
楔子
前面一小节我们以一个真实的压测案例来给大家讲解如何利用 Node.js 性能平台 生成的 CPU Profile 分析来进行压测时的性能调优。那么与 CPU 相关的问题相比,Node.js 应用中由于不当使用产生的内存问题是一个重灾区,而且这些问题往往都是出现在生产环境下,本地压测都难以复现,实际上这部分内存问题也成为了很多的 Node.js 开发者不敢去将 Node.js 这门技术栈深入运用到后端的一大阻碍。
本节将以一个开发者容易忽略的生产内存溢出案例,来展示如何借助于性能平台实现对线上应用 Node.js 应用出现内存泄漏时的发现、分析、定位问题代码以及修复的过程,希望能对大家有所启发。
本书首发在 Github,仓库地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,云栖社区会同步更新。
最小化复现代码
因为内存问题相对 CPU 高的问题来说比较特殊,我们直接从问题排查的描述可能不如结合问题代码来看比较直观,因此在这里我们首先给出了最小化的复现代码,大家运行后结合下面的分析过程应该能更有收获,样例基于 Egg.js:如下所示:
'use strict';
const Controller = require('egg').Controller;
const DEFAULT_OPTIONS = { logger: console };
class SomeClient {
constructor(options) {
this.options = options;
}
async fetchSomething() {
return this.options.key;
}
}
const clients = {};
function getClient(options) {
if (!clients[options.key]) {
clients[options.key] = new SomeClient(Object.assign({}, DEFAULT_OPTIONS, options));
}
return clients[options.key];
}
class MemoryController extends Controller {
async index() {
const { ctx } = this;
const options = { ctx, key: Math.random().toString(16).slice(2) };
const data = await getClient(options).fetchSomething();
ctx.body = data;
}
}
module.exports = MemoryController;
然后在 app/router.js 中增加一个 Post 请求路由:
router.post('/memory', controller.memory.index);
造成问题的 Post 请求 Demo 这里也给出来,如下所示:
'use strict';
const fs = require('fs');
const http = require('http');
const postData = JSON.stringify({
// 这里的 body.txt 可以放一个比较大 2M 左右的字符串
data: fs.readFileSync('./body.txt').toString()
});
function post() {
const req = http.request({
