一、什么是大文件 一般,我们传送大文件是指传送大于100M的文件,而普通文件是指小于100M,常见的是20M、30M和50M,两者主要的区别在于文件大小上,还有传送速度上。
一般普通“邮件附件”只能发20M、30M,50M的文件,而几百M的照片、文件、设计图等大文件传送起来就不是那么容易了。
二、大文件跟普通文件上传时的区别 普通文件上传只需要注意两点
1.指定上传的接口地址。 2.将请求头的Content-Type设置成:multipart/form-data,将文件对象以二进制流的形式传给后端
大文件上传时会遇到的问题
1.前后端上传请求超时限制,一次性传输大小限制。 2.网络抖动等,失败后需要重新上传。 3.http1.1版本, TCP连接默认是open的,所有请求都通过同一个连接进行数据传输,如果前面的请求被阻塞了,后面的请求也得不到响应,也叫HTTP/1.1 中的队头阻塞问题,除非建立多个连接,但是多个连接会浪费资源。 4.无进度条,用户体验极差。
三、大文件上传的原理及思路 前端
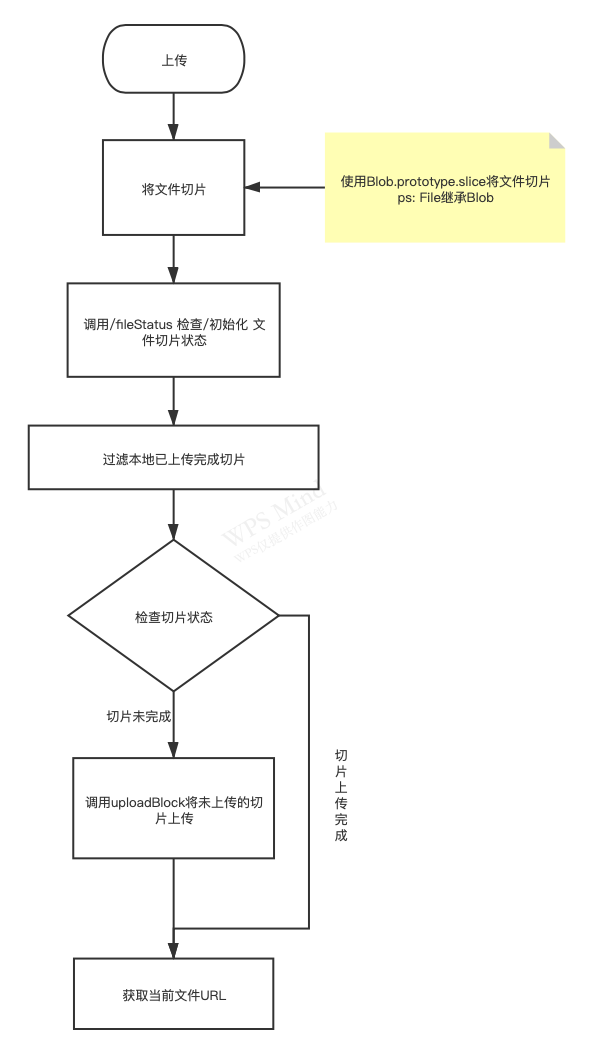
获取文件的二进制内容,然后对其内容拆分成指定大小的切片文件,最后将每个切片上传到服务端即可。
流程:获取文件 ➡️ 分片 ➡️ 上传
需要优化的点
•中断后无需重新上传(断点续传) •上传过的文件无需上传(秒传) •显示上传进度
后端
根据切片文件的唯一标识在后端将多个相同文件的切片还原成一个文件
流程:获取分片文件 ➡️ 还原分片 ➡️ 返回拼接好的文件信息
需要优化的点
•删除碎片文件 还原切片时需要注意的问题
•在后端需要将多个相同文件的切片还原成一个文件,如果不能识别一个切片是属于哪一个文件的,当同时发生多个请求时,追加的文件内容会出错。 •切片上传接口是异步的,无法保证服务器接收到的切片是按照请求顺序拼接的。 解决办法
1)如何识别多个切片是来自于同一个文件的?
