
一、主从同步/复制** **
**
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。 但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
主从数据库的配置:
主数据库不用配置,从数据库的配置文件(redis.conf)中可以加载主数据库的信息,也可以在启动时,使用 redis-server --port 6380 --slaveof 127.0.0.1 6379 命令指明主数据库的 IP 和端口。从数据库一般是只读,可以改为可写,但写入的数据很容易被主同步没,所以还是只读就可以。也可以在运行时使用 slaveof ip port 命令,停止原来的主,切换成刚刚设置的主 slaveof no one会把自己变成主。
主从复制原理:
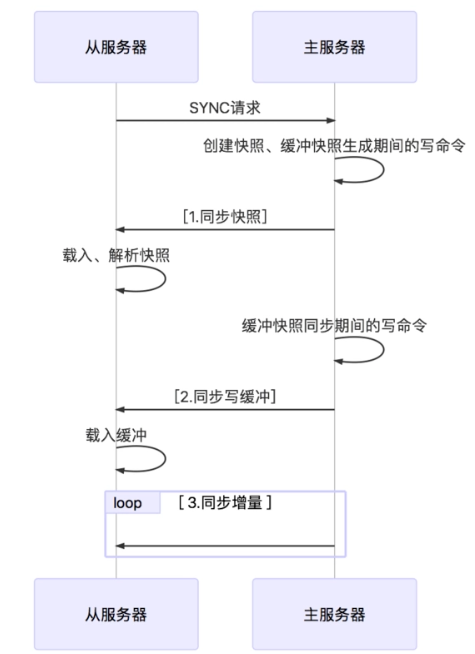
- 从数据库连接主数据库,发送SYNC命令;
- 主数据库接收到SYNC命令后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主数据库BGSAVE执行完后,向所有从数据库发送快照文件,并在发送期间继续记录被执行的写命令;
- 从数据库收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主数据库快照发送完毕后开始向从数据库发送缓冲区中的写命令;
- 从数据库完成对快照的载入,开始接收命令请求,并执行来自主数据库缓冲区的写命令;(从数据库初始化完成)
- 主数据库每执行一个写命令就会向从数据库发送相同的写命令,从数据库接收并执行收到的写命令(从数据库初始化完成后的操作)
- 出现断开重连后,2.8之后的版本会将断线期间的命令传给重数据库,增量复制。
- 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。Redis 的策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
优点:
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离;
- 为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成;
- Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力;
- Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求;
- Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据;
缺点:
- Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复;
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性;
- 如果多个Slave断线了,需要重启的时候,尽量不要在同一时间段进行重启。因为只要Slave启动,就会发送sync请求和主机全量同步,当多个 Slave 重启的时候,可能会导致 Master IO剧增从而宕机。
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂;
二、哨兵模式
第一种主从同步/复制的模式,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
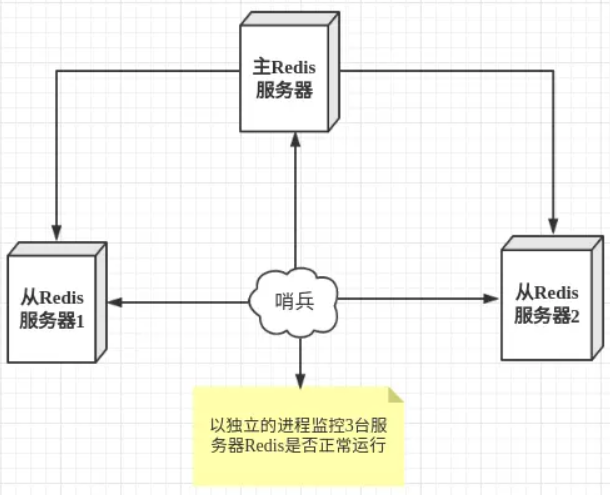
哨兵模式的作用:
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器;
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机;
然而一个哨兵进程对Redis服务器进行监控,也可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
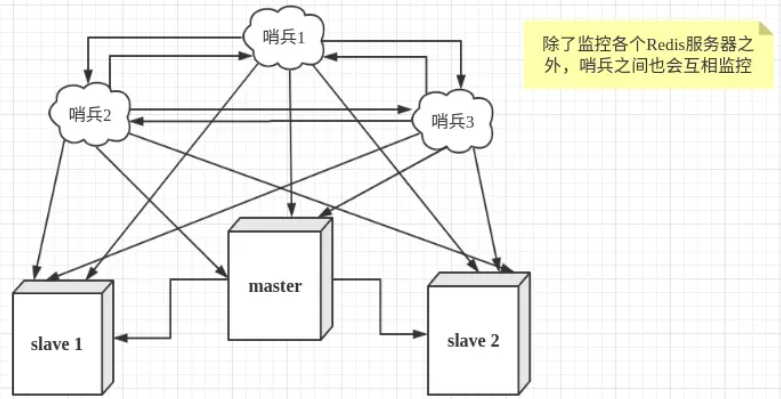
故障切换的过程:
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行 failover 操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
哨兵模式的配置:
配置一主二从和三个哨兵的 Redis 服务器来演示这个过程
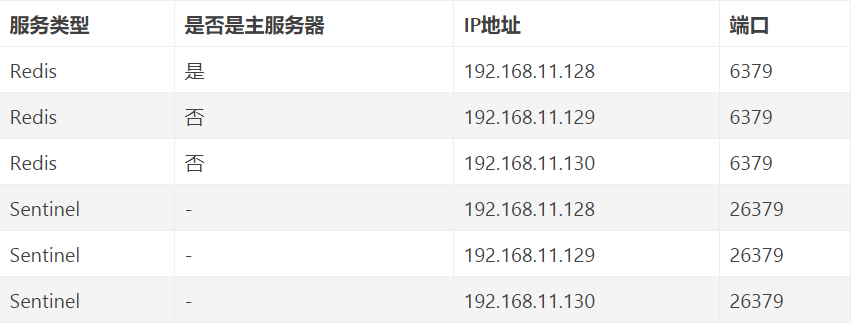
主从服务器配置

