经典的架构设计可以跨越时间和语言,得以传承。
—— 题记
一、背景
悟空活动中台技术文章系列又和大家见面了,天气渐冷,注意保暖。
在往期的系列技术文章中我们主要集中分享了前端技术的方方面面,如微组件的状态管理,微组件的跨平台探索,以及有损布局,性能优化等等。还未关注到的同学,如果感兴趣可以查看往期文章。
今天的技术主题要有点不一样,让我们一起来聊聊悟空活动中台在应用服务层的一些技术建设。
在悟空活动中台的技术架构设计中,我们充分拥抱 JavaScript 生态,希望推进 JavaScript 的全栈开发流程,所以在应用层的服务端,我们选择了 Node 作为 BFF(Backend For Fronted) 层解决方案。
希望借此来充分发挥JavaScript 的效能,可以更高效、更高质量的完成产品的迭代。
通过实践发现 JavaScript 全栈的开发流程给我们带来的好处:
前后端使用 JavaScript 来构建,使得前后端更加融合且高效。前后端代码的复用中部分模块和组件不仅仅可以在前端使用,也可以在后端使用。
减少了大量的沟通成本。围绕着产品的需求设计和迭代,前端工程师在前端和后端的开发上无缝的切换,保证业务的快速落地。
开发者全局开发的视角。让前端的工程师有机会从产品、前端、后端的视角去思考问题和技术的创新。
当然 Node 只是服务应用开发的一部分。当我们需要存储业务数据时,我们还需要一个数据的持久化解决方案。悟空活动中台选择成熟又可靠的 MySQL 来作为我们的数据存储数据库。那我们就需要思考 Node 和 MySQL 如何搭配才能更好的释放彼此的能力,接下来让我们一起走上探索之路。
二、Node 数据持久层现状与思考
1、纯粹的 MySQL 驱动
Node-MySQL是 Node 连接 MySQL的驱动,使用纯 JavaScript 开发,避免了底层的模块编译。让我们看看如何使用它,首先我们需要安装这个模块。
示例如下:
npm install mysql # 之前0.9的版本需要这样安装 npm install mysqljs/mysql
常规使用过程如下:
var mysql = require('mysql');
var connection = mysql.createConnection({
host : '..', // db host
user : '..', // db user
password : '', // db password
database : '..' // which database
});
connection.connect();
connection.query(
'SELECT id, name, rank FROM lanaguges',
function (error, results, fields) {
if (error) throw error;
/**
* 输出:
* [ RowDataPacket {
* id: 1,
* name: "Java",
* rank: 1
* },
* RowDataPacket {
* id: 2,
* name: "C",
* rank: 2
* }
*]
*
*
*/
console.log('The language rank is: ', results);
});
connection.end();
通过上述的例子,我们对 MySQL 模块的使用方式有个简单的了解,基本的使用方式就是创建连接,执行 SQL 语句,得到结果,关闭连接等。
在实际的项目中我们很少直接使用该模块,一般都会在该模块的基础上进行封装,如:
- 默认使用数据库连接池的方式来提升性能。
- 改进callback的回调函数的风格,迁移到 promise,async/await 更现代化 JavaScript 的异步处理方案。
- 使用更加灵活的事务的处理。
- 针对复杂 SQL 的编写,通过字符串拼接的方式是比较痛苦的,需要更语义化的 SQL 编写能力。
2、主流的 ORM
目前在数据持久层技术解决方案中 ORM 仍然主流的技术方案,ORM是"对象-关系映射"(Object/Relational Mapping)的缩写,简单来说ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术,如图-1。
无论是 Java 的 JPA 技术规范以及 Hibernate 等技术实现,或者 Ruby On Rails 的 ActiveRecord,亦或 Django 的 ORM。几乎每个语言的生态中都有自己的ORM 的技术实现方案。
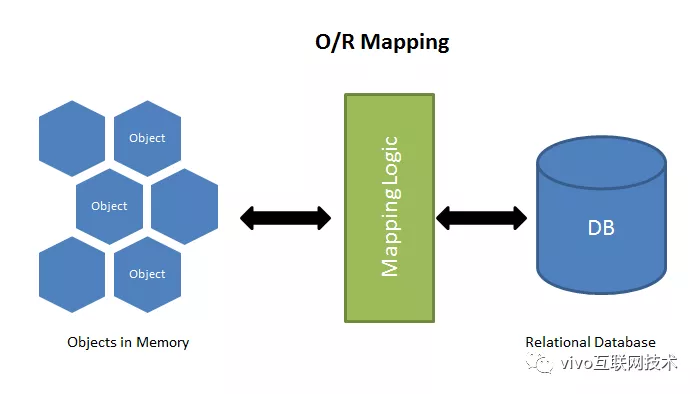
图-1 O/R Mapping
ORM 把数据库映射成对象:
- 数据库的表(table) => 类(class)
- 记录(row,行数据)=> 对象(object)
- 字段(field)=> 对象的属性(attribute)
Node 在 ORM 的技术方案上,社区有不同的角度的探索,充分体现了社区的多样性,比如目前非常流行的 Sequelize。Sequelize 是一个基于 Promise 的 Node.js ORM, 目前支持 PostgreSQL、MySQL、SQLite 以及 SQL-Server。它具有强大的事务支持、关联关系、预读、延迟加载、读取复制等功能。如上述 MySQL 使用的案例,若使用Sequelize ORM方式来实现,代码如下:
// 定义ORM的数据与model映射
const Language = sequelize.define('language', {
// 定义id, int型 && 主键
id: {
type: DataTypes.INTEGER,
primaryKey: true
},
// 定义name, string类型映射数据库varchar
name: {