这个可以在发送请求时,为每个切片传递一个相同文件的identifier参数。
2)如何将多个切片还原成一个文件?
什么时候开始拼接:确认所有切片都已上传完后开始进行拼接,这个可以通过客户端在切片全部上传后调用后端定义的mkfile接口来通知服务端进行拼接,或者前端传递切片的总数totalChunks, 服务端判断接收的切片数量如果等于totalChunks的值就开始进行拼接,无须前端通知后端进行拼接。
怎么按顺序拼接:可以在每个切片上标记一个位置索引值,找到同一个context下的所有切片,根据chunkNumber确认每个切片的顺序,这个按顺序拼接切片,还原成文件
上面有几个重要的参数: identifier ,chunkNumber,totalChunks
identifier :我们需要获取为一个文件的唯一标识,可以通过下面两种方式获取
根据文件名、文件长度等基本信息进行拼接,为了避免多个用户上传相同的文件,可以再额外拼接用户信息如uid等保证唯一性
根据文件的二进制内容计算文件的hash,这样只要文件内容不一样,则标识也会不一样,缺点在于计算量比较大.
chunkNumber:当前切片的索引
totalChunks:总的切片数
四、大文件上传的实现方案 前端分片代码
// 获取identifier,同一个文件会返回相同的值 function createIdentifiert(file) { return file.name + file.size }
let file = document.querySelector("[name=file]").files[0]; const LENGTH = 1024 * 1024 * 1;//1MB let chunks = slice(file, LENGTH);
// 获取对于同一个文件,获取其identifier let identifier = createIdentifier(file);
let tasks = []; chunks.forEach((chunk, index) => { let fd = new FormData(); //传递file对象 fd.append("file",chunk); // 传递identifier fd.append("identifier", identifier); // 传递切片索引值 fd.append("chunkNumber", index + 1); // 传递切片总数 fd.append(“totalChunks”, chunks.length);
tasks.push(post("/mkblk.php", fd)); });
// 所有切片上传完毕后,调用mkfile接口 Promise.all(tasks).then(res => { let fd = new FormData(); fd.append("identifier", identifier); fd.append("totalChunks",chunks.length); post("/mkfile.php", fd).then(res => { console.log(res); }) });
后端还原分片代码
// mkblk.php接口 $identifier = $_POST['identifier']; $path = './upload/' . $identifier; if(!is_dir($path)){ mkdir($path); } // 把同一个文件的切片放在相同的目录下 $filename = $path . '/' . $_POST['chunkNumber’]; // 清除保存的切片 $res = move_uploaded_file($_FILES['file']['tmp_name'], $filename);
//接下来是mkfile.php接口的实现,这个接口会在所有切片上传后调用用来合并文件
// mkfile.php接口 $identifier = $_POST['identifier']; $totalChunks= (int)$_POST['totalChunks'];
//合并后的文件名 $filename = './upload/' . $identifier . '/file.jpg’; // 开始合并文件 for($i = 1; $i <= $totalChunks; ++$i){ $file = './upload/'.$ identifier. '/' .$i; // 读取单个切块 // 获取文件内容 $content = file_get_contents($file); if(!file_exists($filename)){ //创建一个用于读写的空文件 $fd = fopen($filename, "w+"); }else{ //追加到一个文件,写操作向文件末尾追加数据。如果文件不存在,则创建文件。 $fd = fopen($filename, "a"); } fwrite($fd, $content);// 将切块合并到一个文件上 }
以上代码还需要继续优化的点:断点续传、秒传、上传进度和暂停
1、断点续传
为什么需要断点续传?
即使将大文件拆分成切片上传,我们仍需等待所有切片上传完毕,在等待过程中,可能发生一系列导致部分切片上传失败的情形,如网络故障、页面关闭等。由于切片未全部上传,因此无法通知服务端合成文件。这种情况下可以通过断点续传来进行处理。
断点续传指的是:可以从已经上传部分开始继续上传未完成的部分,而没有必要从头开始上传,节省上传时间。 怎么实现断点续传?
