Celery('tasks', backend='amqp', broker='amqp://guest@localhost//')
app.conf.CELERY_RESULT_BACKEND = 'db+sqlite:///results.sqlite'
@app.task
def add(x, y):
return x + y
在当前目录运行一个worker,用来执行这个加法的task
celery -A tasks worker --loglevel=info
其中-A参数表示的是Celery App的名字。注意这里我使用的是SQLAlchemy作为结果存储。对应的python包要事先安装好。
worker日志中我们会看到这样的信息
- ** ---------- [config]
- ** ---------- .> app: tasks:0x1e68d50
- ** ---------- .> transport: amqp://guest:**@localhost:5672//
- ** ---------- .> results: db+sqlite:///results.sqlite
- *** --- * --- .> concurrency: 8 (prefork)
其中,我们可以看到worker缺省使用prefork来执行并发,并设置并发数为8
下面的任务执行的客户端代码:
from tasks import add
import time
result = add.delay(4,4)
while not result.ready():
print "not ready yet"
time.sleep(5)
print result.get()
用python执行这段客户端代码,在客户端,结果如下
not ready
8
Work日志显示
[2015-03-12 02:54:07,973: INFO/MainProcess] Received task: tasks.add[34c4210f-1bc5-420f-a421-1500361b914f]
[2015-03-12 02:54:08,006: INFO/MainProcess] Task tasks.add[34c4210f-1bc5-420f-a421-1500361b914f] succeeded in 0.0309705100954s: 8
这里我们可以发现,每一个task有一个唯一的ID,task异步执行在worker上。
这里要注意的是,如果你运行官方文档中的例子,你是无法在客户端得到结果的,这也是我为什么要使用SQLAlchemy来存储任务执行结果的原因。官方的例子使用AMPQ,有可能Worker在打印日志的时候取出了task的运行结果显示在worker日志中,然而AMPQ作为一个消息队列,当消息被取走后,队列中就没有了,于是客户端总是无法得到任务的执行结果。不知道为什么官方文档对这样的错误视而不见。
如果大家想要对Celery做更进一步的了解,请参考官方文档











