
一、背景
随着公司业务的发展,商品库存从商品中心独立出来成为一个独立的系统,承接主站商品库存校验、订单库存扣减、售后库存释放等业务。在上线之前我们对于核心接口进行了压测,压测过程中出现了 MySQL 5.6.35 死锁现象,通过日志发现引发死锁的只是一条简单的sql,死锁是怎么产生的?发扬技术人员刨根问底的优良传统,对于这次死锁原因进行了细致的排查和总结。本文既是此次过程的一个记录。
在深入探究问题之前,我们先了解一下 MySQL 的加锁机制。
二、MySQL 加锁机制
首先要明确的一点是 MySQL 加锁实际上是给索引加锁,而非给数据加锁。我们先看下MySQL 索引的结构。
MySQL 索引分为主键索引(或聚簇索引)和二级索引(或非主键索引、非聚簇索引、辅助索引,包括各种主键索引外的其他所有索引)。不同存储引擎对于数据的组织方式略有不同。
对InnoDB而言,主键索引和数据是存放在一起的,构成一颗B+树(称为索引组织表),主键位于非叶子节点,数据存放于叶子节点。示意图如下:
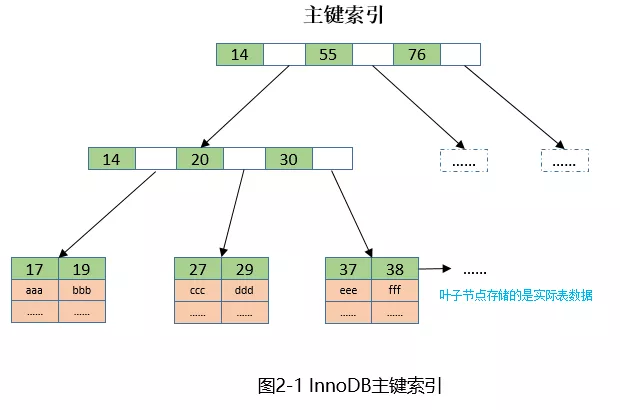
而MyISAM是堆组织表,主键索引和数据分开存放,叶子节点保存的只是数据的物理地址,示意图如下:
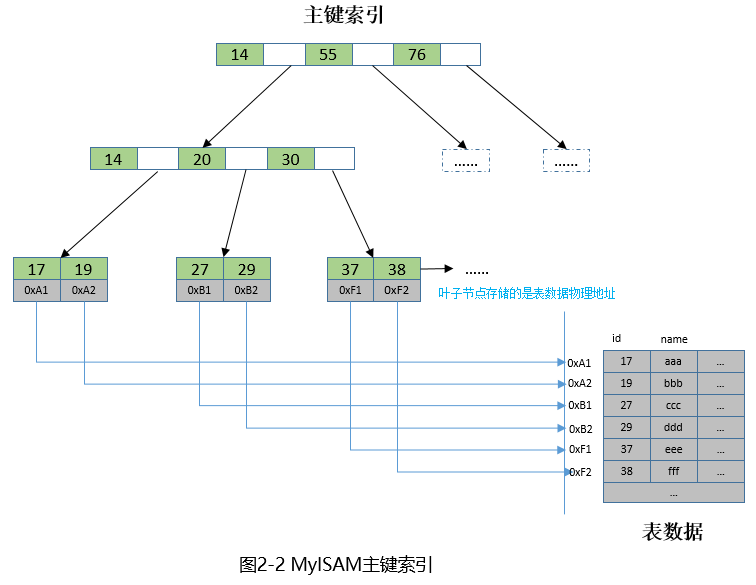
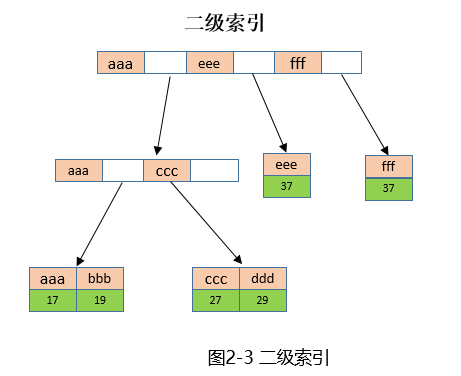
二级索引的组织方式对于InnoDB和MyISAM是一样的,保存了二级索引和主键索引的对应关系,二级索引列位于非叶子节点,主键值位于叶子节点,示意图如下:
那么在MySQL 的这种索引结构下,我们怎么找到需要的数据呢?