由于整个上传过程是按切片维度进行的,且mkfile接口是在所有切片上传完成后由客户端主动调用的,因此断点续传的实现也十分简单:
在切片上传成功后,保存已上传的切片信息
当下次传输相同文件时,遍历切片列表,只选择未上传的切片进行上传
所有切片上传完毕后,再调用mkfile接口通知服务端进行文件合并
因此问题就落在了如何保存已上传切片的信息了,保存一般有两种策略
1.可以通过locaStorage等方式保存在前端浏览器中,这种方式不依赖于服务端,实现起来也比较方便,缺点在于如果用户清除了本地文件,会导致上传记录丢失
2.服务端本身知道哪些切片已经上传,因此可以由服务端额外提供一个根据文件context查询已上传切片的接口,在上传文件前调用该文件的历史上传记录 前端断点续传代码
// 获取已上传切片记录 function getUploadSliceRecord(context){ let record = localStorage.getItem(context) if(!record){ return [] }else { return JSON.parse(record) } }
// 保存已上传切片 function saveUploadSliceRecord(context, sliceIndex){ let list = getUploadSliceRecord(context) list.push(sliceIndex) localStorage.setItem(context, JSON.stringify(list)) }
let context = createContext(file);
// 获取上传记录 let record = getUploadSliceRecord(context); let tasks = []; chunks.forEach((chunk, index) => { // 已上传的切片则不再重新上传 if(record.includes(index)){ return }
let fd = new FormData();
fd.append("file", chunk);
fd.append("context", context);
fd.append("chunk", index + 1);
let task = post("/mkblk.php", fd).then(res=>{
// 上传成功后保存已上传切片记录
saveUploadSliceRecord(context, index)
record.push(index)
})
tasks.push(task);
}); ...
后端断点续传代码
服务端实现断点续传的逻辑基本相似,只要在getUploadSliceRecord内部调用服务端的查询接口获取已上传切片的记录即可,因此这里不再展开。
后端代码优化:清除切片的时机
此外断点续传还需要考虑切片过期的情况
如果调用了mkfile接口,则磁盘上的切片内容就可以清除掉了,如果客户端一直不调用mkfile的接口,放任这些切片一直保存在磁盘显然是不可靠的,一般情况下,切片上传都有一段时间的有效期,超过该有效期,就会被清除掉。基于上述原因,断点续传也必须同步切片过期的实现逻辑。 2、秒传
什么是秒传?
已经上传过的文件,并且在后端已经拼接完成,如果再次上传的话后端不做处理,直接返回拼接好的文件的信息即可,这里主要后端实现,由于篇幅关系,这里不做过多描述。 3、上传进度和暂停
通过xhr.upload中的progress方法可以实现监控每一个切片上传进度。
上传暂停的实现也比较简单,通过xhr.abort可以取消当前未完成上传切片的上传,实现上传暂停的效果,恢复上传就跟断点续传类似,先获取已上传的切片列表,然后重新发送未上传的切片。
由于篇幅关系,上传进度和暂停的功能这里就先不实现了。
五、目前成熟的大文件上传方案 目前社区已经存在一些成熟的大文件上传解决方案,也许并不需要我们手动去实现一个简陋的大文件上传库,但是了解其原理还是十分有必要的。
推荐的前端vue组件:vue-simple-uploader,支持vue2,vue3
vue-simple-uploader是基于simple-Uploader.js封装的大文件上传组件,具有以下优点:
- 支持单文件、多文件、文件夹上传;支持拖拽文件、文件夹上传
- 可暂停、继续上传
- 错误处理
- 支持“秒传”,通过文件判断服务端是否已存在从而实现“秒传”
- 分块上传
- 支持进度、预估剩余时间、出错自动重试、重传等操作
vue-simple-uploader 内部的实现也很简单,有兴趣的同学可以去看一下源码
六、总结 本文首先介绍了什么是大文件,以及大文件跟普通文件在上传时的区别,最后通过分析大文件上传的原理和思路给出简单的实现方案,并且推荐了一个成熟的vue大文件上传组件:vue-simple-uploader,希望对大家有所帮助。
作者:京东物流 于俊娇
来源:京东云开发者社区 自猿其说 Tech 转载请注明来源