

前言
在前面的 SOFA 源码分析 —— 服务发布过程 文章中,我们分析了 SOFA 的服务发布过程,一个完整的 RPC 除了发布服务,当然还需要引用服务。 So,今天就一起来看看 SOFA 是如何引用服务的。实际上,基础逻辑和我们之前用 Netty 写的 RPC 小 demo 类似。有兴趣可以看看这个 demo—— 自己用 Netty 实现一个简单的 RPC。
示例代码
ConsumerConfig<HelloService> consumerConfig = new ConsumerConfig<HelloService>()
.setInterfaceId(HelloService.class.getName()) // 指定接口
.setProtocol("bolt") // 指定协议
.setDirectUrl("bolt://127.0.0.1:9696"); // 指定直连地址
HelloService helloService = consumerConfig.refer();
while (true) {
System.out.println(helloService.sayHello("world"));
try {
Thread.sleep(2000);
} catch (Exception e) {
}
}
同样的,代码例子来自 SOFA-RPC 源码,位于com.alipay.sofa.rpc.quickstart.QuickStartClient。
很简单,创建一个消费者配置类,然后使用这个配置引用一个代理对象,调用 代理对象的方法,实际上就是调用了远程服务。
我们就通过上面这个简单的例子,看看 SOFA 是如何进行服务引用的。注意:我们今天的目的是看看主流程,有些细节可能暂时就一带而过了,比如负载均衡,错误重试啥的,我们以后再详细分析,实际上,Client 相对有 Server,还是要复杂一些的,因为它要考虑更多的情况。
好,开始吧!
源码分析
首先看这个 ConsumerConfig 类,和前面的 ProviderConfig 类似,甚至于实现的接口和继承的抽象类都是一样的。
上面的例子设置了一些属性,比如接口名称,协议,直连地址。
关键点来了, refer 方法。
这个方法就是返回了一个代理对象,代理对象中包含了之后远程调用中需要的所有信息,比如过滤器,负载均衡等等。
然后,调用动态代理的方法,进行远程调用,如果是 JDK 的动态代理的话,就是一个实现了 InvocationHandler 接口的类。这个类的 invoke 方法会拦截并进行远程调用,自然就是使用 Netty 的客户端对服务端发起调用并得到数据啦。
先看看 refer 方法。
从 refer 方法开始源码分析
该方法类套路和 provider 的套路类似,都是使用了一个 BootStrap 引导。即单一职责。
public T refer() {
if (consumerBootstrap == null) {
consumerBootstrap = Bootstraps.from(this);
}
return consumerBootstrap.refer();
}
ConsumerBootstrap 是个抽象类,SOFA 基于他进行扩展,目前有 2 个扩展点,bolt 和 rest。默认是 bolt。而 bolt 的实现则是 BoltConsumerBootstrap,目前来看 bolt 和 rest 并没有什么区别,都是使用的一个父类 DefaultConsumerBootstrap。
所以,来看看 DefaultConsumerBootstrap 的 refer 方法。代码我就不贴了,因为很长。基本上引用服务的逻辑全部在这里了,类似 Spring 的 refresh 方法。逻辑如下:
- 根据 ConsumerConfig 创建 key 和 appName。检查参数合法性。对调用进行计数。
- 创建一个 Cluster 对象,这个对象非常重要,该对象管理着核心部分的信息。详细的后面会说,而构造该对象的参数则是 BootStrap。
- 设置一些监听器。
- 初始化 Cluster。其中包括设置路由,地址初始化,连接管理,过滤器链构造,重连线程等。
- 创建一个 proxyInvoker 执行对象,也就是初始调用对象,作用是注入到动态代理的拦截类中,以便动态代理从此处开始调用。构造参数也是 BootStrap。
- 最后,创建一个动态代理对象,目前动态代理有 2 个扩展点,分别是 JDK,javassist。默认是 JDK,但似乎 javassist 的性能会更好一点。如果是 JDK 的话,拦截器则是 JDKInvocationHandler 类,构造方法需要代理类和刚刚创建的 proxyInvoker 对象。proxyInvoker 的作用就是从这里开始链式调用。
其中,关键的对象是 Cluster。该对象需要重点关注。
Cluster 是个抽象类,也是个扩展点,实现了 Invoker, ProviderInfoListener, Initializable, Destroyable 等接口。而他目前的具体扩展点有 2 个: FailFastCluster(快速失败), FailoverCluster(故障转移和重试)。默认是后者。当然,还有一个抽象父类,AbstractCluster。
该类有个重要的方法, init 方法,初始化 Cluster,Cluster 可以理解成客户端,封装了集群模式、长连接管理、服务路由、负载均衡等抽象类。
init 方法代码如下,不多。
public synchronized void init() {
if (initialized) { // 已初始化
return;
}
// 构造Router链
routerChain = RouterChain.buildConsumerChain(consumerBootstrap);
// 负载均衡策略 考虑是否可动态替换?
