
前言
JDK1.5以前只有synchronized同步锁,并且效率非常低,因此大神Doug Lea自己写了一套并发框架,这套框架的核心就在于AbstractQueuedSynchronizer类(即AQS),性能非常高,所以被引入JDK包中,即JUC。那么AQS是怎么实现的呢?本篇就是对AQS及其相关组件进行分析,了解其原理,并领略大神的优美而又精简的代码。
AbstractQueuedSynchronizer
AQS是JUC下最核心的类,没有之一,所以我们先来分析一下这个类的数据结构。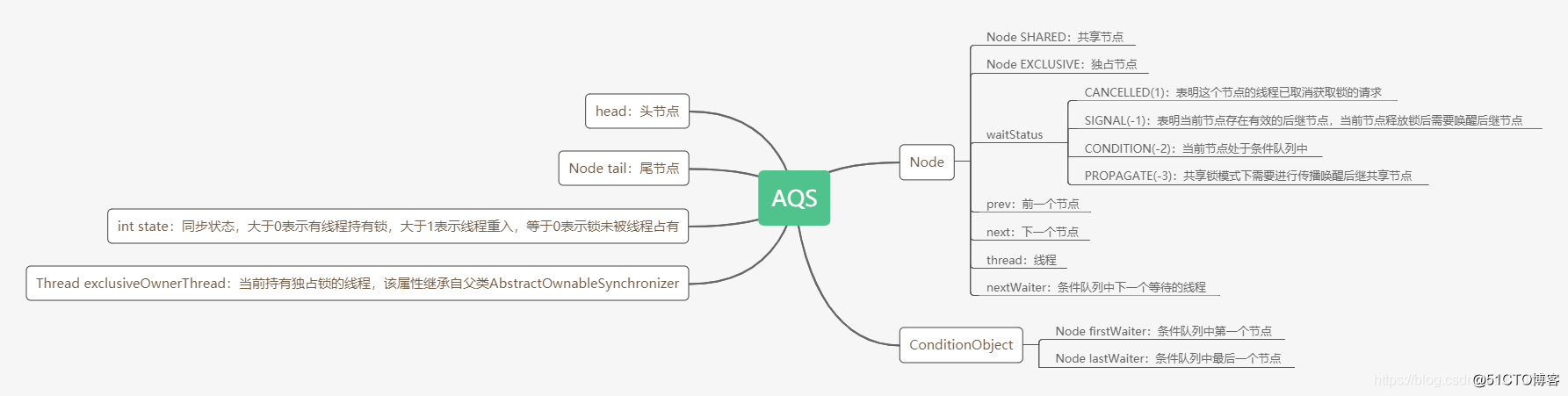
AQS内部是使用了双向链表将等待线程链接起来,当发生并发竞争的时候,就会初始化该队列并让线程进入睡眠等待唤醒,同时每个节点会根据是否为共享锁标记状态为共享模式或独占模式。这个数据结构需要好好理解并牢牢记住,下面分析的组件都将基于此实现。
Lock
Lock是一个接口,提供了加/解锁的通用API,JUC主要提供了两种锁,ReentrantLock和ReentrantReadWriteLock,前者是重入锁,实现Lock接口,后者是读写锁,本身并没有实现Lock接口,而是其内部类ReadLock或WriteLock实现了Lock接口。先来看看Lock都提供了哪些接口:
// 普通加锁,不可打断;未获取到锁进入AQS阻塞void lock();// 可打断锁void lockInterruptibly() throws InterruptedException;// 尝试加锁,未获取到锁不阻塞,返回标识boolean tryLock();// 带超时时间的尝试加锁boolean tryLock(long time, TimeUnit unit) throws InterruptedException;// 解锁void unlock();// 创建一个条件队列Condition newCondition();
看到这里读者们可以先思考下,自己如何来实现上面这些接口。
ReentrantLock
加锁
synchronized和ReentrantLock都是可重入的,后者使用更加灵活,也提供了更多的高级特性,但其本质的实现原理是差不多的(据说synchronized是借鉴了ReentrantLock的实现原理)。ReentrantLock提供了两个构造方法:
public ReentrantLock() { sync = new NonfairSync(); } public ReentrantLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); }
有参构造是根据参数创建公平锁或非公平锁,而无参构造默认则是非公平锁,因为非公平锁性能非常高,并且大部分业务并不需要使用公平锁。至于为什么非公平锁性能很高,咱们接着往下看。
非公平锁/公平锁
lock
非公平锁和公平锁在实现上基本一致,只有个别的地方不同,因此下面会采用对比分析方法进行分析。
从lock方法开始:
public void lock() { sync.lock(); }
实际上是委托给了内部类Sync,该类实现了AQS(其它组件实现方法也基本上都是这个套路);由于有公平和非公平两种模式,因此该类又实现了两个子类:FairSync和NonfairSync:
// 非公平锁 final void lock() { if (compareAndSetState(0, 1)) setExclusiveOwnerThread(Thread.currentThread()); else acquire(1); } // 公平锁 final void lock() { acquire(1); }
这里就是公平锁和非公平锁的第一个不同,非公平锁首先会调用CAS将state从0改为1,如果能改成功则表示获取到锁,直接将exclusiveOwnerThread设置为当前线程,不用再进行后续操作;否则则同公平锁一样调用acquire方法获取锁,这个是在AQS中实现的模板方法:
public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); }
tryAcquire
这里两种锁唯一不同的实现就是tryAcquire方法,先来看非公平锁的实现:
protected final boolean tryAcquire(int acquires) { return nonfairTryAcquire(acquires); } final boolean nonfairTryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) // overflow throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; }
state=0表示还没有被线程持有锁,直接通过CAS修改,能修改成功的就获取到锁,修改失败的线程先判断exclusiveOwnerThread是不是当前线程,是则state+1,表示重入次数+1并返回true,加锁成功,否则则返回false表示尝试加锁失败并调用acquireQueued入队。
protected final boolean tryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; } public final boolean hasQueuedPredecessors() { Node t = tail; // Read fields in reverse initialization order Node h = head; Node s; // 首尾不相等且头结点线程不是当前线程则表示需要进入队列 return h != t && ((s = h.next) == null || s.thread != Thread.currentThread()); }