以select * from t where name='aaa'为例,MySQL Server对sql进行解析后发现name字段有索引可用,于是先在二级索引(图2-2)上根据name='aaa'找到主键id=17,然后根据主键17到主键索引上(图2-1)上找到需要的记录。
了解 MySQL 利用索引对数据进行组织和检索的原理后,接下来看下MySQL 如何给索引枷锁。
需要了解的是索引如何加锁和索引类型(主键、唯一、非唯一、没有索引)以及隔离级别(RC、RR等)有关。本例中限定隔离级别为RC,RR情况下和RC加锁基本一致,不同的是RC为了防止幻读会额外加上间隙锁。
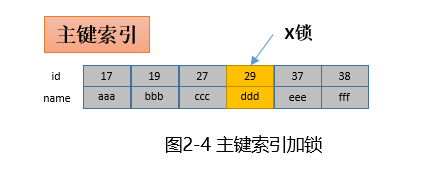
2.1 根据主键进行更新
update t set name='xxx' where id=29;只需要将主键上id=29的记录加上X锁即可(X锁称为互斥锁,加锁后本事务可以读和写,其他事务读和写会被阻塞)。如下:
2.2 根据唯一索引进行更新
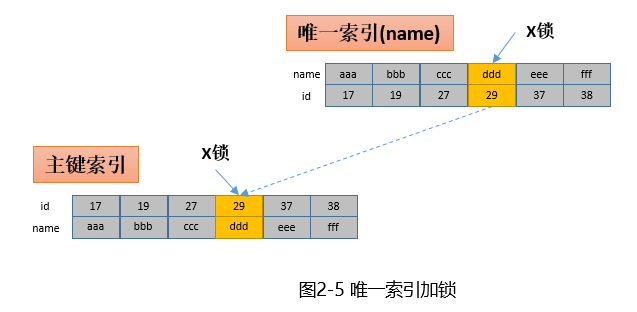
update t set name='xxx' where name='ddd';这里假设name是唯一的。InnoDB现在name索引上找到name='ddd'的索引项(id=29)并加上加上X锁,然后根据id=29再到主键索引上找到对应的叶子节点并加上X锁。
一共两把锁,一把加在唯一索引上,一把加在主键索引上。这里需要说明的是加锁是一步步加的,不会同时给唯一索引和主键索引加锁。这种分步加锁的机制实际上也是导致死锁的诱因之一。示意如下:
2.3 根据非唯一索引进行更新
update t set name='xxx' where name='ddd';这里假设name不唯一,即根据name可以查到多条记录(id不同)。和上面唯一索引加锁类似,不同的是会给所有符合条件的索引项加锁。示意如下:
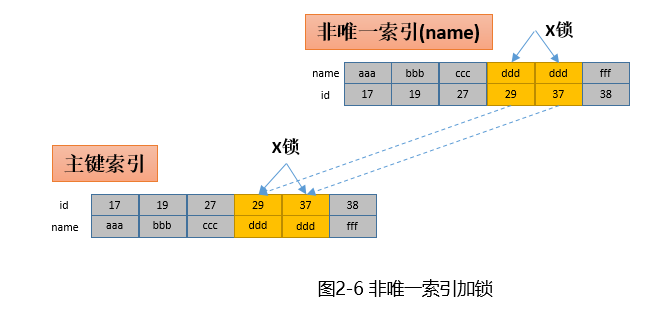
这里一共四把锁,加锁步骤如下:
- 在非唯一索引(name)上找到(ddd,29)的索引项,加上X锁;
- 根据(ddd,29)找到主键索引的(29,ddd)记录,加X锁;
- 在非唯一索引(name)上找到(ddd,37)的索引项,加上X锁;
- 根据(ddd,29)找到主键索引的(37,ddd)记录,加X锁;
从上面步骤可以看出,InnoDB对于每个符合条件的记录是分步加锁的,即先加二级索引再加主键索引;其次是按记录逐条加锁的,即加完一条记录后,再加另外一条记录,直到所有符合条件的记录都加完锁。那么锁什么时候释放呢?答案是事务结束时会释放所有的锁。
小结:MySQL 加锁和索引类型有关,加锁是按记录逐条加,另外加锁也和隔离级别有关。
三、死锁现象及排查
了解MySQL 如何给索引加锁后,下面步入正题,看看实际场景下的死锁现象及其成因分析。
本次发生死锁的是库存扣减接口,该接口的主要逻辑是用户下单后,扣减订单商品在某个仓库的库存量。比如用户一个在vivo官网下单买了1台X50手机和1台X30耳机,那么下单后,首先根据用户收货地址确定发货仓库,然后从该仓库里面分别减去一个X50库存和一个X30库存。分析死锁sql之前,先看下商品库存表的定义(为方便理解,只保留主要字段):
CREATE TABLE `store` (
`id` int(10) AUTO_INCREMENT COMMENT '主键',
`sku_code` varchar(45) COMMENT '商品编码',
`ws_code` varchar(32) COMMENT '仓库编码',
`store` int(10) COMMENT '库存量',
PRIMARY KEY (`id`),
KEY `idx_skucode` (`sku_code`),
KEY `idx_wscode` (`ws_code`)
) ENGINE=InnoDB COMMENT='商品库存表'
注意这里分别给sku_code和ws_code两个字段单独定义了索引:idx_skucode, idx_wscode。这样做的原因主要是业务上有根据单个字段查询的要求。
再看下库存扣减update语句:
update store
set store = store-#{store}
