推荐
专栏
教程
课程
飞鹅
本次共找到5条
urllib2
相关的信息
浅梦一笑
•
4年前
分别用python2和python3伪装浏览器爬取网页内容
python网页抓取功能非常强大,使用urllib或者urllib2可以很轻松的抓取网页内容。但是很多时候我们要注意,可能很多网站都设置了防采集功能,不是那么轻松就能抓取到想要的内容。今天我来分享下载python2和python3中都是如何来模拟浏览器来跳过屏蔽进行抓取的。最基础的抓取:!/usr/bin/envpythoncodingutf8@Au
风花雪月
•
4年前
申请软件著作权(代码太短的问题)
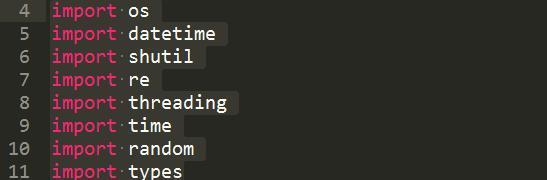
可以把importos,sys,urllib2等里面的代码也整理出来毕竟代码里面用到的importos(代码提取出来)importdatetime(代码提取出来)importshutil(代码提取出来)importre(代码提取出来)importthreading(代码提取出来)importtime(代码提取出来)importr
Stella981
•
4年前
Python调用API接口的几种方式
Python调用API接口的几种方式相信做过自动化运维的同学都用过API接口来完成某些动作。API是一套成熟系统所必需的接口,可以被其他系统或脚本来调用,这也是自动化运维的必修课。本文主要介绍python中调用API的几种方式,下面是python中会用到的库。\urllib2\httplib2\pycurl\reque
Stella981
•
4年前
Python爬虫:一些常用的爬虫技巧总结
用python也差不多一年多了,python应用最多的场景还是web快速开发、爬虫、自动化运维:写过简单网站、写过自动发帖脚本、写过收发邮件脚本、写过简单验证码识别脚本。爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情。1、基本抓取网页get方法import urllib2
Wesley13
•
4年前
urllib在某些情况下性能低于urllib2一例
再一次尝试将QQ空间的头像保存到本地的过程中,发现每次执行那段代码都要有大约将近20s左右的延时。这个延时对于正常来说是不可忍受的。尝试解决之。首先尝试用浏览器直接打开头像地址,发现没有任何延时,瞬间即开。看来问题是出现在了代码之上。为了方便,获取头像采用的是urllib.urlretrive方法。既然这个方法有问题,那用最原始的的urllib.open
1