上面就是公平锁的尝试获取锁的代码,可以看到基本和非公平锁的代码是一样的,区别在于首次加锁需要判断是否已经有队列存在,没有才去加锁,有则直接返回false。
addWaiter
接着来看addWaiter方法,当尝试加锁失败时,首先就会调用该方法创建一个Node节点并添加到队列中去。
private Node addWaiter(Node mode) { Node node = new Node(Thread.currentThread(), mode); Node pred = tail; // 尾节点不为null表示已经存在队列,直接将当前线程作为尾节点 if (pred != null) { node.prev = pred; if (compareAndSetTail(pred, node)) { pred.next = node; return node; } } // 尾结点不存在则表示还没有初始化队列,需要初始化队列 enq(node); return node; } private Node enq(final Node node) { // 自旋 for (;;) { Node t = tail; if (t == null) { // 只会有一个线程设置头节点成功 if (compareAndSetHead(new Node())) tail = head; } else { // 其它设置头节点失败的都会自旋设置尾节点 node.prev = t; if (compareAndSetTail(t, node)) { t.next = node; return t; } } } }
这里首先传入了一个独占模式的空节点,并根据该节点和当前线程创建了一个Node,然后判断是否已经存在队列,若存在则直接入队,否则调用enq方法初始化队列,提高效率。
此处还有一个非常细节的地方,为什么设置尾节点时都要先将之前的尾节点设置为node.pre的值呢,而不是在CAS之后再设置?比如像下面这样:
if (compareAndSetTail(pred, node)) { node.prev = pred; pred.next = node; return node;}
因为如果这样做的话,在CAS设置完tail后会存在一瞬间的tail.pre=null的情况,而Doug Lea正是考虑到这种情况,不论何时获取tail.pre都不会为null。
acquireQueued
接着看acquireQueued方法:
final boolean acquireQueued(final Node node, int arg) { // 为true表示存在需要取消加锁的节点,仅从这段代码可以看出, // 除非发生异常,否则不会存在需要取消加锁的节点。 boolean failed = true; try { // 打断标记,因为调用的是lock方法,所以是不可打断的 // (但实际上是打断了的,只不过这里采用了一种**静默**处理方式,稍后分析) boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { int ws = pred.waitStatus; if (ws == Node.SIGNAL) return true; if (ws > 0) { do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; } private final boolean parkAndCheckInterrupt() { LockSupport.park(this); return Thread.interrupted(); }
这里就是队列中线程加锁/睡眠的核心逻辑,首先判断刚刚调用addWaiter方法添加到队列的节点是否是头节点,如果是则再次尝试加锁,这个刚刚分析过了,非公平锁在这里就会再次抢一次锁,抢锁成功则设置为head节点并返回打断标记;否则则和公平锁一样调用shouldParkAfterFailedAcquire判断是否应该调用park方法进入睡眠。
park细节
为什么在park前需要这么一个判断呢?因为当前节点的线程进入park后只能被前一个节点唤醒,那前一个节点怎么知道有没有后继节点需要唤醒呢?因此当前节点在park前需要给前一个节点设置一个标识,即将waitStatus设置为Node.SIGNAL(-1),然后自旋一次再走一遍刚刚的流程,若还是没有获取到锁,则调用parkAndCheckInterrupt进入睡眠状态。
打断
读者可能会比较好奇Thread.interrupted这个方法是做什么用的。
public static boolean interrupted() { return currentThread().isInterrupted(true); }
这个是用来判断当前线程是否被打断过,并清除打断标记(若是被打断过则会返回true,并将打断标记设置为false),所以调用lock方法时,通过interrupt也是会打断睡眠的线程的,只是Doug Lea做了一个假象,让用户无感知;但有些场景又需要知道该线程是否被打断过,所以acquireQueued最终会返回interrupted打断标记,如果是被打断过,则返回的true,并在acquire方法中调用selfInterrupt再次打断当前线程(将打断标记设置为true)。
这里我们对比看看lockInterruptibly的实现:
public void lockInterruptibly() throws InterruptedException { sync.acquireInterruptibly(1); } public final void acquireInterruptibly(int arg) throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); if (!tryAcquire(arg)) doAcquireInterruptibly(arg); } private void doAcquireInterruptibly(int arg) throws InterruptedException { final Node node = addWaiter(Node.EXCLUSIVE); boolean failed = true; try { for (;;) { final Node p = node.predecessor(); if (p == head && tryAcquire(arg)) { setHead(node); p.next = null; // help GC failed = false; return; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) throw new InterruptedException(); } } finally { if (failed) cancelAcquire(node); } }
可以看到区别就在于使用lockInterruptibly加锁被打断后,是直接抛出InterruptedException异常,我们可以捕获这个异常进行相应的处理。
取消
最后来看看cancelAcquire是如何取消加锁的,该情况比较特殊,简单了解下即可:
private void cancelAcquire(Node node) { if (node == null) return; // 首先将线程置空 node.thread = null; // waitStatus > 0表示节点处于取消状态,则直接将当前节点的pre指向在此之前的最后一个有效节点 Node pred = node.prev; while (pred.waitStatus > 0) node.prev = pred = pred.prev; // 保存前一个节点的下一个节点,如果在此之前存在取消节点,这里就是之前取消被取消节点的头节点 Node predNext = pred.next; node.waitStatus = Node.CANCELLED; // 当前节点是tail节点,则替换尾节点,替换成功则将新的尾结点的下一个节点设置为null; // 否则需要判断是将当前节点的下一个节点赋值给最后一个有效节点,还是唤醒下一个节点。 if (node == tail && compareAndSetTail(node, pred)) { compareAndSetNext(pred, predNext, null); } else { int ws; if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) { Node next = node.next; if (next != null && next.waitStatus <= 0) compareAndSetNext(pred, predNext, next); } else { unparkSuccessor(node); } node.next = node; // help GC } }
解锁
public void unlock() { sync.release(1); } public final boolean release(int arg) { if (tryRelease(arg)) { Node h = head; if (h != null && h.waitStatus != 0) unparkSuccessor(h); return true; } return false; } protected final boolean tryRelease(int releases) { int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) throw new IllegalMonitorStateException(); boolean free = false; if (c == 0) { free = true; setExclusiveOwnerThread(null); } setState(c); return free; } private void unparkSuccessor(Node node) { int ws = node.waitStatus; if (ws < 0) compareAndSetWaitStatus(node, ws, 0); Node s = node.next; // 并发情况下,可能已经被其它线程唤醒或已经取消,则从后向前找到最后一个有效节点并唤醒 if (s == null || s.waitStatus > 0) { s = null; for (Node t = tail; t != null && t != node; t = t.prev) if (t.waitStatus <= 0) s = t; } if (s != null) LockSupport.unpark(s.thread); }
解锁就比较简单了,先调用tryRelease对state执行减一操作,如果state==0,则表示完全释放锁;若果存在后继节点,则调用unparkSuccessor唤醒后继节点,唤醒后的节点的waitStatus会重新被设置为0.