type: DataTypes.STRING,
},
// 定义rank, string类型映射数据库varchar
range: {
type: DataTypes.INTEGER
},
}, {
// 不生成时间戳
timestamps: false
});
// 查询所有
const languages = await Language.findAll()
3、未来之星 TypeORM
自从有了 TypeScript 之后,让我们从另外一个视角去看待前端的工具链和生态,TypeScript 的类型体系给了我们更多的想象,代码的静态检查纠错、重构、自动提示等。带着这些新视角出现了社区比较热捧的 TypeORM。也非常值得我们借鉴学习。

图-2 TypeORM
TypeORM 充分结合 TypeScript,提供更好的开发体验。其目标是始终支持最新的 JavaScript 功能,并提供其他功能来帮助您开发使用数据库的任何类型的应用程序,从带有少量表的小型应用程序到具有多个数据库的大型企业应用程序。
与现有的所有其他 JavaScript ORM 不同,TypeORM 支持 Active Record (RubyOnRails 的 ORM 的核心)和 Data Mapper (Django 的 ORM 的核心设计模式)模式,这意味着我们可以以最有效的方式编写高质量、松散耦合、可伸缩、可维护的应用程序。
4、理性思考
在众所周知软件开发中,并不存在真正的银弹方案,ORM 给我们带来了更快的迭代速度,也还是存在一些不足。体现在:
- 对于简单的场景 CRUD 非常快,对于多表和复杂关联查询就会有点力不从心。
- ORM 库不是轻量级工具,需要花很多精力学习和设置。
- 对于复杂的查询,ORM 要么是无法表达,要么是性能不如原生的 SQL。
- ORM 抽象掉了数据库层,开发者无法了解底层的数据库操作,也无法定制一些特殊的 SQL。
- 容易产生N+1查询的问题。
我们开始思考怎么在 ORM 的基础上,保留强悍的 SQL 的表达能力呢?最终,我们把目光停留在了 Java 社区非常流行的一款半自动化的 ORM 的框架上面 MyBatis。
三、悟空活动中台在数据持久层的探索
通过思考,我们回归原点重新审视这个问题,我们认为 SQL 是程序和数据库交互最好的领域语言,简单易学通用性强且无需回避 SQL 本身。同时 MyBatis 的架构设计给与我们启发,在技术上是可以做到保留 SQL 的灵活强大,同时兼顾从 SQL 到对象的灵活映射。
1、什么是 MyBatis ?
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。MyBatis 的最棒的设计就是在对象的映射和原生 SQL 强大之间取得了很好的平衡。
SQL 配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.mybatis.example.BlogMapper">
<select id="selectBlog" resultType="Blog">
select name from blog where id = #{id}
</select>
SQL 查询
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
于是我们开始构建 Node 的 MyBatis,技术上实现的 Node-MyBatis 具有的特性:
- 简单易学。代码实现小而简单。没有任何第三方依赖,易于使用。
- 灵活。Node-Mybatis 不会对应用程序或者数据库的现有设计强加任何影响。借助 ES6 的 string template编写 SQL,灵活直接。
- 解除 SQL 与程序代码的耦合。
通过提供 DAO 层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。
- 支持动态 SQL 。避免 SQL 的字符串拼接。
- 防止 SQL 注入。自动对动态参数进行 SQL 防注入。
- 声明式事务机制。借助 decorator 更容易进行事务声明。
- 结合 Typescript 的类型。根据数据的表格结构自动生成数据的类型定义文件,代码提升补齐,提升开发体验。
2、Node-MyBatis 解决方案
在我们业务开发中,我们构建的 SQL 肯定需要根据业务进行判断和动态拼接,如果每条 SQL 都自己手动的拼接又回到了 MySQL 朴素的模式,一不小心就造成了大量的 SQL 注入等问题,那我们怎么办呢?这个时候就需要呼唤出 Node-MyBatis 的动态 SQL 的 uilder 模式了。
(1)SQL-Builder
# 表达式
#:针对动态 SQL中的占位符,我们最经常碰到的场景就是字符串的占位符,# 后面就是将来动态替换的变量的名称。如:
SELECT
id as id,
book_name as bookName
publish_time as publishTime
price as price
FROM t_books t
WHERE
t.id = #data.id AND t.book_name = #data.bookName
-- 该 SQL 通过 Node-MyBatis 底层的 SQL Compile 解析之后,生成的 SQL如下,
-- data 参数为: {id: '11236562', bookName: 'JavaScript红皮书' }
SELECT
id as id,
book_name as bookName
publish_time as publishTime
price as price
FROM t_books t
WHERE
t.id = '11236562' AND t.book_name = 'JavaScript红皮书'
$ 表达式