where sku_code=#{skuCode} and ws_code = #{wsCode} and (store-#{store}) >= 0
这个sql的业务含义就是对某个商品(skuCode)从某个仓库(wsCode)中扣减store个库存量,同时上面的where条件同时出现了sku_code和ws_code字段,压测数据中 sku_code的选择度要比ws_code高,理论上这条sql应该会走idx_skucode索引,那么真实情况是怎样的呢?
好,接下来对库存扣减接口卡进行压测,50的并发,每个订单5个商品,刚压不到半分钟就出现了死锁,再压,问题依旧,说明是必现的问题,必现解决后才能继续。在MySQL 终端执行 show engine innodb status 命令查看最后一次死锁日志,主要关注日志中的 LATEST DETECTED DEADLOCK 部分:
------------------------
LATEST DETECTED DEADLOCK
------------------------
2020-xx-xx 21:09:05 7f9b22008700
*** (1) TRANSACTION:
TRANSACTION 4219870943, ACTIVE 0 sec fetching rows
mysql tables in use 3, locked 3
LOCK WAIT 10 lock struct(s), heap size 2936, 3 row lock(s)
MySQL thread id 301903552, OS thread handle 0x7f9b21a7b700, query id 5373393954 10.101.22.135 root updating
update store
set update_time = now(), store = store-1
where sku_code='5468754' and ws_code = 'NO_001' and (store-1) >= 0
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3331 page no 16 n bits 904 index `idx_wscode` of table `store` trx id 4219870943 lock_mode X locks rec but not gap waiting
Record lock, heap no 415 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 5; hex 5730303735; asc NO_001;;
1: len 8; hex 00000000000025a7; asc % ;;
*** (2) TRANSACTION:
TRANSACTION 4219870941, ACTIVE 0 sec fetching rows, thread declared inside InnoDB 1
mysql tables in use 3, locked 3
9 lock struct(s), heap size 2936, 4 row lock(s)
MySQL thread id 301939956, OS thread handle 0x7f9b22008700, query id 5373393941 10.101.22.135 root updating
update store
set update_time = now(), store = store-1
where sku_code='5655620' and ws_code = 'NO_001' and (store-1) >= 0
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 3331 page no 16 n bits 904 index `idx_wscode` of table `store` trx id 4219870941 lock_mode X locks rec but not gap
Record lock, heap no 415 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 5; hex 5730303735; asc NO_001;;