只是这里有一个小细节,为什么是从后向前找呢?因为我们在开始说过,设置尾节点保证了node.pre不会为null,但pre.next仍有可能是null,所以这里只能从后向前找到最后一个有效节点。
小结
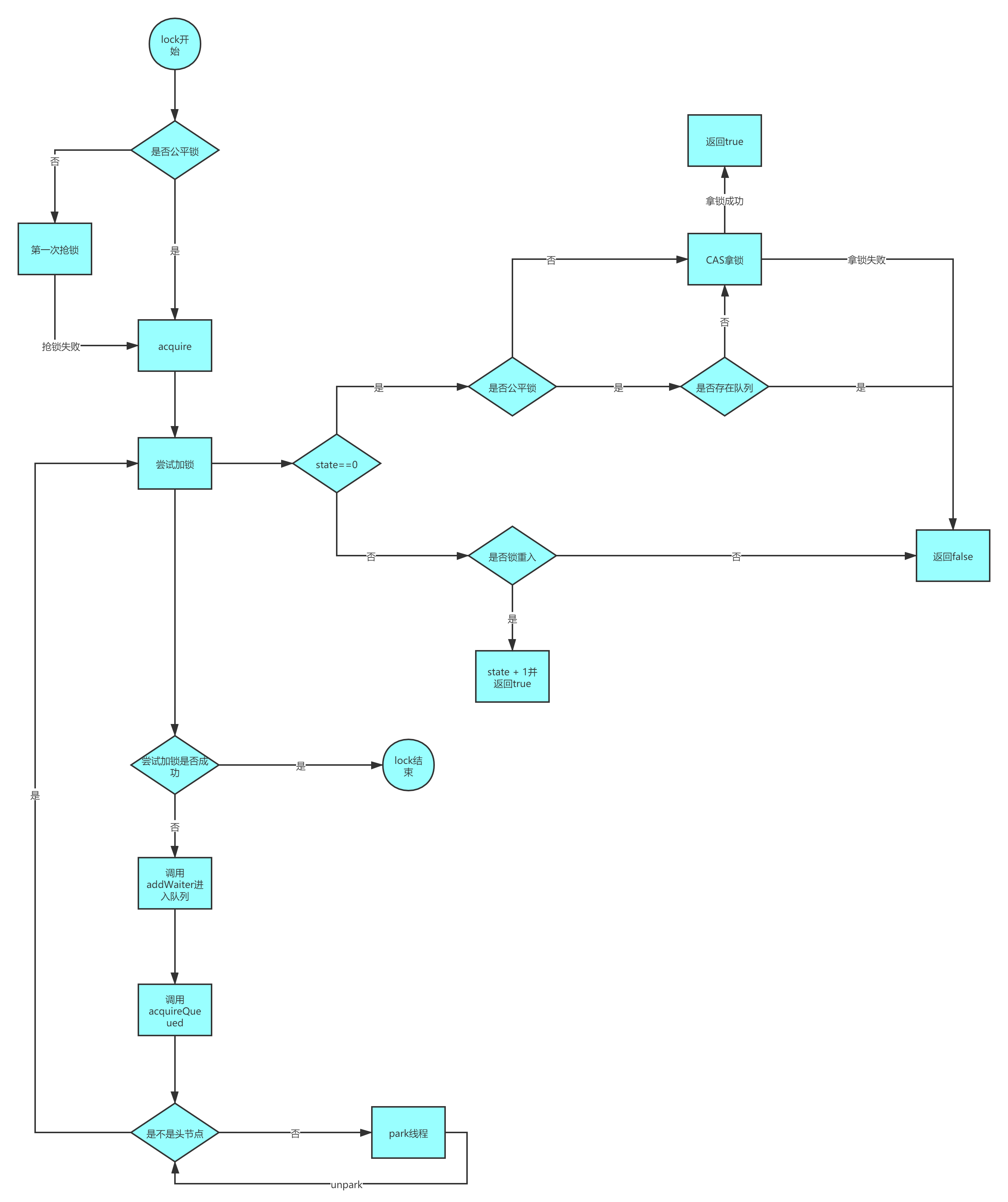
上面是ReentrantLock的加锁流程,可以看到整个流程不算复杂,只是判断和跳转比较多,主要是Doug Lea将代码和性能都优化到了极致,代码非常精简,但细节却非常多。另外通过上面的分析,我们也可以发现,公平锁和非公平锁的区别就在于非公平锁不管是否有线程在排队,先抢三次锁,而公平锁则会判断是否存在队列,有线程在排队则直接进入队列排队;另外线程在park被唤醒后非公平锁还会抢锁,公平锁仍然需要排队,所以非公平锁的性能比公平锁高很多,大部分情况下我们使用非公平锁即可。
ReentrantReadWriteLock
ReentrantLock是一把独占锁,只支持重入,不支持共享,所以JUC包下还提供了读写锁,这把锁支持读读并发,但读写、写写都是互斥的。
读写锁也是基于AQS实现的,也包含了一个继承自AQS的内部类Sync,同样也有公平和非公平两种模式,下面主要讨论非公平模式下的读写锁实现。
读写锁实现相对比较复杂,在ReentrantLock中就是使用的int型的state属性来表示锁被某个线程占有和重入次数,而ReentrantReadWriteLock分为了读和写两种锁,要怎么用一个字段表示两种锁的状态呢?Doug Lea大师将state字段分为了高二字节和低二字节,即高16位用来表示读锁状态,低16位则用来表示写锁,如下图:

因为读写锁状态都只用了两个字节,所以可重入的次数最多是65535,当然正常情况下重入是不可能达到这么多的。
那它是怎么实现的呢?还是先从构造方法开始:
public ReentrantReadWriteLock() { this(false); } public ReentrantReadWriteLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); readerLock = new ReadLock(this); writerLock = new WriteLock(this); }
同样默认就是非公平锁,同时还创建了readerLock和writerLock两个对象,我们只需要像下面这样就能获取到读写锁:
private static ReentrantReadWriteLock lock = new ReentrantReadWriteLock(); private static Lock r = lock.readLock(); private static Lock w = lock.writeLock();
写锁
由于写锁的加锁过程相对更简单,下面先从写锁加锁开始分析,入口在ReentrantReadWriteLock#WriteLock.lock()方法,点进去看,发现还是使用的AQS中的acquire方法:
public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); }
所以不同的地方也只有tryAcquire方法,我们重点分析这个方法就行:
static final int SHARED_SHIFT = 16; // 65535 static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1; // 低16位是1111....1111 static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1; // 得到c低16位的值 static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; } protected final boolean tryAcquire(int acquires) { Thread current = Thread.currentThread(); int c = getState(); // 获取写锁加锁和重入的次数 int w = exclusiveCount(c); if (c != 0) { // 已经有线程持有锁 // 这里有两种情况:1. c!=0 && w==0表示有线程获取了读锁,不论是否是当前线程,直接返回false, // 也就是说读-写锁是不支持升级重入的(但支持写-读降级),原因后文会详细分析; // 2. c!=0 && w!=0 && current != getExclusiveOwnerThread()表示有其它线程持有了写锁,写写互斥 if (w == 0 || current != getExclusiveOwnerThread()) return false; // 超出65535,抛异常 if (w + exclusiveCount(acquires) > MAX_COUNT) throw new Error("Maximum lock count exceeded"); // 否则写锁的次数直接加1 setState(c + acquires); return true; } // c==0才会走到这,但这时存在两种情况,有队列和无队列,所以公平锁和非公平锁处理不同, // 前者需要判断是否存在队列,有则尝试加锁失败,无则加锁成功,而非公平锁直接使用CAS加锁即可 if (writerShouldBlock() || !compareAndSetState(c, c + acquires)) return false; setExclusiveOwnerThread(current); return true; }
写锁尝试加锁的过程就分析完了,其余的部分上文已经讲过,这里不再赘述。
读锁
public void lock() { sync.acquireShared(1); } public final void acquireShared(int arg) { if (tryAcquireShared(arg) < 0) doAcquireShared(arg); }
读锁在加锁开始就和其它锁不同,调用的是acquireShared方法,意为获取共享锁。