$: 动态数据的占位符,该占位符会在我们的 sql template 编译后将变量的值动态插入 SQL ,如下:
SELECT
id, name, email
FROM t_user t
WHERE t.state=$data.state AND t.type in ($data.types)
-- 该 SQL 通过 Node-MyBatis 底层的 SQL Compile 解析之后,生成的 SQL如下
-- data 参数为: {state: 1, types: [1,2,3]}
SELECT
id, name, email
FROM t_user t
WHERE t.state=0 AND t.type in (1,2,3)
<%%> 代码块
模板也是语言,那就是图灵完备的,循环、分支结构都是必不可少的。我们需要提供动态的编程的能力来应对更加复杂的 SQL 场景,那如何进行代码块的标记呢?悟空采用类似 EJS 模板的语法特征 <%%> 进行代码标记,并且来降低了 SQL 模版学习的难度。下面演示在 SQL 模板中的使用方法。
-- 循环
SELECT
t1.plugin_id as pluginId,
t1.en_name as pluginEnName,
t1.version as version,
t1.state as state
FROM test_npm_list t1
WHERE t1.state = '0'
<% for (let [name, version] of data.list ) { %>
AND t1.en_name = #name AND t1.version=#version
<% } %>
-- 分支判断
SELECT
id,
name,
age
FROM users
WHERE name like #data.name
<% if(data.age > 10) {%>
AND age = $data.age
<% } %>
那如何实现上述的功能呢?
我们通过借助 ES6 的 String Template 可以实现一个非常精简的模板系统。下面我们来通过模板字符串输出模板结果的案例。
let template = `
<ul>
<% for(let i=0; i < data.users.length; i++) { %>
<li><%= data.users[i] %></li>
<% } %>
</ul>
`;
上面代码在模板字符串之中,放置了一个常规模板。该模板使用 <%...%> 放置 JavaScript 代码,使用 <%= ... %> 输出 JavaScript 表达式。怎么编译这个模板字符串呢?思路是将其转换为 JavaScript 表达式字符串,目标就是转化为下述字符串。
print('<ul>');
for(let i = 0; i < data.users.length; i++) {
print('<li>');
print(data.users[i]);
print('</li>');
};
print('</ul>');
第一:采用了正则表达式进行匹配转化。
let evalExpr = /<%=(.+?)%>/g;
let expr = /<%([\s\S]+?)%>/g;
template = template
.replace(evalExpr, '`); \n print( $1 ); \n echo(`')
.replace(expr, '`); \n $1 \n print(`');
template = 'print(`' + template + '`);';
console.log(template);
// 输出
echo(`
<ul>
`);
for(let i=0; i < data.supplies.length; i++) {
echo(`
<li>`);
echo( data.supplies[i] );
echo(`</li>
`);
}
echo(`
</ul>
`);
第二:将 template 正则封装在一个函数里面返回。这样就实现了模板编译的能力,完整代码如下:
function compile(template){
const evalExpr = /<%=(.+?)%>/g;
const expr = /<%([\s\S]+?)%>/g;
template = template
.replace(evalExpr, '`); \n print( $1 ); \n echo(`')
.replace(expr, '`); \n $1 \n print(`');
template = 'print(`' + template + '`);';
let script =
`(function parse(data){
let output = "";
function print(html){
output += html;
}
${ template }
return output;
})`;
return script;
}
第三:通过 compile 函数,我们获取到了一个 SQL Builder的 高阶函数,传递参数,即可获取最终的 SQL 模板字符串。
let parse = eval(compile(template));
parse({ users: [ "Green", "John", "Lee" ] });
// <ul>
// <li>Green</li>
// <li>John</li>
// <li>Lee</li>
// </ul>
根据这种模板的思路,我们设计自己的 sqlCompile 来生成 SQL 的代码。
sqlCompile(template) {
template =
'print(`' +
template
// 解析#动态表达式
.replace(/#([\w\.]{0,})(\W)/g, '`); \n print_str( $1 ); \n print(`$2')
