
Nebula Graph 是一个高性能的分布式开源图数据库,本文为大家介绍 Nebula Graph 的整体架构。
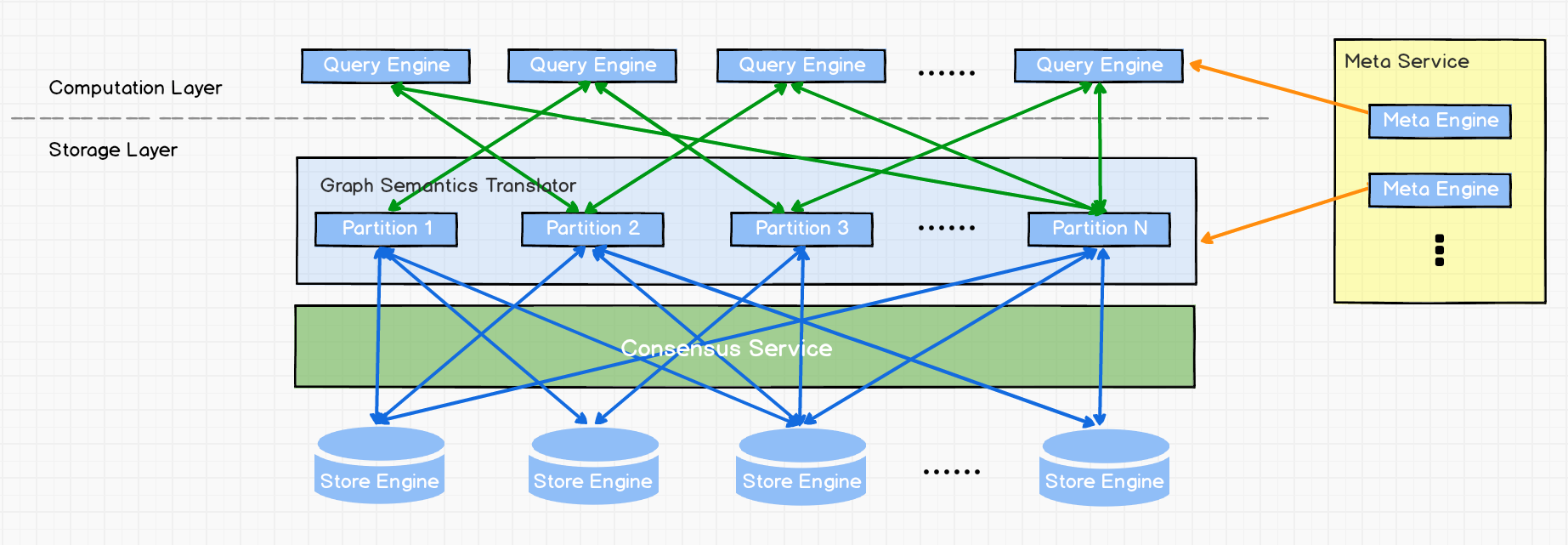
一个完整的 Nebula 部署集群包含三个服务,即 Query Service,Storage Service 和 Meta Service。每个服务都有其各自的可执行二进制文件,这些二进制文件既可以部署在同一组节点上,也可以部署在不同的节点上。
Meta Service
上图为 Nebula Graph 的架构图,其右侧为 Meta Service 集群,它采用 leader / follower 架构。Leader 由集群中所有的 Meta Service 节点选出,然后对外提供服务。Followers 处于待命状态并从 leader 复制更新的数据。一旦 leader 节点 down 掉,会再选举其中一个 follower 成为新的 leader。
Meta Service 不仅负责存储和提供图数据的 meta 信息,如 schema、partition 信息等,还同时负责指挥数据迁移及 leader 的变更等运维操作。
存储计算分离
在架构图中 Meta Service 的左侧,为 Nebula Graph 的主要服务,Nebula 采用存储与计算分离的架构,虚线以上为计算,以下为存储。
存储计算分离有诸多优势,最直接的优势就是,计算层和存储层可以根据各自的情况弹性扩容、缩容。
存储计算分离还带来的另一个优势:使水平扩展成为可能。
此外,存储计算分离使得 Storage Service 可以为多种类型的个计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的计算层,而各种迭代计算框架会是另外一个计算层。
无状态计算层
现在我们来看下计算层,每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 meta 信息,以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。
计算层的负载均衡有两种形式,最常见的方式是在计算层上加一个负载均衡(balance),第二种方法是将计算层所有节点的 IP 地址配置在客户端中,这样客户端可以随机选取计算节点进行连接。
每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。
Shared-nothing 分布式存储层
Storage Service 采用 shared-nothing 的分布式架构设计,每个存储节点都有多个本地 KV 存储实例作为物理存储。Nebula 采用多数派协议 Raft 来保证这些 KV 存储之间的一致性(由于 Raft 比 Paxo 更简洁,我们选用了 Raft )。在 KVStore 之上是图语义层,用于将图操作转换为下层 KV 操作。
图数据(点和边)是通过 Hash 的方式存储在不同 Partition 中。这里用的 Hash 函数实现很直接,即 vertex_id 取余 Partition 数。在 Nebula Graph 中,Partition 表示一个虚拟的数据集,这些 Partition 分布在所有的存储节点,分布信息存储在 Meta Service 中(因此所有的存储节点和计算节点都能获取到这个分布信息)。
附录
Nebula Graph GitHub 地址:https://github.com/vesoft-inc/nebula ,加入 Nebula Graph 交流群,请联系 Nebula Graph 官方小助手微信号:NebulaGraphbot
Nebula Graph:一个开源的分布式图数据库。