static final int SHARED_UNIT = (1 << SHARED_SHIFT); // 右移16位得到读锁状态的值 static int sharedCount(int c) { return c >>> SHARED_SHIFT; } protected final int tryAcquireShared(int unused) { Thread current = Thread.currentThread(); int c = getState(); // 为什么读写互斥?因为读锁一上来就判断了是否有其它线程持有了写锁(当前线程持有写锁再获取读锁是可以的) if (exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current) return -1; int r = sharedCount(c); // 公平锁判断是否存在队列,非公平锁判断第一个节点是不是EXCLUSIVE模式,是的话会返回true // 返回false则需要判断读锁加锁次数是否超过65535,没有则使用CAS给读锁+1 if (!readerShouldBlock() && r < MAX_COUNT && compareAndSetState(c, c + SHARED_UNIT)) { if (r == 0) { // 第一个读锁线程就是当前线程 firstReader = current; firstReaderHoldCount = 1; } else if (firstReader == current) { // 记录读锁的重入 firstReaderHoldCount++; } else { // 获取最后一次加读锁的重入次数记录器HoldCounter HoldCounter rh = cachedHoldCounter; if (rh == null || rh.tid != getThreadId(current)) // 当前线程第一次重入需要初始化,以及当前线程和缓存的最后一次记录器的线程id不同,需要从ThreadLocalHoldCounter拿到对应的记录器 cachedHoldCounter = rh = readHolds.get(); else if (rh.count == 0) // 缓存到ThreadLocal readHolds.set(rh); rh.count++; } return 1; } return fullTryAcquireShared(current); }
这段代码有点复杂,首先需要保证读写互斥,然后进行初次加锁,若加锁失败就会调用fullTryAcquireShared方法进行兜底处理。在初次加锁中与写锁不同的是,写锁的state可以直接用来记录写锁的重入次数,因为写写互斥,但读锁是共享的,state用来记录读锁的加锁次数了,重入次数该怎么记录呢?重入是指同一线程,那么是不是可以使用ThreadLocl来保存呢?没错,Doug Lea就是这么处理的,新增了一个HoldCounter类,这个类只有线程id和重入次数两个字段,当线程重入的时候就会初始化这个类并保存在ThreadLocalHoldCounter类中,这个类就是继承ThreadLocl的,用来初始化HoldCounter对象并保存。
这里还有个小细节,为什么要使用cachedHoldCounter缓存最后一次加读锁的HoldCounter?因为大部分情况下,重入和释放锁的线程很有可能就是最后一次加锁的线程,所以这样做能够提高加解锁的效率,Doug Lea真是把性能优化到了极致。
上面只是初次加锁,有可能会加锁失败,就会进入到fullTryAcquireShared方法:
final int fullTryAcquireShared(Thread current) { HoldCounter rh = null; for (;;) { int c = getState(); if (exclusiveCount(c) != 0) { if (getExclusiveOwnerThread() != current) return -1; } else if (readerShouldBlock()) { if (firstReader == current) { // assert firstReaderHoldCount > 0; } else { if (rh == null) { rh = cachedHoldCounter; if (rh == null || rh.tid != getThreadId(current)) { rh = readHolds.get(); if (rh.count == 0) readHolds.remove(); } } if (rh.count == 0) return -1; } } if (sharedCount(c) == MAX_COUNT) throw new Error("Maximum lock count exceeded"); if (compareAndSetState(c, c + SHARED_UNIT)) { if (sharedCount(c) == 0) { firstReader = current; firstReaderHoldCount = 1; } else if (firstReader == current) { firstReaderHoldCount++; } else { if (rh == null) rh = cachedHoldCounter; if (rh == null || rh.tid != getThreadId(current)) rh = readHolds.get(); else if (rh.count == 0) readHolds.set(rh); rh.count++; cachedHoldCounter = rh; // cache for release } return 1; } } }
这个方法中代码和tryAcquireShared基本上一致,只是采用了自旋的方式,处理初次加锁中的漏网之鱼,读者们可自行阅读分析。
上面两个方法若返回大于0则表示加锁成功,小于0则会调用doAcquireShared方法,这个就和之前分析的acquireQueued差不多了:
private void doAcquireShared(int arg) { // 先添加一个SHARED类型的节点到队列 final Node node = addWaiter(Node.SHARED); boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor(); if (p == head) { // 再次尝试加读锁 int r = tryAcquireShared(arg); if (r >= 0) { // 设置head节点以及传播唤醒后面的读线程 setHeadAndPropagate(node, r); p.next = null; // help GC if (interrupted) selfInterrupt(); failed = false; return; } } // 只有前一个节点的waitStatus=-1时才会park,=0或者-3(先不考虑-2和1的情况)都会设置为-1后再次自旋尝试加锁,若还是加锁失败就会park if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node); } } private void setHeadAndPropagate(Node node, int propagate) { // 设置头节点 Node h = head; // Record old head for check below setHead(node); // propagate是tryAcquireShared的返回值,当前线程加锁成功还要去唤醒后继的共享节点 // (其余的判断比较复杂,笔者也还未想明白,知道的读者可以指点一下) if (propagate > 0 || h == null || h.waitStatus < 0 || (h = head) == null || h.waitStatus < 0) { Node s = node.next; // 判断后继节点是否是共享节点 if (s == null || s.isShared()) doReleaseShared(); } } private void doReleaseShared() { for (;;) { Node h = head; // 存在后继节点 if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { // 当前一个节点加锁成功后自然需要将-1改回0,并唤醒后继线程,同时自旋将0改为-2让唤醒传播下去 if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) continue; unparkSuccessor(h); } // 设置头节点的waitStatus=-2,使得唤醒可以传播下去 else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) continue; } if (h == head) break; } } private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { int ws = pred.waitStatus; if (ws == Node.SIGNAL) return true; if (ws > 0) { do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0); pred.next = node; } else { compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; }
这里的逻辑也非常的绕,当多个线程同时调用addWaiter添加到队列中后,并且假设这些节点的第一个节点的前一个节点就是head节点,那么第一个节点就能加锁成功(假设都是SHARED节点),其余的节点在第一个节点设置头节点之前都会进入shouldParkAfterFailedAcquire方法,这时候waitStatus都等于0,所以继续自旋不会park,若再次加锁还失败就会park(因为这时候waitStatus=-1),但都是读线程的情况下一般都不会出现,因为setHeadAndPropagate第一步就是修改head,所以其余SHARED节点最终都能加锁成功并一直将唤醒传播下去。
以上就是读写锁加锁过程,解锁比较简单,这里就不详细分析了。
小结
读写锁将state分为了高二字节和低二字节,分别存储读锁和写锁的状态,实现更为的复杂,在使用上还有几点需要注意:
读读共享,但是在读中间穿插了写的话,后面的读都会被阻塞,直到前面的写释放锁后,后面的读才会共享,相关原理看完前文不难理解。
读写锁只支持降级重入,不支持升级重入。因为如果支持升级重入的话,是会出现死锁的。如下面这段代码:
private static void rw() { r.lock(); try { log.info("获取到读锁"); w.lock(); try { log.info("获取到写锁"); } finally { w.unlock(); } } finally { r.unlock(); } }
多个线程访问都能获取到读锁,但读写互斥,彼此都要等待对方的读锁释放才能获取到写锁,这就造成了死锁。
ReentrantReadWriteLock在某些场景下性能上不算高,因此Doug Lea在JDK1.8的时候又提供了一把高性能的读写锁StampedLock,前者读写锁都是悲观锁,而后者提供了新的模式——乐观锁,但它不是基于AQS实现的,本文不进行分析。
Condition
Lock接口中还有一个方法newCondition,这个方法就是创建一个条件队列:
public Condition newCondition() { return sync.newCondition(); } final ConditionObject newCondition() { return new ConditionObject(); }
所谓条件队列就是创建一个新的ConditionObject对象,这个对象的数据结构在开篇就看过了,包含首、尾两个节点字段,每当调用Condition#await方法时就会在对应的Condition对象中排队等待:
public final void await() throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); // 加入条件队列 Node node = addConditionWaiter(); // 因为Condition.await必须配合Lock.lock使用,所以await时就是将已获得锁的线程全部释放掉 int savedState = fullyRelease(node); int interruptMode = 0; // 判断是在同步队列还是条件队列,后者则直接park while (!isOnSyncQueue(node)) { LockSupport.park(this); // 获取打断处理方式(抛出异常或重设标记) if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) break; } // 调用aqs的方法 if (acquireQueued(node, savedState) && interruptMode != THROW_IE) interruptMode = REINTERRUPT; if (node.nextWaiter != null) // clean up if cancelled // 清除掉已经进入同步队列的节点 unlinkCancelledWaiters(); if (interruptMode != 0) reportInterruptAfterWait(interruptMode); } private Node addConditionWaiter() { Node t = lastWaiter; // 清除状态为取消的节点 if (t != null && t.waitStatus != Node.CONDITION) { unlinkCancelledWaiters(); t = lastWaiter; } // 创建一个CONDITION状态的节点并添加到队列末尾 Node node = new Node(Thread.currentThread(), Node.CONDITION); if (t == null) firstWaiter = node; else t.nextWaiter = node; lastWaiter = node; return node; }
await方法实现比较简单,大部分代码都是上文分析过的,这里不再重复。接着来看signal方法:
public final void signal() { if (!isHeldExclusively()) throw new IllegalMonitorStateException(); // 从条件队列第一个节点开始唤醒 Node first = firstWaiter; if (first != null) doSignal(first); } private void doSignal(Node first) { do { if ( (firstWaiter = first.nextWaiter) == null) lastWaiter = null; first.nextWaiter = null; } while (!transferForSignal(first) && (first = firstWaiter) != null); } final boolean transferForSignal(Node node) { // 修改waitStatus状态,如果修改失败,则说明该节点已经从条件队列转移到了同步队列 if (!compareAndSetWaitStatus(node, Node.CONDITION, 0)) return false; // 上面修改成功,则将该节点添加到同步队列末尾,并返回之前的尾结点 Node p = enq(node); int ws = p.waitStatus; if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL)) // unpark当前线程,结合await方法看 LockSupport.unpark(node.thread); return true; }
signal的逻辑也比较简单,就是唤醒条件队列中的第一个节点,主要是要结合await的代码一起理解。
其它组件
上文分析的锁都是用来实现并发安全控制的,而对于多线程协作JUC又基于AQS提供了CountDownLatch、CyclicBarrier、Semaphore等组件,下面一一分析。
CountDownLatch
CountDownLatch在创建的时候就需要指定一个计数:
CountDownLatch countDownLatch = new CountDownLatch(5);
然后在需要等待的地方调用countDownLatch.await()方法,然后在其它线程完成任务后调用countDownLatch.countDown()方法,每调用一次该计数就会减一,直到计数为0时,await的地方就会自动唤醒,继续后面的工作,所以CountDownLatch适用于一个线程等待多个线程的场景,那它是怎么实现的呢?读者们可以结合上文自己先思考下。
public CountDownLatch(int count) { if (count < 0) throw new IllegalArgumentException("count < 0"); this.sync = new Sync(count); } Sync(int count) { setState(count); }
与前面讲的锁一样,也有一个内部类Sync继承自AQS,并且在构造时就将传入的计数设置到了state属性,看到这里不难猜到CountDownLatch的实现原理了。
public void await() throws InterruptedException { sync.acquireSharedInterruptibly(1); } public final void acquireSharedInterruptibly(int arg) throws InterruptedException { if (Thread.interrupted()) throw new InterruptedException(); if (tryAcquireShared(arg) < 0) doAcquireSharedInterruptibly(arg); } protected int tryAcquireShared(int acquires) { return (getState() == 0) ? 1 : -1; }
在await方法中使用的是可打断的方式获取的共享锁,同样除了tryAcquireShared方法,其余的都是复用的之前分析过的代码,而tryAcquireShared就是判断state是否等于0,不等于就阻塞。
public void countDown() { sync.releaseShared(1); } public final boolean releaseShared(int arg) { if (tryReleaseShared(arg)) { doReleaseShared(); return true; } return false; } protected boolean tryReleaseShared(int releases) { for (;;) { int c = getState(); if (c == 0) return false; int nextc = c-1; if (compareAndSetState(c, nextc)) return nextc == 0; } }
而调用countDown就更简单了,每次对state递减,直到为0时才会调用doReleaseShared释放阻塞的线程。
最后需要注意的是CountDownLatch的计数是不支持重置的,每次使用都要新建一个。
CyclicBarrier
CyclicBarrier和CountDownLatch使用差不多,不过它只有await方法。CyclicBarrier在创建时同样需要指定一个计数,当调用await的次数达到计数时,所有线程就会同时唤醒,相当于设置了一个“起跑线”,需要等所有运动员都到达这个“起跑线”后才能一起开跑。另外它还支持重置计数,提供了reset方法。
public CyclicBarrier(int parties) { this(parties, null); } public CyclicBarrier(int parties, Runnable barrierAction) { if (parties <= 0) throw new IllegalArgumentException(); this.parties = parties; this.count = parties; this.barrierCommand = barrierAction; }
CyclicBarrier提供了两个构造方法,我们可以传入一个Runnable类型的回调函数,当达到计数时,由最后一个调用await的线程触发执行。
public int await() throws InterruptedException, BrokenBarrierException { try { return dowait(false, 0L); } catch (TimeoutException toe) { throw new Error(toe); // cannot happen } } private int dowait(boolean timed, long nanos) throws InterruptedException, BrokenBarrierException, TimeoutException { final ReentrantLock lock = this.lock; lock.lock(); try { final Generation g = generation; if (g.broken) throw new BrokenBarrierException(); // 是否打断,打断会唤醒所有条件队列中的线程 if (Thread.interrupted()) { breakBarrier(); throw new InterruptedException(); } // 计数为0时,唤醒条件队列中的所有线程 int index = --count; if (index == 0) { // tripped boolean ranAction = false; try { final Runnable command = barrierCommand; if (command != null) command.run(); ranAction = true; nextGeneration(); return 0; } finally { if (!ranAction) breakBarrier(); } } for (;;) { try { // 不带超时时间直接进入条件队列等待 if (!timed) trip.await(); else if (nanos > 0L) nanos = trip.awaitNanos(nanos); } catch (InterruptedException ie) { if (g == generation && ! g.broken) { breakBarrier(); throw ie; } else { Thread.currentThread().interrupt(); } } if (g.broken) throw new BrokenBarrierException(); if (g != generation) return index; if (timed && nanos <= 0L) { breakBarrier(); throw new TimeoutException(); } } } finally { lock.unlock(); } } private void nextGeneration() { // signal completion of last generation trip.signalAll(); // set up next generation count = parties; generation = new Generation(); }
这里逻辑比较清晰,就是使用了ReentrantLock以及Condition来实现。在构造方法中我们可以看到保存了两个变量count和parties,每次调用await都会对count变量递减,count不为0时都会进入到trip条件队列中等待,否则就会通过signalAll方法唤醒所有的线程,并将parties重新赋值给count。
reset方法很简单,这里不详细分析了。
Semaphore
Semaphore是信号的意思,或者说许可,可以用来控制最大并发量。初始定义好有几个信号,然后在需要获取信号的地方调用acquire方法,执行完成后,需要调用release方法回收信号。
public Semaphore(int permits) { sync = new NonfairSync(permits); } public Semaphore(int permits, boolean fair) { sync = fair ? new FairSync(permits) : new NonfairSync(permits); }
它也有两个构造方法,可以指定公平或是非公平,而permits就是state的值。
public void acquire() throws InterruptedException { sync.acquireSharedInterruptibly(1); } // 非公平方式 final int nonfairTryAcquireShared(int acquires) { for (;;) { int available = getState(); int remaining = available - acquires; if (remaining < 0 || compareAndSetState(available, remaining)) return remaining; } } // 公平方式 protected int tryAcquireShared(int acquires) { for (;;) { if (hasQueuedPredecessors()) return -1; int available = getState(); int remaining = available - acquires; if (remaining < 0 || compareAndSetState(available, remaining)) return remaining; } }
acquire方法和CountDownLatch是一样的,只是tryAcquireShared区分了公平和非公平方式。获取到信号相当于加共享锁成功,否则则进入队列阻塞等待;而release方法和读锁解锁方式也是一样的,只是每次release都会将state+1。
最后
感谢大家看到这里,文章有不足,欢迎大家指出;如果你觉得写得不错,那就给我一个赞吧。