// 解析$动态表达式
.replace(/\$([\w\.]{0,})(\W)/g, '`); \n print( $1 ); \n print(`$2')
// 解析<%%>动态语句
.replace(/<%([\s\S]+?)%>/g, '`); \n $1 \n print(`') +
'`);'
return `(function parse(data,connection){
let output = "";
function print(str){
output += str;
}
function print_str(str){
output += "\'" + str + "\'";
}
${template}
return output.replace(/[\\r\\n]/g,"");
})`
}
(2)SQL 防注入
SQL 支持拼接就可能存在 SQL 的注入可能性,Java 中 MyBatis $ 动态表达式的使用也是有注入风险的,因为 $ 可以置换变量不会被包裹字符引号,社区也不建议使用 $ 符号来拼接 SQL。对于 Node-MyBatis 来说,因为保留了 $ 的能力,所以需要处理 SQL 注入的风险。参考 MyBatis 的 Node-MyBatis 工具用法也比较简单,示例如下:
// data = {name: 1}
`db.name = #data.name` // => 字符替换,会被转义成 db.name = "1"
`db.name = $data.name` // => 完整替换,会被转义成 db.name = 1
注入场景
// SQL 模板
`SELECT * from t_user WHERE username = $data.name and paasword = $data.passwd`
// data 数据为 {username: "'admin' or 1 = 1 --'", passwd: ""}
// 这样通过 SQL注释构造 形成了SQL的注入
`SELECT * FROM members WHERE username = 'admin' or 1 = 1 -- AND password = ''`
// SQL 模板
`SELECT * from $data.table`
// data 数据为 {table: "user;drop table user"}
// 这样通过 SQL注释构造 形成了SQL的注入
`SELECT * from user;drop table user`
针对常见的拼接 SQL 的场景,我们就不一一叙述了。下面将从常见的不可避免的拼接常见入手,和大家讲解 Node-Mybatis 的规避方案。该方案使用 MySQL 内置的 escape 方法或 SQL 关键字拦截方法进行参数传值规避。
escape转义,使用 $ 的进行传值,模板底层会先走 escape 方法进行转义,我们用一个包含不同的数据类型的数据进行 escape 能力检测,如:
const arr = escape([1,"a",true,false,null,undefined,new Date()]);
// 输出
( 1,'a', true, false, NULL, NULL, '2019-12-13 16:19:17.947')
关键字拦截,在 SQL 需要使用到数据库关键字,如表名、列名和函数关键字 where、 sum、count 、max 、 order by 、 group by 等。若直接拼装 SQL 语句会有比较明显的 SQL 注入隐患。因此要约束 $ 的符号的使用值范围。特殊业务场景,如动态排序、动态查询、动态分组、动态条件判断等,需要开发人员前置枚举判断可能出现的确定值再传入SQL。Node-MyBatis 中默认拦截了高风险的 $ 入参关键字。
if(tag === '$'){
if(/where|select|sleep|benchmark/gi.test(str)){
throw new Error('$ value not allowed include where、select、sleep、benchmark keyword !')
}
//...
}
配置拦截,我们为了控制 SQL 的注入风险,在 SQL 查询时默认不支持多条语句的执行。MySQL 底层驱动也有相同的选项,默认关闭。在 MySQL 驱动的文档中提供了详细的解释如下:
Connection options - 连接属性
multipleStatements:
Allow multiple mysql statements per query. Be careful with this, it could increase the scope of SQL injection attacks. (Default: false)
每个查询允许多个mysql语句。 请注意这一点,它可能会增加SQL注入攻击的范围。 (默认值:false)
Node-MyBatis 中默认规避了多行执行语句的配置与 $ 共同使用的场景。
if(tag === '$'){
if(this.pool.config.connectionConfig.multipleStatements){
throw new Error('$ and multipleStatements mode not allowed to be used at the same time !')
}
//...
}
SQL 注入检测