method: 'POST',
host: 'localhost',
port: '7001',
path: '/memory',
headers: {
'Content-Type': 'application/json',
'Content-Length': Buffer.byteLength(postData)
}
});
req.write(postData);
req.end();
req.on('error', function (err) {
console.log(12333, err);
});
}
setInterval(post, 1000);
最后我们在启动完成最小化复现的 Demo 服务器后,再运行这个 Post 请求的客户端,1s 发起一个 Post 请求,在平台控制台可以看到堆内存在一直增加,如果我们按照本书工具篇中的 Node.js 性能平台使用指南 - 配置合适的告警 一节中配置了 Node.js 进程堆内存告警的话,过一会就会收到平台的 短信/邮件 提醒。
问题排查过程
收到性能平台的进程内存告警后,我们登录到控制台并且进入应用首页,找到告警对应实例上的问题进程,然后参照工具篇中的 Node.js 性能平台使用指南 - 内存泄漏 中的方法抓取堆快照,并且点击 分析 按钮查看 AliNode 定制后的分解结果展示:
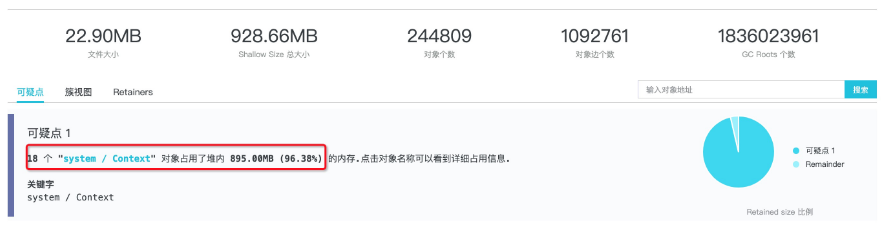
这里默认的报表页面顶部的信息含义已经提到过了,这里不再重复,我们重点来看下这里的可疑点信息:提示有 18 个对象占据了 96.38% 的堆空间,显然这里就是我们需要进一步查看的点。我们可以点击 对象名称 来看到这18 个 system/Context 对象的详细内容:
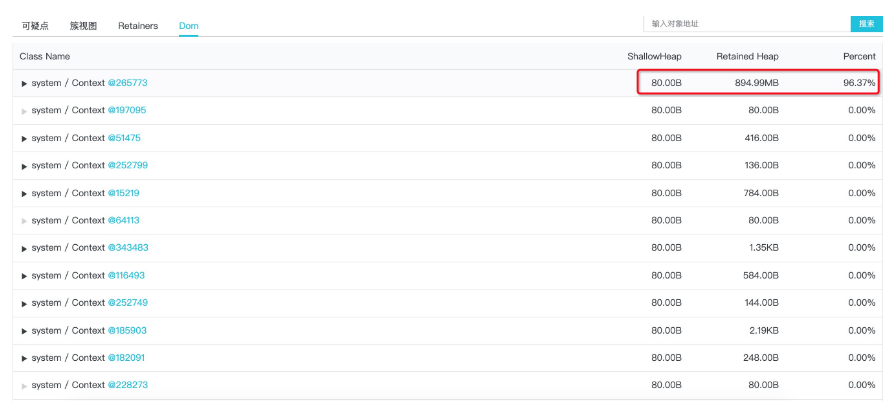
这里进入的是分别以这 18 个 system/Context 为根节点起始的支配树视图,因此展开后可以看到各个对象的实际内存占用情况,上图中显然问题集中在第一个对象上,我们继续展开查看:
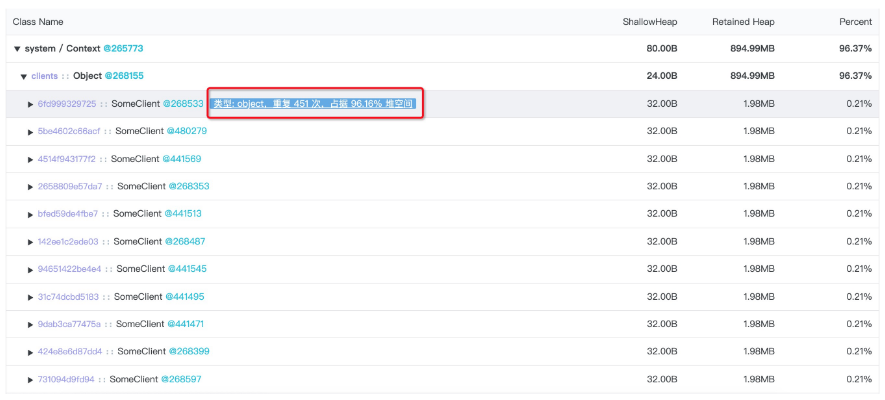
很显然,这里真正吃掉堆空间的是 451 个 SomeClient 实例,面对这样的问题我们需要从两个方面来判断这是否真的是内存异常的问题:
- 当前的 Node.js 应用在正常的逻辑下,是否单个进程需要 451 个 SomeClient 实例
- 如果确实需要这么多 SomeClient 实例,那么每个实例占据 1.98MB 的空间是否合理
对于第一个判断,在对应的实际生产面临的问题中,经过代码逻辑的重新确认,我们的应用确实需要这么多的 Client 实例,显然此时排查重点集中在每个实例的 1.98MB 的空间占用是否合理上,假如进一步判断还是合理的,这意味着 Node.js 默认单进程 1.4G 的堆上限在这个场景下是不适用的,需要我们来通过启动 Flag 调大堆上限。
正是基于以上的判断需求,我们继续点开这些 SomeClient 实例进行查看:
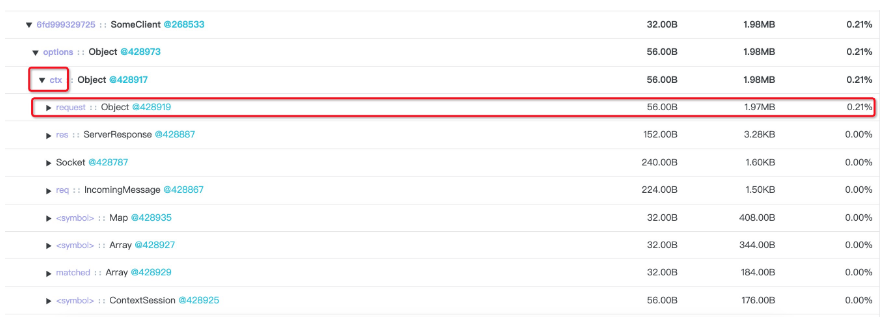
这里可以很清晰的看到,这个 SomeClient 本身只有 1.97MB 的大小,但是下面的 options 属性对应的 Object@428973 对象一个就占掉了 1.98M,进一步展开这个可疑的 Object@428973 对象可以看到,其 ctx 属性对应的 Object@428919 对象正是 SomeClient 实例占据掉如此大的对空间的根本原因所在!