loadBalancer = LoadBalancerFactory.getLoadBalancer(consumerBootstrap);
// 地址管理器
addressHolder = AddressHolderFactory.getAddressHolder(consumerBootstrap);
// 连接管理器
connectionHolder = ConnectionHolderFactory.getConnectionHolder(consumerBootstrap);
// 构造Filter链,最底层是调用过滤器
this.filterChain = FilterChain.buildConsumerChain(this.consumerConfig,
new ConsumerInvoker(consumerBootstrap));
// 启动重连线程
connectionHolder.init();
// 得到服务端列表
List<ProviderGroup> all = consumerBootstrap.subscribe();
if (CommonUtils.isNotEmpty(all)) {
// 初始化服务端连接(建立长连接)
updateAllProviders(all);
}
// 启动成功
initialized = true;
// 如果check=true表示强依赖
if (consumerConfig.isCheck() && !isAvailable()) {
}
}
可以看到,干的活很多。每一步都值得花很多时间去看,但看完所有不是我们今天的任务,我们今天关注一下调用,上面的代码中,有一段构建 FilterChain 的代码是值得我们今天注意的。
创建了一个 ConsumerInvoker 对象,作为最后一个过滤器调用,关于过滤器的设计,我们之前已经研究过了,不再赘述,详情 SOFA 源码分析 —— 过滤器设计。
我们主要看看 ConsumerInvoker 类,该类是离 Netty 最近的过滤器。实际上,他也是拥有了一个 BootStrap,但,注意,拥有了 BootStrap ,相当于挟天子以令诸侯,啥都有了,在他的 invoke 方法中,会直接获取 Boostrap 的 Cluster 向 Netty 发送数据。
代码如下:
return consumerBootstrap.getCluster().sendMsg(providerInfo, sofaRequest);
厉害吧。
那么,Cluster 是如何进行 sendMsg 的呢?如果是 bolt 类型的 Cluster 的话,就直接使用 bolt 的 RpcClient 进行调用了,而 RpcClient 则是使用的 Netty 的 Channel 的 writeAndFlush 方法发送数据。如果是同步调用的话,就阻塞等待数据。
总的流程就是这样,具体细节留到以后慢慢分析。
下面看看拿到动态代理对象后,如何进行调用。
动态代理如何调用?