sqlmap 是一个开源的渗透测试工具,可以用来进行自动化检测,利用 SQL 注入漏洞,获取数据库服务器的权限。它具有功能强大的检测引擎,针对各种不同类型数据库的渗透测试的功能选项,包括获取数据库中存储的数据,访问操作系统文件甚至可以通过外带数据连接的方式执行操作系统命令。sqlmap 支持 MySQL, Oracle, PostgreSQL, Microsoft SQL Server, Microsoft Access, IBM DB2, SQLite, Firebird, Sybase 和 SAP MaxDB 等数据库的各种安全漏洞检测。
sqlmap 支持五种不同的注入模式:
- 基于布尔的盲注 即可以根据返回页面判断条件真假的注入;
- 基于时间的盲注 即不能根据页面返回内容判断任何信息,用条件语句查看时间延迟语句是否执行(即页面返回时间是否增加)来判断;
- 基于报错注入 即页面会返回错误信息,或者把注入的语句的结果直接返回在页面中;
- 联合查询注入 可以使用union的情况下的注入;
- 堆查询注入可以同时执行多条语句的执行时的注入。
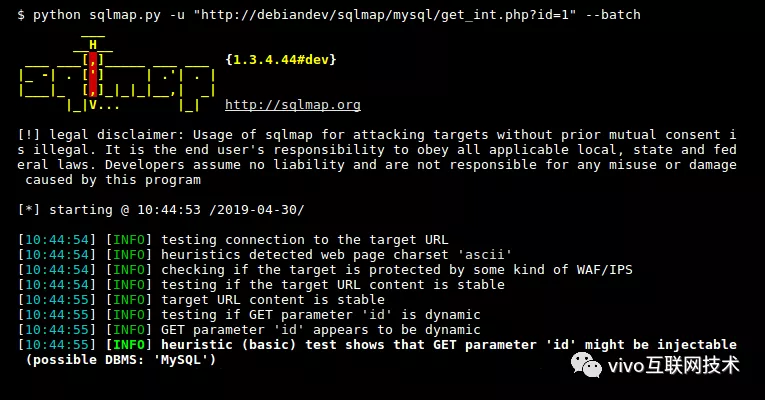
图-3 - SQLmap的使用
安装&使用
//安装方法
git clone --depth 1 https://github.com/sqlmapproject/sqlmap.git sqlmap-dev
//使用方法
sqlmap -u 'some url' --flush-session --batch --cookie="some cookie"
常用命令参数
- -u 设置想要验证的网站url
- --flush-session 清除过去的历史记录
- --batch 批量验证注入
- --cookie如果需要登录 设置cookie值
明确 sqlmap 使用方法后,我们在实际项目打包过程中可以基于 sqlmap 构建我们的自定义化测试脚本,在提交代码之后,通过 GitLab 的集成工具自动触发进行工程的验证。
(3)声明式事务
在 Node 和数据库的交互上,针对更新的 SQL 场景,我们需要对事务进行管理,手动管理事务比较费时费力,Node-MyBatis 提供了更好的事务管理机制,提供了声明式的事务管理能力,将我们从复杂的事务处理中解脱出来,获取连接、关闭连接、事务提交、回滚、异常处理等这些操作都将自动处理。
声明式事务管理使用了 AOP 实现的,本质就是在目标方法执行前后进行拦截。在目标方法执行前加入或创建一个事务,在执行方法执行后,根据实际情况选择提交或是回滚事务。不需要在业务逻辑代码中编写事务相关代码,只需要在配置文件配置或使用注解(@Transaction),这种方式没有侵入性。
在代码的实现上,我们使用 ES7 规范中装饰器的规范,来实现对目标类,方法,属性的修饰。装饰器的使用非常简单,其本质上就是一个函数包装。下面我们封装一个简单的 log 装饰器函数。
装饰类
function log(target, name, descriptor) {
console.log(target)
console.log(name)
console.log(descriptor)
}
@log
class User {
walk() {
console.log('I am walking')
}
}
const u = new User()
u.walk()
装饰方法
function log(target, name, descriptor) {
console.log(target)
console.log(name)
console.log(descriptor)
}
class Test {
@log // 装饰类方法的装饰器
run() {
console.log('hello world')
}
}
const t = new Test()
t.run()
装饰器函数有三个参数,其含义在装饰不同属性时表现也不用。在装饰类的时候,第一个参数表示类的函数本身。之前 log 输出如下:
[Function: User]
undefined
undefined
I am walking
在装饰类方法的时候,第一个参数表示类的原型( prototype ), 第二个参数表示方法名, 第三个参数表示被装饰参数的属性。之前 log 输出如下:
Test { run: [Function] }
run
{
value: [Function],
writable: true,
enumerable: true,
configurable: true
}
hello world
第三个 describe 参数内有如下属性:
- configurable - 控制是不是能删、能修改descriptor本身。
- writable - 控制是不是能修改值。
- enumerable - 控制是不是能枚举出属性。
- value - 控制对应的值,方法只是一个value是函数的属性。
- get和set - 控制访问的读和写逻辑。
实现机制
关于 ES7 的装饰器一些强大的特性和用法可以参考 TC39 的提案,这里就不累述。来看看我们 @Transaction 的实现:
// 封装高阶函数
function Transaction() {
// 返回代理方法
return (target, propetyKey, descriptor) => {
// 获取当前的代理方法
let original = descriptor.value;
// 拦截扩展方法
descriptor.value = async function (...args) {
try {
// 获取底层mysql的事务作用域
await this.ctx.app.mysql.beginTransactionScope(async (conn) => {
// 绑定数据库连接
this.ctx.conn = conn
// 执行方法
await original.apply(this, [...args]);
}, this.ctx);
} catch (error) {
// 错误处理...