我们可以点击其它的 SomeClient 实例,可以看到每一个实例均是如此,此时我们需要结合代码,判断这里的 options.ctx 属性挂载到 SomeClient 实例上是否也是合理的,点击此问题 Object 的地址:

进入到这个 Object 的关系图中:
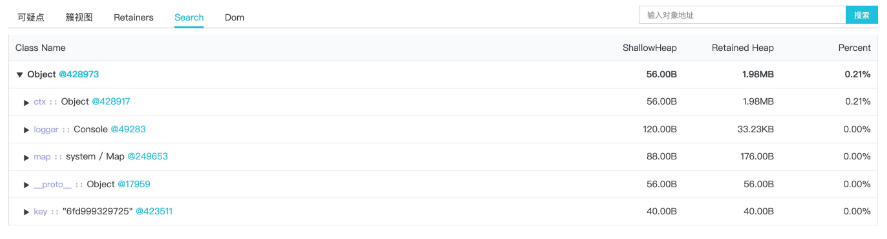
Search 展示的视图不同于 Dom 结果图,它实际上展示的是从堆快中解析出来的原始对象关系图,所以边信息是一定会存在的,靠边名称和对象名称,我们比较容易判断对象在代码中的位置。
但是在这个例子中,仅仅依靠以 Object@428973 为起始点的内存原始关系图,看不到很明确的代码位置,毕竟不管是 Object.ctx 还是 Object.key 都是相当常见的 JavaScript 代码关系,因此我们继续点击 Retainer 视图:

得到如下信息:
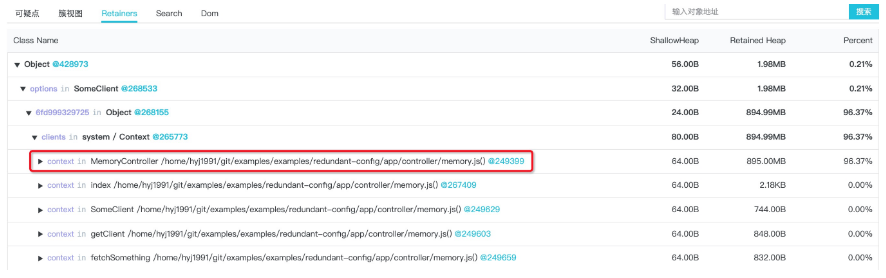
这里的 Retainer 信息和 Chrome Devtools 中的 Retainer 含义是一样的,它代表了节点在堆内存中的原始父引用关系,正如本文的内存问题案例中,仅靠可疑点本身以及其展开无法可靠地定位到问题代码的情况下,那么展开此对象的 Retainer 视图,可以看到它的父节点链路可以比较方便的定位到问题代码。
这里我们显然可以通过在 Retainer 视图下的问题对象父引用链路,很方便地找到代码中创建此对象的代码:
function getClient(options) {
if (!clients[options.key]) {
clients[options.key] = new SomeClient(Object.assign({}, DEFAULT_OPTIONS, options));
}
return clients[options.key];
}
结合看 SomeClient 的使用,看到用于初始化的 options 参数中实际上只是用到了其 key 属性,其余的属于冗余的配置信息,无需传入。
代码修复与确认
知道了原因后修改起来就比较简单了,单独生成一个 SomeClient 使用的 options 参数,并且仅将需要的数据从传入的 options 参数上取过来以保证没有冗余信息即可:
function getClient(options) {
const someClientOptions = Object.assign({ key: options.key }, DEFAULT_OPTIONS);
if (!clients[options.key]) {
clients[options.key] = new SomeClient(someClientOptions);
}
return clients[options.key];
}
重新发布后运行,可以到堆内存下降至只有几十兆,至此 Node.js 应用的内存异常的问题完美解决。
结尾
本节中也比较全面地给大家展示了如何使用 Node.js 性能平台 来排查定位线上应用内存泄漏问题,其实严格来说本次问题并不是真正意义上的内存泄漏,像这种配置传递时开发者图省事直接全量 Assign 的场景我们在写代码时或多或少时都会遇到,这个问题带给我们的启示还是:当我们去编写一个公共组件模块时,永远不要去相信使用者的传入参数,任何时候都应当只保留我们需要使用到的参数继续往下传递,这样可以避免掉很多问题。
原文链接
本文为云栖社区原创内容,未经允许不得转载。











