
一、相关文档
老规矩,为了避免我的解释误导大家,请大家务必通过官网了解一波SQL SERVER的相关功能。
文档地址:
Change Data Capture:https://docs.microsoft.com/en-us/sql/relational-databases/track-changes/about-change-data-capture-sql-server?view=sql-server-2017
Change Tracking:https://docs.microsoft.com/en-us/sql/relational-databases/track-changes/about-change-tracking-sql-server?view=sql-server-2017
英文差的朋友可以把URL中的en-us改成zh-cn来看中文的文档
二、功能介绍
SQL SERVER内置提供了两种抓取数据变更的机制,一种叫Change Data Capture(下文简称CDC),另外一种叫Change Tracking(下文简称CT)。这两个功能能够在用户执行DML操作(插入、更新、删除)时,记录数据的变更。
他们的工作原理是,当对数据表进行操作时,SQL SERVER会记录事务日志,如果你启用了以上两个功能中的任意一个,SQL SERVER会使用SQL SERVER代理(一个独立的程序)来抓取这些日志,并记录到特定的表中(所以该方案会有额外的存储空间和服务器性能的开销),最终SQL SERVER提供了一系列的函数,来帮助使用者解析这些变更记录表,当然也有办法可以直接去读取这些变更记录。
需要注意的是,这些功能在2014及以下的版本中,需要企业版或者开发版中才会有这个功能,在SQL SERVER 2016 以上的版本中,标准版也内置了这个功能。
优势:
- 系统内置,无需自定义解决方案
- 数据表结构不需要调整,不需要添加标识列之类的东西
- CDC有内置的数据清除机制,对于过期后的LOG不需要自定义清除机制
- 该方案是异步的,虽说会对服务器性能有影响,但毕竟进程是独立的,这种影响比直接使用触发器之类的影响要小(不知道有没有方案把SQL SERVER代理部署到单独的机器上,知道的大佬可以说下)
- 更改是基于事务的提交,更改的顺序就是事务提交的时间,该方案获取的变更顺序一定是可靠的。
- SQL SERVER提供了可配置和管理的一些工具
工作原理:
这里主要是实战为主,所以只放官网的两张图片大家自行感受~
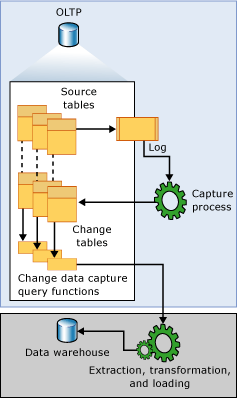
区别:
这两个功能的主要区别在于记录数据的格式,CDC更为详细一些,他会记录每条记录的每一次变更的详细内容,即变更前后,数据的每个字段的值。而CT则只是记录,这条记录发生了变更,具体的变更前后的内容不会被记录。
具体记录的内容下面会给大家做详细的介绍,请稍安勿躁~
三、准备工作
开启相关功能
除了本文外,可以参考博客园其他人写的文章:
https://www.cnblogs.com/maikucha/p/9039205.html
https://www.cnblogs.com/chenmh/p/4408825.html
1.添加专用文件组
在需要记录数据变更的数据上右键->属性->文件组,点击添加文件组,添加一个名为TDC的文件组。
2.添加数据库文件
切换到文件Tab页,然后点击添加按钮,新建一个文件,文件类型选择行数据,文件组选择刚才创建好的TDC文件组。
这一步是我从别的博主那边学到的,官方文档中没有前两步,当然你也可以忽略这两步,不过我个人的理解是这两步是为了避免和SQL SERVER主进程抢占mdf文件资源,如果和主进程使用同一个文件,可能会导致性能问题和并发的一些问题,具体可以在正式上PRD之前,多做一些测试。

3.启用SQL SERVER代理
在windows 服务里面找到SQL Server 代理服务,点击启动(必要的话设置成开机自动启动),最后在MSSQL连上数据库之后显示效果如下:

4.数据库级别启用相关功能
这些数据变更追踪功能默认都是关闭状态的,在使用这些功能的时候,首先需要在数据库级别启用这些功能。
启用数据库的CDC功能需要执行以下SQL:
USE MyDB
GO
EXEC sys.sp_cdc_enable_db
GO
启用数据库的CT功能需要执行以下SQL:
ALTER DATABASE JaxTest(数据库名称)
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
也可以在数据库上右键->属性->更改跟踪页面中配置:

5.表级别启用相关功能
数据库级别启用完成后,还需要在表级别也启用相关功能,启用过程如下:
我们先创建一张表:
CREATE TABLE Person
(
Id INT IDENTITY(1,1) PRIMARY KEY NOT NULL,
Name NVARCHAR(32) NOT NULL,
Age INT NOT NULL,
Remark NVARCHAR(512) NULL
)
启用CDC需要执行下面的SQL:
exec sys.sp_cdc_enable_table
[ @source_schema = ] 'source_schema', ---表所属的架构名,一般是dbo
[ @source_name = ] 'source_name' ,----表名
[ @role_name = ] 'role_name'---是用于控制更改数据访问的数据库角色的名称。
[,[ @capture_instance = ] 'capture_instance' ]--是用于命名变更数据捕获对象的捕获实例的名称,这个名称在后面的存储过程和函数中需要经常用到。
[,[ @supports_net_changes = ] supports_net_changes ]---指示是否对此捕获实例启用净更改查询支持如果此表有主键,或者有已使用 @index_name 参数进行标识的唯一索引,则此参数的默认值为 1。否则,此参数默认为 0。
[,[ @index_name = ] 'index_name' ]--用于唯一标识源表中的行的唯一索引的名称。index_name 为 sysname,并且可以为 NULL。如果指定,则 index_name 必须是源表的唯一有效索引。如果指定 index_name,则标识的索引列优先于任何定义的主键列,就像表的唯一行标识符一样。
[,[ @captured_column_list = ] 'captured_column_list' ]--需要对哪些列进行捕获。captured_column_list 的数据类型为 nvarchar(max),并且可以为 NULL。如果为 NULL,则所有列都将包括在更改表中。
[,[ @filegroup_name = ] 'filegroup_name' ]--是要用于为捕获实例创建的更改表的文件组。
[,[ @partition_switch = ] 'partition_switch' ]--指示是否可以对启用了变更数据捕获的表执行 ALTER TABLE 的 SWITCH PARTITION 命令。allow_partition_switch 为 bit,默认值为 1。
上面的内容可能有点啰嗦,举个实际例子吧,比如我要对Person这张表启用CDC,则执行的SQL如下:
EXEC sys.sp_cdc_enable_table
@source_name = 'Person',
@source_schema = 'dbo',
@capture_instance = 'dbo_Personal',
@filegroup_name = 'TDC',
@supports_net_changes = 1,
@role_name = NULL
启用CT需要执行下面的SQL:
ALTER TABLE dbo.Person(表名)
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON)
当然,也可以在数据表上右键->属性->变更跟踪 Tab页中进行启用。
到这里为止,就已经启用了数据库的CDC和CT两个功能,当然,实际大部分情况下,只需要根据需要,选择其中一种即可,这里只是都做一个说明。你可以只挑一个来进行实践。
使用CDC和CT功能进行变更抓取
1.使用CDC进行变更抓取
在我们先向表中插入一些数据,然后再修改、删除插入的这些数据,再使用SQL SERVER提供的相关SP来抓取这些变更。
本文中的数据变化过程如下:
首先新增三条数据:

然后修改成下面这样子:

最后再把第二条删掉:

此时,我们先使用CDC的相关脚本来查询所有变更:
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_Personal');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
SELECT * FROM cdc.fn_cdc_get_all_changes_dbo_Personal
(@from_lsn, @to_lsn, N'all update old');
GO
这段脚本中有两个地方用到了dbo_Personal这个名字,这个名字其实是在上面启用CDC的时候,指定的@capture_instance = 'dbo_Personal', 这个参数,如果你已经忘记了,可以翻到博客的上面回顾一下~
如果你已经忘记你执行的时候指定的这个参数名字,可以在DB的Function列表中找到它,都是以cdc.fn_cdc_get_all_changes开头的。
执行脚本后,会得到如下结果:

调用这个Function时候的参数含义和返回的每一列的含义可以参考微软官方文档:https://docs.microsoft.com/zh-cn/sql/relational-databases/system-functions/cdc-fn-cdc-get-all-changes-capture-instance-transact-sql?view=sql-server-2017,下面也给懒人朋友们截个图。


从这个LOG中,其实我们已经可以获得非常详细的我们每一次对Person这张表的操作了,而且可以发现,微软的这个顺序也已经是按照我们执行的SQL语句的顺序进行排列了,每一个字段每次的变更前后也记录的非常的清楚了。
此外,对于CDC,也可以抓取净变更记录,即再一段时间内,数据差异,并且把反复修改的中间过程会过滤掉,比如把某条记录的某个字段从A改成B,又从B改成A,这时候就会被忽略掉这个修改:
我们可以执行下面的SQL来抓取净变更:
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_Personal');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_Personal
(@from_lsn, @to_lsn, N'all ');
GO
最终得到的结果如下:

可以看到,对于Id为2的那条数据,是没有体现在这里的,因为他在这个过程中,是从新增变为了删除,相当于是没有变化的,所以这个函数获取出来就没有那条记录~
这个函数的相关参数以及返回列的含义请参考:https://docs.microsoft.com/en-us/sql/relational-databases/system-functions/cdc-fn-cdc-get-net-changes-capture-instance-transact-sql?view=sql-server-2017
2.使用CT进行变更抓取
使用CT进行变更抓取需要执行以下SQL:
SELECT *
FROM CHANGETABLE(CHANGES dbo.Person,0) AS CT
对于上面的操作记录来说,最终会得到以下结果:

可以看到CT记录的结果很简单,他只会记录哪些ID发生了变化,至于变更的内容是什么,他不会记录,但他会告诉你,你如果想同步这种变更到另外一个地方,需要使用的操作是Insert,Delete还是Update(SYS_CHANGE_OPERATION列),当然还有很多高级的用法,需要大家继续探索。
小结
本文主要讲了如何使用CDC的功能来抓取数据的变化,其实整体说的也比较浅,一是我自己对这个的认识也没用那么深,另外一方面是文章篇幅所限,本文的重点也不是将这些东西的各种用法讲清楚,我们的目的只有一个,就是将SQL SERVER中的数据同步到ES中。所以,下篇文章我们将直接使用今天说到的这些功能,结合一些其他的函数,来将数据尝试导入到ES中。
天色已晚,上床睡觉保头发~