当我们调用的时候,肯定会被 JDKInvocationHandler 拦截。拦截方法则是 invoke 方法。方法很简单,主要就是使用我们之前注入的 proxyInvoker 的 invoke 方法。我们之前说了,proxyInvoker 的作用其实就是一个链表的头。而他主要了代理了真正的主角 Cluster,所以,你可以想到,他的 invoke 方法肯定是调用了 Cluster 的 invoke 方法。
Cluster 是真正的主角(注意:默认的 Cluster 是 FailoverCluster),那么他的调用肯定是一连串的过滤器。目前默认有两个过滤器:ConsumerExceptionFilter, RpcReferenceContextFilter。最后一个过滤器则是我们之前说的,离 Netty 最近的过滤器 —— ConsumerInvoker。
ConsumerInvoker 会调用 Cluster 的 sendMsg 方法,Cluster 内部包含一个 ClientTransport ,这个 ClientTransport 就是个胶水类,融合 bolt 的 RpcClient。所以,你可以想到,当 ConsumerInvoker 调用 sendMsg 方法的时候,最后会调用 RpcClient 的 invokeXXX 方法,可能是异步,也可能是同步的,bolt 支持多种调用方式。
而 RpcClient 最后则是调用 Netty 的 Channel 的 writeAndFlush 方法向服务提供者发送数据。
取一段 RpcClietn 中同步(默认)执行的代码看看:
protected RemotingCommand invokeSync(final Connection conn, final RemotingCommand request,
final int timeoutMillis) throws RemotingException,
InterruptedException {
final InvokeFuture future = createInvokeFuture(request, request.getInvokeContext());
conn.addInvokeFuture(future);
conn.getChannel().writeAndFlush(request).addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture f) throws Exception {
if (!f.isSuccess()) {
conn.removeInvokeFuture(request.getId());
future.putResponse(commandFactory.createSendFailedResponse(