1: len 8; hex 00000000000025a7; asc % ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3331 page no 7 n bits 328 index `PRIMARY` of table `store` trx id 4219870941 lock_mode X locks rec but not gap waiting
Record lock, heap no 72 PHYSICAL RECORD: n_fields 9; compact format; info bits 0
0: len 8; hex 00000000000025a7; asc % ;;
1: len 6; hex 0000fb85fdf7; asc ;;
2: len 7; hex 1a00001d3b21d4; asc ;! ;;
3: len 7; hex 35343638373534; asc 5468754;;
4: len 5; hex 5730303735; asc NO_001;;
5: len 8; hex 8000000000018690; asc ;;
6: len 5; hex 99a76b2b97; asc k+ ;;
7: len 5; hex 99a7e35244; asc RD;;
8: len 1; hex 01; asc ;;
从上面日志可以看出,存在两个事务,分别在执行这两条sql时发生了死锁:
update store set update_time = now(), store = store-1 where sku_code='5468754' and ws_code = 'NO_001' and (store-1) >= 0
update store set update_time = now(), store = store-1 where sku_code='5655620' and ws_code = 'NO_001' and (store-1) >= 0
看一下实际数据:
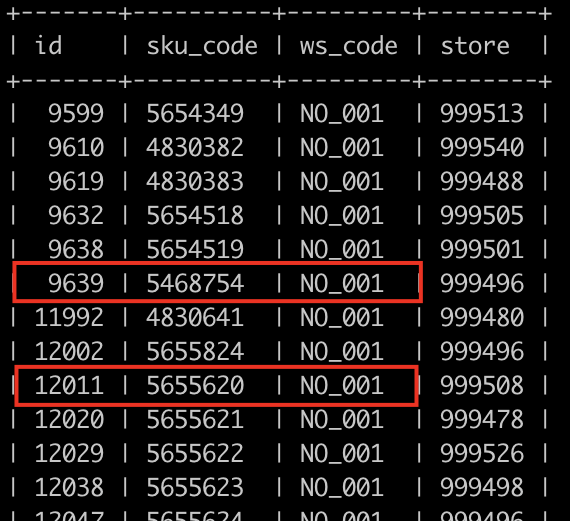
图3-1 库存表数据
就是说,这两个事务在更新同一张表的不同行时发生了死锁。在我们直观印象里,innodb使用的是行锁,不同的行锁之间应该是互不干扰的?那这是怎么一回事呢?
我们再看一下update的执行计划:

图3-2 update语句执行计划
和我们想象的不同,InnoDB既没有使用idx_skucode索引,也没有使用idx_wscode索引,而是使用了index_merge。index_merge和这两个索引是什么关系呢?
查询资料得知index_merge是MySQL 5.1后引入的一项索引合并优化技术,它允许对同一个表同时使用多个索引进行查询,并对多个索引的查询结果进行合并(取交集(intersect)、并集(union)等)后返回。
回到上面的update语句:where sku_code='5468754' and ws_code = 'NO_001' ;如果没有index_merge,要么走idx_skucode索引,要么走idx_wscode索引,不会出现两个索引一起使用的情况。而在使用index_merge技术后,会同时执行两个索引,分别查到结果后再进行合并(where条件是and,所以会做交集运算)。再结合第二部分对加锁机制(分步按记录加锁)的理解,是否隐约觉得两个索引的同时加锁是导致死锁的原因呢?
我们再深入死锁日志看一下,日志比较复杂,翻译过来大意如下:
1)事务一 4219870943 在执行update语句时,在等待索引idx_wscode上的行锁(编号space id 3331 page no 16 n bits 904 )。
2)事务二 4219870941 在执行update语句时,已经持有idx_wscode上的行锁(编号space id 3331 page no 16 n bits 904 ),从锁编号来看,就是事务一需要的锁。
3)事务二 4219870941 同时也在等待主键索引上的一把锁,这把锁谁在持有呢?从这行日志(3: len 7; hex 35343638373534; asc 5468754;;)可以看出,正是事务一要更新的那行记录,说明这把锁被事务一霸占着。