this.ctx.body = {error}
}
};
};
}
在 Transaction 的装饰器中,我们使用底层 egg-mysql 对象扩展的 beginTransactionScope 自动控制,带作用域的事务 。
API:beginTransactionScope(scope, ctx)
scope: 一个 generatorFunction,它将执行此事务的所有SQL。
ctx: 当前请求的上下文对象,它将确保即使在嵌套的情况下事务,一个请求中同时只有一个活动事务。
const result = yield app.mysql.beginTransactionScope(function* (conn) { // 不需要手动处理事务开启和回滚 yield conn.insert(table, row1); yield conn.update(table, row2); return { success: true }; }, ctx); // ctx 执行上下文
结合 Midway 的使用
import { Context, controller, get, inject, provide } from "midway";
@provide()
@controller("/api/user")
export class UserController {
@get("/destroy")
@Transaction()
async destroy(): Promise<void> {
const { id } = this.ctx.query;
const user = await this.ctx.service.user.deleteUserById({ id });
// 如果发生失败,上述的数据库操作自动回滚
const user2 = await this.ctx.service.user.deleteUserById2({ id });
this.ctx.body = { success: true, data: [user,user2] };
}
}
(4)更多特性迭代中
数据缓存,为了提升数据的查询的效率,我们正在迭代开发 Node-MyBatis 的缓存机制,减少对数据库数据查询的压力,提升整体数据查询的效率。
MyBatis 提供了一级缓存,和二级缓存,我们在架构上也进行了参考,架构图如下图-4。
一级缓存是 SqlSession 级别的缓存,在同一个 SqlSession 中两次执行相同的 SQL 语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个 SqlSession 结束后该 SqlSession 中的一级缓存也就不存在了。不同的 SqlSession 之间的缓存数据区域是互相不影响。
二级缓存是 Mapper 级别的缓存,多个 SqlSession 去操作同一个 Mapper 的 SQL 语句得到数据会存在二级缓存区域,多个 SqlSession 可以共用二级缓存,二级缓存是跨SqlSession的。

图-4 缓存架构图
自定义方法和标签,在 SQL 模版中,我们通过 #、$、<%%> 来实现 SQL 的动态构建,不过在项目实战中我们发现很多重复的一些SQL 拼接场景,针对这些场景我们正在开发在 SQL 模板中支持自定义的方法和标签,直接内置在模板中使用提升开发效率,并且提供插件机制,方便开发者开发自己的自定义方法和标签。下面我们看看通过自定义方法和标签对 SQL 构建的一些小例子。
数据插入
目前的数据插入方式,保持了 native SQL 的方式,但是,当数据库的字段特别多的时候,一个个去列出插入的字段是比较累的一件事情。特别是当我们规范强调 SQL 插入时必须指定插入的列名,避免数据插入不一致。
INSERT INTO
test_user
(name, job, email, age, edu)
VALUES
(#data.name, #data.job, #data.email, #data.age, #data.edu)
Node-MyBatis 内置方法 - quickInsert()
-- user = {
-- name: 'test',
-- job: 'Programmer',
-- email: 'test@test1.com',
-- age: 25,
-- edu: 'Undergraduate'
-- }
-- sql builder
INSERT INTO test_user <% quickInsert(data.user) %>
-- 通过 SQL compiler 自动输出
INSERT INTO
test_user (name, job, email, age, edu)
VALUES('test', 'Programmer', 'test@test1.com', 25, 'Undergraduate')
-- userList = [
-- {name: 'test', job: 'Programmer', email: 'test@test1.com', age: 25, edu: 'Undergraduate'},
-- {name: 'test2', job: 'Programmer', email: 'test@test2.com', age: 30, edu: 'Undergraduate'}
-- ]
-- 批量插入
INSERT INTO test_user <% quickInsert(data.userList)%>
-- 通过 SQL compiler 自动输出
INSERT INTO
test_user (name, job, email, age, edu)
VALUES
('test', 'Programmer', 'test@test1.com', 25, 'Undergraduate'),
('test2', 'Programmer', 'test@test2.com', 30, 'Undergraduate')
Node-MyBatis 内置标签 -
-- user = {
-- name: 'test',
-- job: 'Programmer',
-- email: 'test@test1.com',
-- age: 25,
-- edu: 'Undergraduate'
-- }
-- sql builder
<Insert table="test_user" values={data.user}></Insert>
-- 通过 SQL compiler 自动输出
INSERT INTO
test_user (name, job, email, age, edu)
VALUES('test', 'Programmer', 'test@test1.com', 25, 'Undergraduate')
-- userList = [
-- {name: 'test', job: 'Programmer', email: 'test@test1.com', age: 25, edu: 'Undergraduate'},
-- {name: 'test2', job: 'Programmer', email: 'test@test2.com', age: 30, edu: 'Undergraduate'}
--]
-- sql builder
<Insert table="test_user" values={data.userList}></Insert>
--通过 SQL compiler 自动输出
INSERT INTO
test_users (name, job, email, age, edu)
VALUES
('test', 'Programmer', 'test@test1.com', 25, 'Undergraduate'),
('test2', 'Programmer', 'test@test2.com', 30, 'Undergraduate')
目前 Node-MyBatis 基于 Midway 的插件规范内置在项目中,目前正在抽离独立模块形成独立的解决方案,然后针对 Midway 进行适配对接,提升方案的独立性。
3、Node-MyBatis 实战
(1)API
/**
* 查询符合所有的条件的数据库记录
* @param sql: string sql字符串
* @param params 传递给sql字符串动态变量的对象
*/
query(sql, params = {})
/**
* 查询符合条件的数据库一条记录
* @param sql: string sql字符串
* @param params 传递给sql字符串动态变量的对象
*/
queryOne(sql, params = {})
/**
* 插入或更新数据库记录
* @param sql: string sql字符串
* @param params 传递给sql字符串动态变量的对象
*/
exec(sql, params = {})
(2)项目结构
因为我们选择使用 Midway 作为我们的 BFF 的 Node 框架, 所以我们的目录结构遵循标准的 Midway 的结构。
.