conn.getRemoteAddress(), f.cause()));
}
}
});
// 阻塞等待
RemotingCommand response = future.waitResponse(timeoutMillis);
return response;
}
通过 Netty 的 Channel 的 writeAndFlush 方法发送数据,并添加一个监听器,如果失败了,就向 future 中注入一个失败的对象。
在异步执行后,主线程开始等待,内部使用 countDownLatch 进行阻塞。而 countDownLatch 的初始化参数为 1。什么时候唤醒 countDownLatch 呢?
在 putResponse 方法中,会唤醒 countDownLatch。
而 putResponse 方法则会被很多地方使用。比如在 bolt 的 RpcResponseProcessor 的 doProcess 方法中就会调用。而这个方法则是在 RpcHandler 的 channelRead 方法中间接调用。
所以,如果 writeAndFlush 失败了,会 putResponse ,没有失败的话,正常执行,则会在 channelRead 方法后简介调用 putResponse.
总结一下调用的逻辑吧,楼主画了一张图,大家可以看看,画的不好,还请见谅。
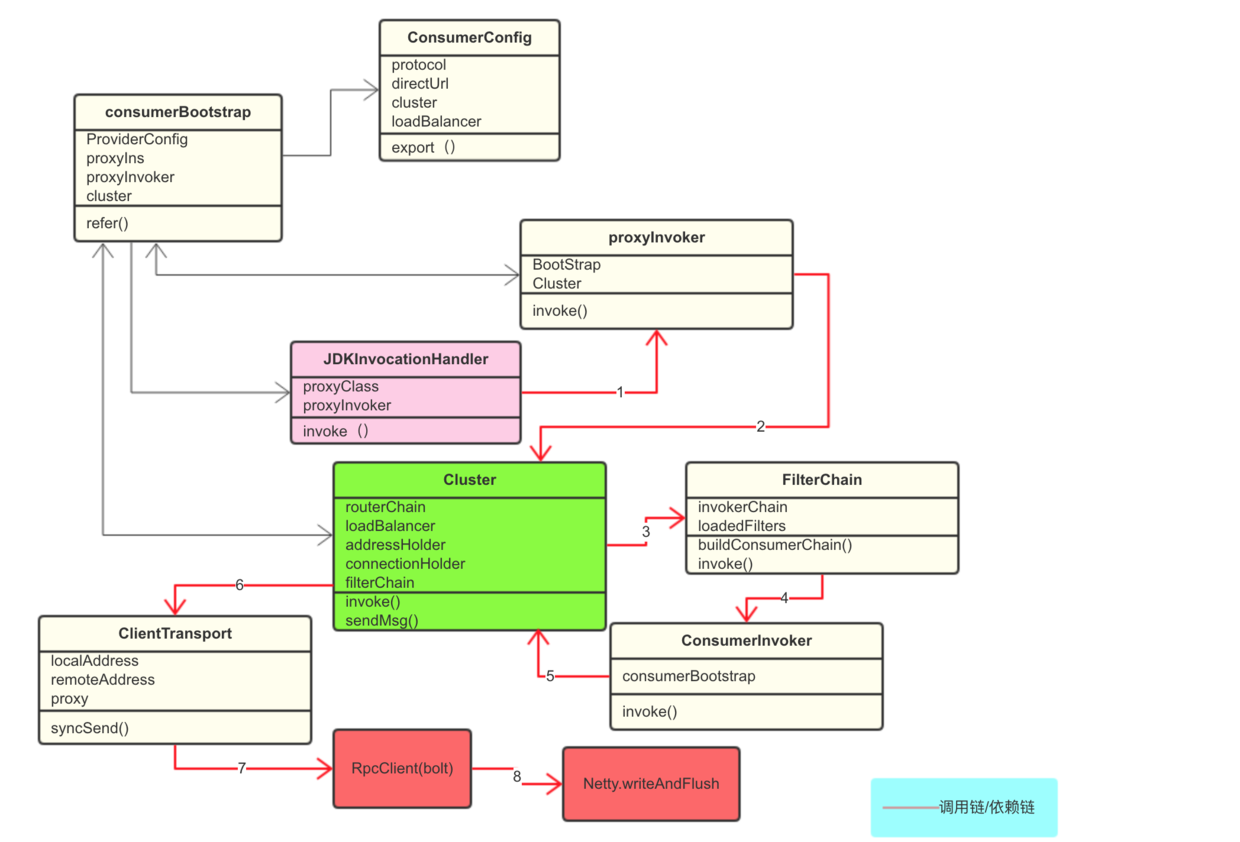
红色线条是调用链,从 JDKInvocationHandler 开始,直到 Netty。绿色部分是 Cluster,和 Client 的核心。大红色部分是 bolt 和 Netty。
好了,关于 SOFA 的服务引用主流程我们今天就差不多介绍完了,当然,有很多精华还没有研究到。我们以后会慢慢的去研究。
总结
看完了 SOFA 的服务发布和服务引用,相比较 SpringCloud 而言,真心觉得很轻量。上面的一幅图基本就能展示大部分调用过程,这在 Spring 和 Tomcat 这种框架中,是不可想象的。而 bolt 的隔离也让 RPC 框架有了更多的选择,通过不同的扩展点实现,你可以使用不同的网络通信框架。这时候,有必要上一张 SOFA 官方的图了:
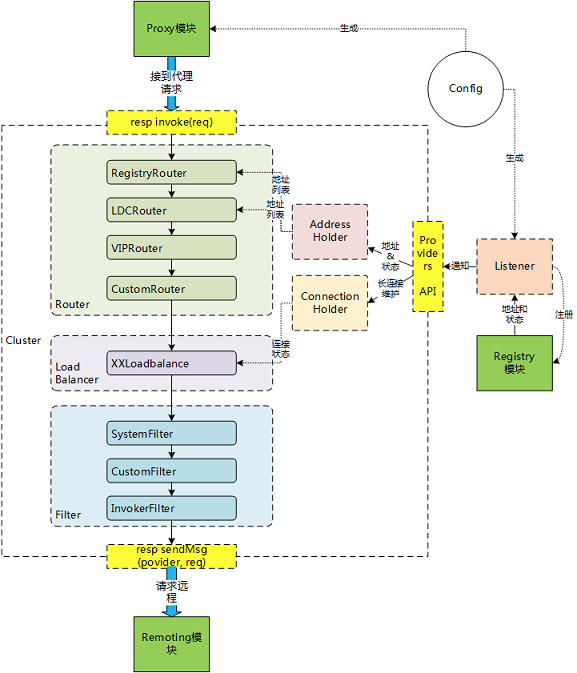
从上图可以看出,我们今天比较熟悉的地方,比如 Cluster,包含了过滤器,负载均衡,路由,然后调用 remoting 的远程模块,也就是 bolt。 通过 sendMsg 方法。
而 Cluster 的外部模块,我们今天就没有仔细看了,这个肯定是要留到今后看的。比如地址管理,连接管理等等。
好啦,今天就到这里。如有不对之处,还请指正。