\# 使得Redis服务器可以跨网络访问
bind 0.0.0.0
# 设置密码
requirepass "123456"
# 以下有关slaveof的配置只是配置从服务器,主服务器不需要配置
# 指定主服务器
slaveof 192.168.11.128 6379
# 主服务器密码
masterauth 123456
哨兵配置

\# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel monitor mymaster 192.168.11.128 6379 2
# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
配置3个哨兵,每个哨兵的配置都是一样的。在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
启动
注意启动的顺序。首先是主机(192.168.11.128)的 Redis 服务进程,然后启动从机的 Redis 服务进程,最后启动3个哨兵的服务进程。
哨兵模式的工作方式:
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
- 在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
- 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
优点:
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
- 主从可以自动切换,系统更健壮,可用性更高。
缺点:
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
三、Cluster 集群
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的内容。
集群的配置
根据官方推荐,集群部署至少要 3 台以上的master节点,最好使用 3 主 3 从六个节点的模式。在测试环境中,只能在一台机器上面开启6个服务实例来模拟。
1、修改配置文件
将 redis.conf 的配置文件复制6份(文件名最好加上端口后缀),然后开始修改配置文件中的参数

#开启redis的集群模式
cluster-enabled yes
#配置集群模式下的配置文件
cluster-config-file nodes-6379.conf
#集群内节点之间支持最长响应时间
cluster-node-timeout 15000
2、修改完毕之后启动 6 个 Redis 服务
3、快速部署集群
6个 Redis 服务启动成功之后,借助 redis-tri.rb 工具可以快速的部署集群,如果本机没有该命令行需要自行安装,只需要执行/redis-trib.rb create --replicas 1 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 就可以成功创建集群。
创建集群可能会出现的错误
#这是由于创建集群中的某一个服务中曾经插入过数据,并且已经产生了持久化文件,此时需要flushall命令清空所有数据
\[ERR\] Node 127.0.0.1:6380 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
#这是由于之前创建集群遗留的配置文件导致的问题,使用命令cluster reset即可
redis-4.1.0/lib/redis/client.rb:124:in \`call': ERR Slot 935 is already busy集群的部署会在后续的文章中进行详细的说明和测试,这里就不详细说明了
集群的特点
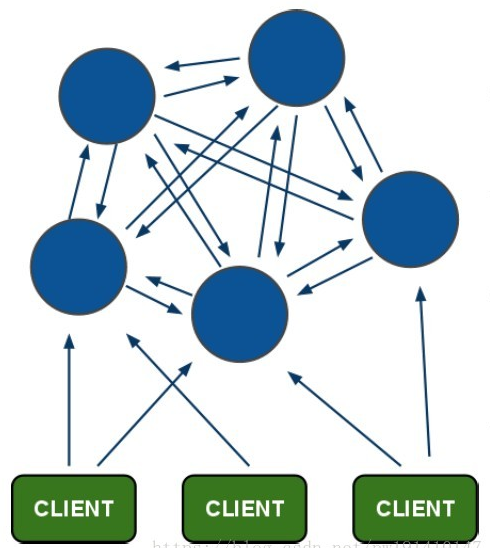
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与 Redis 节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
集群的工作方式
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的 Key到达的时候,Redis 会根据 crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点A1都宕机了,那么该集群就无法再提供服务了。
转载: https://www.cnblogs.com/L-Test/p/11626124.html
本文转自 https://www.cnblogs.com/lovezbs/p/14055594.html,如有侵权,请联系删除。