├── controller # 入口 controller 层
│ ├── base.ts # controller 公共基类
│ ├── table.ts
│ └── user.ts
├── extend # 对 midway 的扩展
│ ├── codes
│ │ └── index.ts
│ ├── context.ts
│ ├── enums # 枚举值
│ │ ├── index.ts
│ │ └── user.ts
│ ├── env # 扩展环境
│ │ ├── index.ts
│ │ ├── local.ts
│ │ ├── prev.ts
│ │ ├── prod.ts
│ │ └── test.ts
│ ├── helper.ts # 工具方法
│ └── nodebatis # nodebatis 核心代码
│ ├── decorator # 声明式事务封装
│ ├── plugin # 自定义工具方法
│ ├── config.ts # 核心配置项
│ └── index.ts
├── middleware # 中间件层
│ └── error_handler.ts # 扩展错误处理
├── public
└── service # 业务 service 层
├── Mapping # node-mybatis的 mapping层
│ ├── TableMapping.ts
│ └── UserMapping.ts
├── table.ts # table service 和 db相关调用 TableMapping
└── user.ts # user service 和 db相关调用 UserMapping
(3)业务场景
根据用户 id 查询用户信息,当 Node 服务收到用户信息的查询请求,根据 URL 的规则路由将请求分派到 UserController 的 getUserById 方法进行处理,getUserById 方法通过对 UserService 进行调用完成相关数据的获取,UserService 通过 Node-MyBatis 完成对数据库用户信息的查询。
Controller层
//controller/UserController.ts
import { controller, get, provide } from 'midway';
import BaseController from './base'
@provide()
@controller('/api/user')
export class UserController extends BaseController {
/**
* 根据用户id查询所有用户信息
*/
@get('/getUserById')
async getUserById() {
const { userId } = this.ctx.query;
let userInfo:IUser = await this.ctx.service.user.getUserById({userId})
this.success(userInfo)
}
}
Service层
// service/UserService.ts
import { provide } from 'midway';
import { Service } from 'egg';
import UserMapping from './mapping/UserMapping';
@provide()
export default class UserService extends Service {
getUserById(params: {userId: number}): Promise<{id: number, name: string, age: number}> {
