
参考:https://blog.csdn.net/u012655441/article/details/64920825
C++中stack的用法
转载:xueruifan的博客
C++ Stack(堆栈) 是一个容器类的改编,为程序员提供了堆栈的全部功能,——也就是说实现了一个先进后出(FILO)的数据结构。
c++ stl栈stack的头文件为:
#include
c++ stl栈stack的成员函数介绍
操作 比较和分配堆栈
empty() 堆栈为空则返回真
pop() 移除栈顶元素
push() 在栈顶增加元素
size() 返回栈中元素数目
top() 返回栈顶元素
栈(stack)是限制插入和删除只能在一个位置上进行的线性表,该位置在表的末端,叫做栈顶。添加元素只能在尾节点后添加,删除元素只能删除尾节点,查看节点也只能查看尾节点。添加、删除、查看依次为入栈(push)、出栈(pop)、栈顶节点(top)。形象的说,栈是一个先进后出(LIFO)表,先进去的节点要等到后边进去的节点出来才能出来。
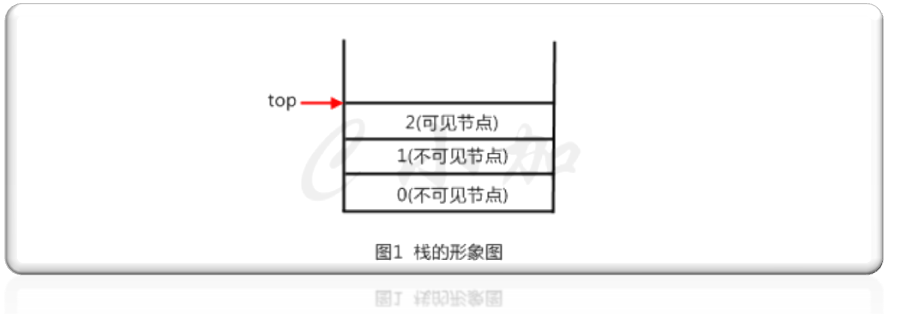
如图1,是一个栈的形象图,top指针指向的是栈顶节点,所以我们可以通过top访问到2节点,但是0和1节点由于先于2进入这个表,所以是不可见的。如果把0节点当做头节点,2节点当做尾节点,那么栈限制了访问权限,只可以访问尾节点。
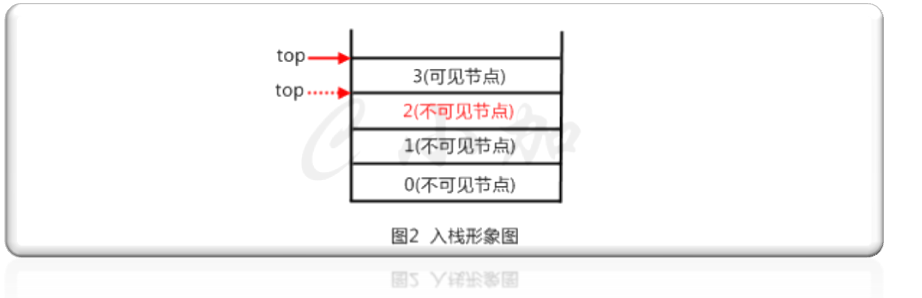
如图2,当添加一个节点3的时候,只能在栈顶节点,也就是尾节点后添加,这样3节点变成了栈顶,2节点变成了不可见节点,访问的时候只能访问到3节点。入栈时限制了插入地址,只能在栈顶添加节点。
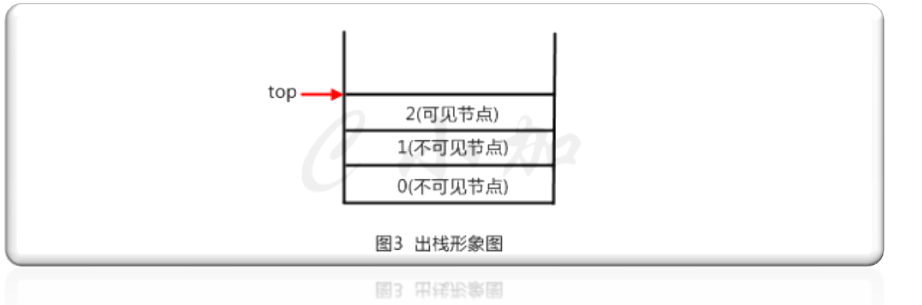
当我们执行出栈的命令时,图2的栈顶元素是3节点,删除的时候只能允许删除栈顶的元素,这样子3节点被删除,top指向删除后的栈顶2节点,如图3所示。
栈有两种是实现结构,一种是顺序存储结构,也就是利用数组实现,一种是链式存储结构,可以用单链表实现。数组实现栈很简单,用一个下标标记top来表示栈顶,top==-1时,栈空,top==0时,表示栈里只有一个元素,通过访问top为下标的数组元素即可。出栈top自减,入栈top自加就OK了。
单链表实现栈要比单链表的实现简单点。我们通过在表的尾端插入来实现push,通过删除尾节点来实现pop,获取尾节点的元素来表示top。我修改了链表那一章的单链表代码,把头节点当做栈顶节点,实现了一个简单的栈模板,仅供学习所用。代码会不定时更新。代码下载