好了,死锁条件已经很清楚了:事务一在等待事务二持有的索引 idx_wscode上的行锁(编号space id 3331 page no 16 n bits 904 ),而事务二同时也在等待事务一持有的主键索引(5468754)上的锁,大家互不相让,只能僵在那里死锁喽^_^
用一张图来说明一下这个情况:
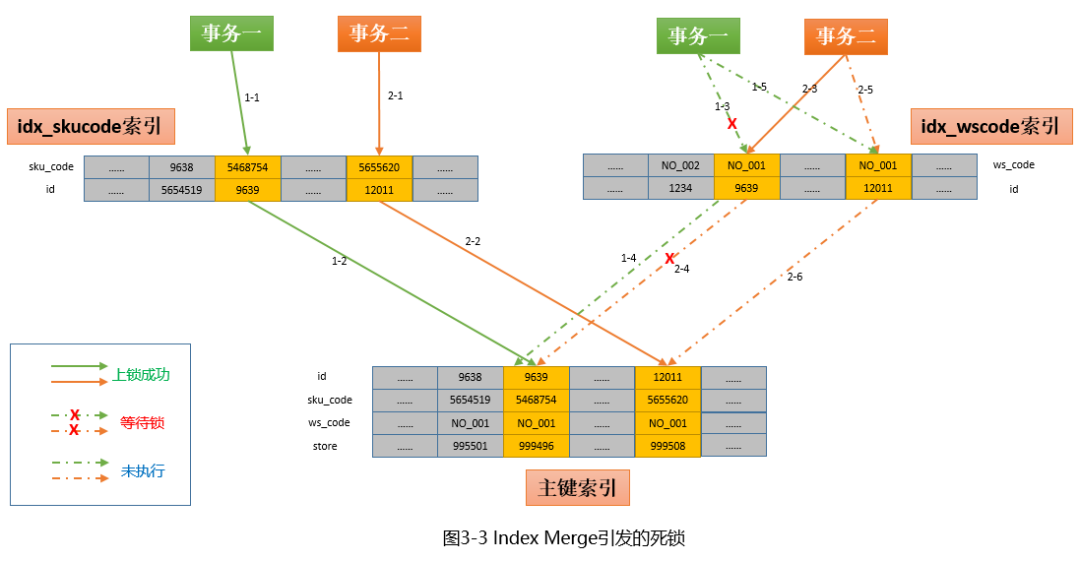
上图描述的只是发生死锁的一条可能路径,实际上仔细梳理的话还有其他路径也会导致死锁,大家感兴趣可以自己探索。上图解释如下:
1)事务一(where sku_code='5468754' and ws_code = 'NO_001' )首先走idx_skucode索引,分别对二级索引和主键索引加锁成功(1-1和1-2)。
2)此时事务二开始执行( where sku_code='5655620' and ws_code = 'NO_001' ),首先也是走idx_skucode(左上)索引,因为和事务一所加锁的记录不冲突,所以也顺利加锁成功(2-1和2-2)。
3)事务二继续执行,这时走的是idx_wscode(右上)索引,先对二级索引加锁成功(2-3,此时事务一还没有开始在idx_wscode上加锁),但是在对主键索引加索引时,发现id=9639的主键索引已经被事务一上锁,因此只能等待(2-4),同时在2-4完成加锁前,对其他记录的加锁也会暂停(2-5和2-6,因为InnoDB是逐条记录加锁的,前一条未完成则后面的不会执行)。
4)此时事务一继续执行,这时走的是idx_wscode索引,但是加锁的时候发现(NO_001,9639)这条索引项已经被事务二上锁,所以也只能等待。同理,后面的1-4也无法执行。
到此就出现了“两个事务,反向加锁"导致的死锁现象。
四、如何解决
死锁的本质原因还是由加锁顺序不同所导致,本例中是由于Index Merge同时使用2个索引方向加锁所导致,解决方法也比较简单,就是消除因index merge带来的多个索引同时执行的情况。
1)利用force index(idx_skucode)强制走某个索引,这样InnoDB就会忽略index merge,避免多个索引同时加锁的情况。

图4-1 使用Force Index强制指定索引
2)禁用Index Merge,这样InnoDB只会使用idx_skucode和idx_wscode中的一个,所有事物加锁顺序都一样,不会造成死锁。
用命令禁用Index Merge:SET GLOBAL optimizer_switch='index_merge=off,index_merge_union=off,index_merge_sort_union=off,index_merge_intersection=off';

图4-2 关闭Index Merge特性
重新登录终端后再看下执行计划:

图4-3 关闭Index Merge后索引情况
3)既然Index Merge同时使用了2个独立索引,我们不妨新建一个包含这两个索引所有字段的联合索引,这样InnoDB就只会走这个单独的联合索引,这其实和禁用index merge是一个道理。
新增联合索引:
alter table store add index
idx_skucode_wscode(sku_code,ws_code);
再看下执行计划,type=range说明没有使用index merge,另外key=idx_skucode_wscode说明走的是刚刚创建的联合索引:

图4-4 利用联合索引来避免Index Merge优化
4)最后推荐另外一种绕过index merge限制的方式。即去除死锁产生的条件,具体方法是先利用idx_skucode和idx_wscode查询到主键id,再拿主键id进行update操作。这种方式避免了由update引入X锁,由于最终更新的条件是唯一固定的,所以不存在加锁顺序的问题,避免了死锁的产生。
五、小结
本文通过一个实际案例描述了由于Index Merge优化导致的死锁,详细描述了死锁产生的原因以及解决方案,并顺便介绍了 MySQL 索引结构及加锁机制。通过本文,大家可以掌握死锁分析的基本理论和一般方法,希望能为大家工作中快速解决实际出现的死锁问题提供思路。
作者:vivo 官网商城开发团队