return this.ctx.helper.queryOne(UserMapping.findById, params);
}
}
DAO层
// service/mapping/UserMapping.ts
export default {
findById: `
SELECT
id,
name,
age
FROM users t1
WHERE
t1.id=#data.userId
`
}
4、工程化体系
(1)类型体系
在 Node 服务的开发中,我们需要更多的工程化的能力,如代码的提示和自动补全、代码的检查、重构等,所以我们选择 TypeScript 作为我们的开发语言,同时 Midway 也提供了很多的对于 Typescript 的支撑。
我们希望我们的 Node-MyBatis 也能插上类型的翅膀,可以根据查询的数据能够自动检查纠错补齐。于是就产生了我们 tts (table to typescript system) 解决方案, 可以根据数据库的元数据自动生成 TypeScript 的类型定义文件。
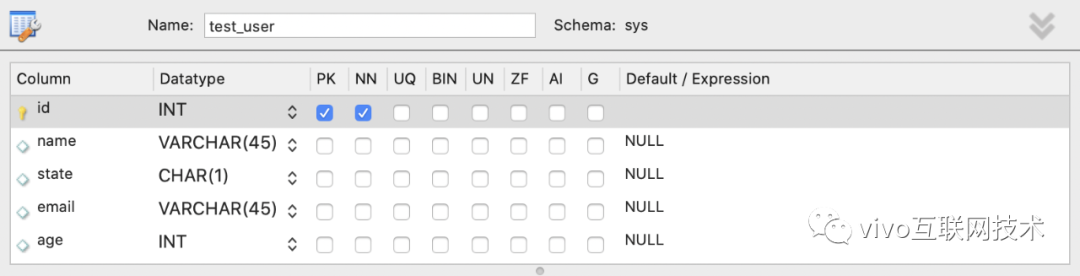
图-5 数据库表结构
通过 tts -t test_user 自动生成表单的类型定义文件,如下:
export interface ITestUser {
/**
* 用户id
*/
id: number
/**
* 用户名
*/
name: string
/**
* 用户状态
*/
state: string
/**
* 用户邮箱
*/
email: string
/**
* 用户年龄
*/
age: string
}
这样在开发中就可以使用到这个类型文件,给我们的日常开发带来一些便利。再结合上TypeScript的高级类型容器如Pick、Partial、Record、Omit等可以根据查询的字段进行复杂类型的适配。
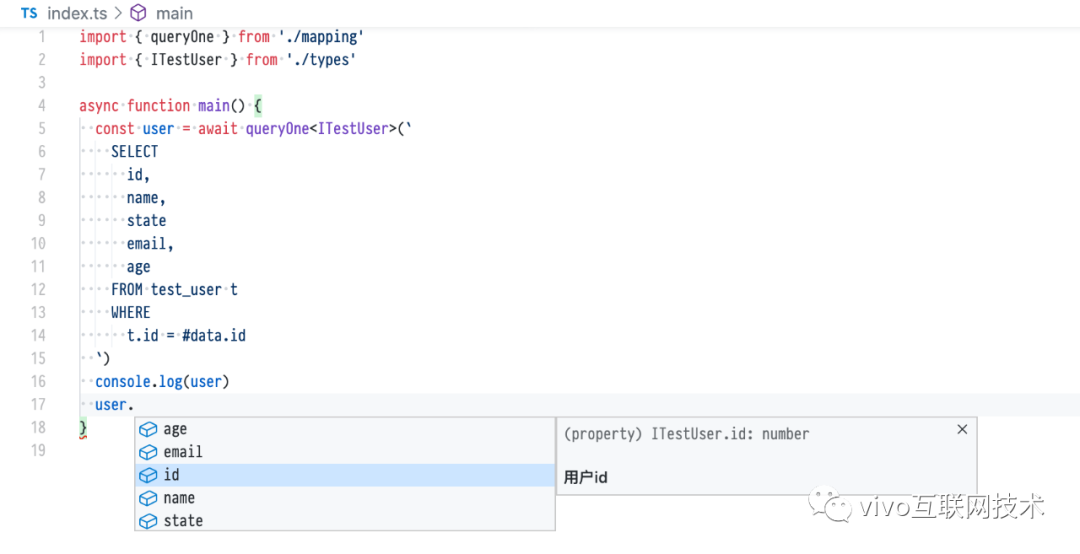
图-6 tts 类型文件的使用
(2)LSP
VSCode 基本成为前端开发编辑器的第一选择,另外通过 VSCode 架构中的 LSP(语言服务协议)可以完成很多 IDE 的功能,为我们的开发提供更智能的帮助。
比如我们在使用 Node-MyBatis 中需要编写大量的 SQL 字符串,对于 VSCode 来说,这就是一个普通的 JavaScript 的字符串,没有任何特殊之处。
但是我们期待能够走得更远,比如能自动识别 SQL 的关键字,语法高亮,并且实现 SQL 的自动美化。通过开发 VSCode 插件,对 SQL 的语法特征智能分析,可以做到如下效果,实现 SQL 代码高亮和格式化,后续还会支持 SQL 的自动补齐。
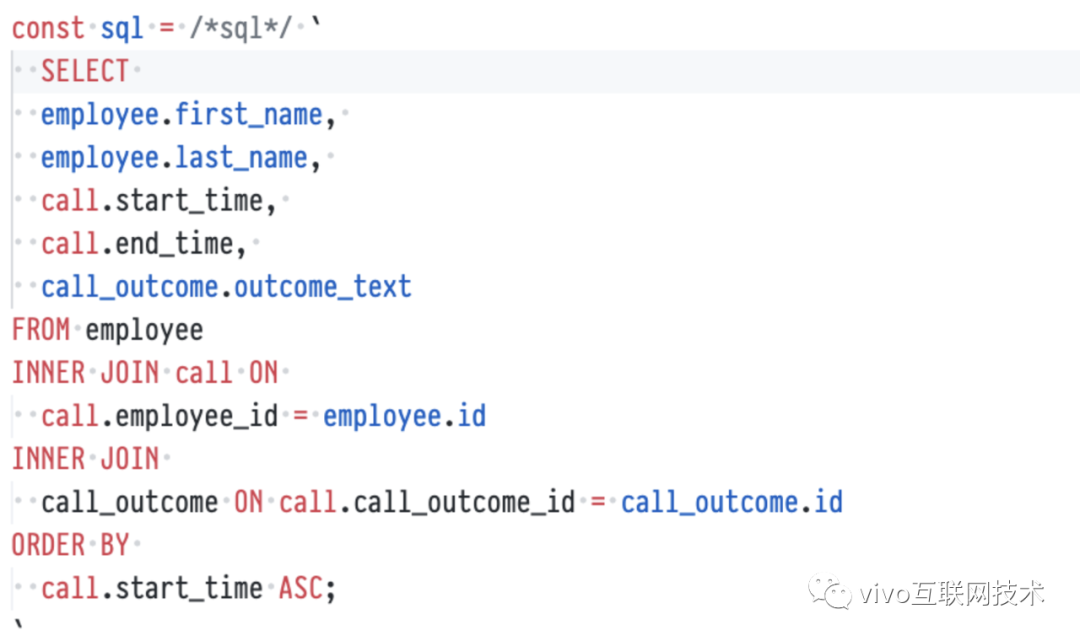
图-7 SQL 字符串模板的高亮和格式化
另外,因为支持了自定义模板和自定义方法之后,编写 SQL 的效率得到了提升,对于 SQL 生成就变得不再直观,需要在运行期才知道 SQL 的字符串内容。怎么解决这个痛点,其实也可以通过 LSP 解决这个问题,做到这效率和可维护性的平衡,通过开发 VSCode 的插件, 智能分析 SQL 模板结构实时悬浮提示生成的 SQL 。
四、总结
文章到了这里,已经进入结尾,感谢您的关注和陪伴。本文我们一起回顾了悟空活动中台 Node 服务数据层持久化解决方案设计上的一些思考和探索,我们希望保留 SQL 的简单通用强大,又能保证极致的开发体验,希望通过 Node-MyBatis 的设计兑现了我们的思考。
作者: vivo 悟空中台研发团队
往期阅读: