
这段时间有点忙,很久没有更新公众号了。昨天有个粉丝催更,因此,我只能周末花点时间,和大家继续分享我的存储学习经验。
这个时代变化很快,纳斯达克100指数拼多多取代NetApp,这个新闻令我特别感慨。

PingWest品玩8月15日讯,纳斯达克交易所宣布,拼多多将在2020年8月24日开盘前取代NetApp成为纳斯达克100指数成分股。

拼多多,原来特别讨厌,现在我用得很多,淘宝已经基本不用了。因为拼多多假货少了,价格也比淘宝实惠,关键全部免邮,购物体验非常好。淘宝的邮费太乱了,8块钱的东西,邮费收你20块,这种定价模式,让你比价的时候永远不知道那个最便宜。而拼多多就没有这个烦恼,我基本都是快速下单,因为全部包邮,直接比价就可以了。
拼多多代表互联网新贵,而NetApp代表传统科技企业。这种喜新厌旧,代表一个新的时代开始了。
但存储技术也在快速发展,虽然没有互联网的巨变,但是也没有一潭死水。今天,我就分享一下Gartner今年的存储技术成熟度曲线,看看和去年有什么变化。

在"Hype Cycle for Storage and Data Protection Technologies, 2020"报告里,
,Gartner评估了IT领导者必须评估以解决企业快速发展的需求的24种最相关的存储和数据保护技术。
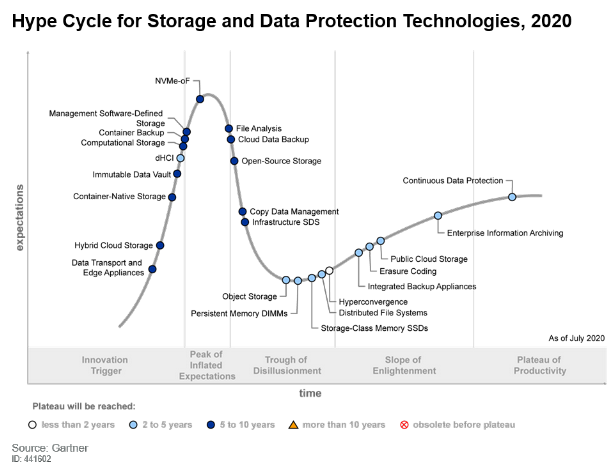
2020年炒作周期中审查的技术有一半以上将在未来五到十年内成熟,而如果真正的业务需求推动,则有60%的技术有可能带来高收益。为了向读者提供更清晰,更专注的研究以支持他们的分析和计划,今年Gartner删除了一些不再被大肆宣传的创新配置文件。
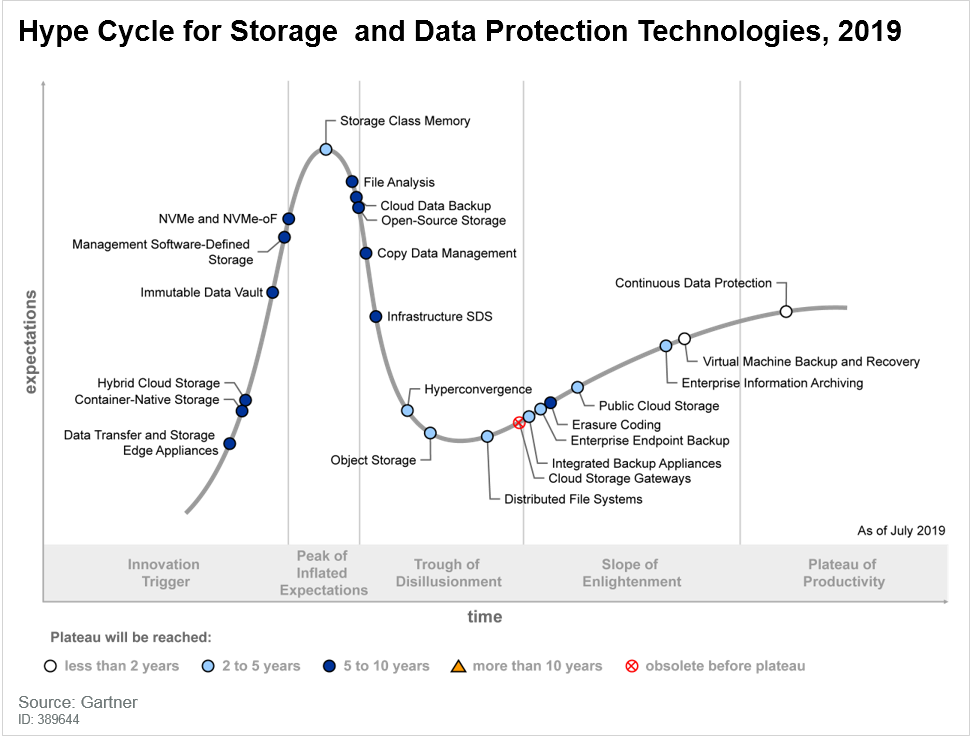
2020年的曲线和2019年的曲线,我们对比一下,发现:
云存储网关创新配置文件已删除,因为它在高原之前已过时。
以下配置文件已被删除,因为它们已经到期并且不再被炒作:
企业端点备份
虚拟机备份和恢复
2020年增加了三个新的创新配置文件:计算存储,容器备份和dHCI。尽管这些技术在价值主张上有很大不同,但它们反映了IT领导者优先考虑利用新的闪存技术,改进和现代化数据保护以及为存储和数据保护平台利用新的部署模式。
今年快速发展的技术包括存储级内存固态硬盘、NVMe-oF和超融合,这些技术的采用率都在不断提高,这主要是由于人们希望利用存储软件创新来实现基于行业标准硬件的高性能而又有弹性的存储基础设施。
如下描述的配置文件已更改:
NVMe和NVMe-oF更改为NVMe-oF。
存储级内存已分为两个配置文件:持久内存DIMM和存储级内存SSD。
关于优先级矩阵,我们来看看其变化:
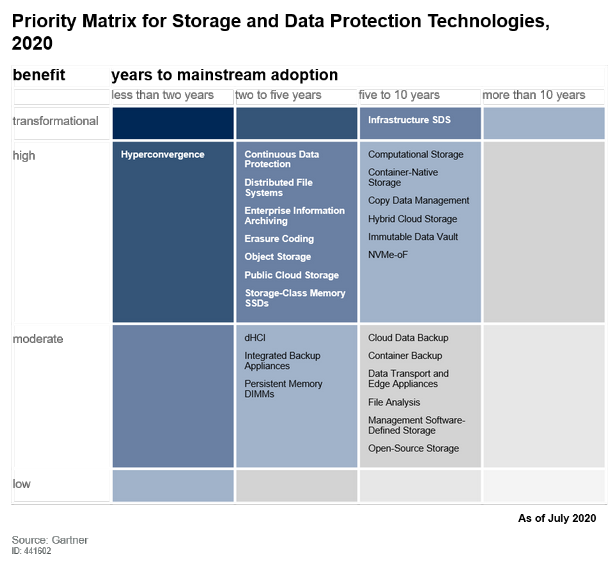
我们看到,和2019年一样,具备transformational(变革性)优先级的还是只有Infrasturcture SDS(简称iSDS)。但也还需要5-10年才能到达部署高峰。
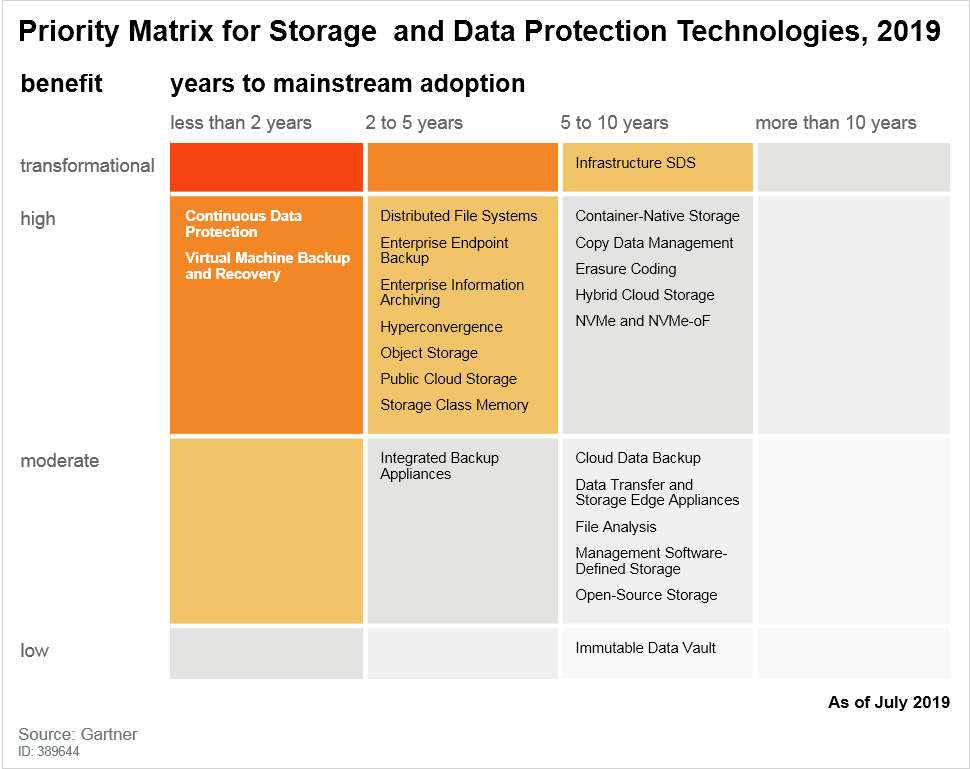
其他的一些变化,大家可以自己寻找。
今天,我们主要来仔细展开看看今年新入围的3个技术:计算存储,容器备份和dHCI。
计算存储(Computational Storage)
定义:计算存储(CS)结合了处理和存储介质,以允许应用程序在存储介质上运行,从而减轻了CPU主存储器的主机处理负担。目的是通过直接在存储设备内处理数据来减少数据移动。CS包含位于存储设备上的更复杂的处理功能。CS存储产品采用ASIC和SSD上的低功耗CPU内核的形式,具有更大的处理能力。
位置和采用速度的理由:计算存储为存储带来了计算能力,以减少存储和计算资源之间的数据移动中的性能低下和对延迟敏感的问题。基于CS的系统可能包括数据压缩,加密和独立磁盘冗余阵列(RAID)管理。随着数据量的增加,数据移动成为瓶颈。由于存储大小通常远远超过内存,因此必须从存储介质中读取数据。这阻碍了应用程序性能,破坏了大多数数据集的实时分析。存储与处理分开的原则仍然是大多数企业IT系统的核心原则。数据密集型应用程序,例如AI / ML,高性能计算,分析,通过消除瓶颈,高频交易以及身临其境的混合现实流媒体将最大程度地受益。边缘计算以及支持分布式处理的应用程序仍然是一个机会。此外,与包括工业标准固态介质的存储系统相比,在存储介质上进行处理可以提供显着的性能提升,更好的内存管理和节能。
用户忠告: CS市场仍处于开发阶段,少数供应商开始使用POC,限量和小批量生产系统。CS的早期用例正在迅速出现,包括机器学习处理,实时数据分析,高频交易,多媒体制作和高性能计算。跨多个CS节点运行的应用程序将表现最佳,并提供最大的收益。CS系统体系结构更加复杂,可能需要重新编译应用程序,可能需要其他API,或者使主机系统知道CS系统提供的服务。
建议I&O主管探索从特定用例中可能获得的收益,但应仔细权衡成本与性能收益之间的关系。在某些工作负载非常受输入/输出限制的情况下,尤其是在存储工作中受益最大的情况下,尤其如此。该部门由小型初创公司领导,因此建议I&O领导进行充分的尽职调查。另外,监视正在进行中的存储网络行业协会(SNIA)CS技术工作组(TWG)的发展情况,正在积极开展标准和互操作性工作,有20多家公司参与其中。
商业冲击:改组数TB的数据涉及成本和时间因素。CS可以为数据密集型应用程序提供实质性的性能优势,尤其是在边缘计算中。结合其低功耗,CS提高了每瓦性能比,从而降低了边缘应用的功耗成本。CS为增值存储服务(例如擦除编码和数据库分析功能)提供了一个可编程平台,从而大大降低了应用程序和服务器/计算成本。CS是对容器工作负载的补充。在固态媒体控制器中使用功能更强大的计算将提高存储效率并降低总体应用程序成本,从而使应用程序可以直接访问CS驱动器内部的NAND闪存芯片。通过利用通用闪存互连通道标准,可以在应用程序和固态媒体设备/控制器之间大幅增加带宽。但是,计算存储供应商面临的挑战是如何利用资源和功能将目标受众扩展到一些高级客户之外,以执行具有显着ROI优势的重要内部应用程序开发和测试。
福利等级:高
市场渗透率:不到目标受众的1%
成熟度:新兴
样本供应商: Eideticom; NETINT Technologies; NGD Systems; Nyriad; Samsung; ScaleFlux
西瓜哥认为,计算存储有点类似超融合,应该在边缘有较高的价值,但在数据中心,计算和存储多数情况还是分开更好。现在服务器和存储之间的带宽已经不是问题,加上SDS的普及,使得大规模的计算和存储独立扩展更加灵活。
容器备份(Container Backup)
定义:容器备份解决方案主要通过管理具有集成功能的数据的其他副本的复制过程来保护使用持久性存储的容器中的数据,以将数据恢复为一致状态。容器备份解决方案既可以作为传统备份解决方案的一部分提供,也可以作为存储解决方案的一部分提供,也可以作为专用解决方案提供。
位置和采用速度的合理性:容器备份解决方案是一种新兴技术,可以保护组织在容器化环境中免受数据丢失。由于容器具有无状态架构,因此与在虚拟机或物理机中运行的传统应用程序相比,它们需要不同的备份过程。领先的备份供应商开始通过与存储供应商提供的容器存储接口(CSI)插件提供的快照功能集成来保护持久性数据。容器备份在很大程度上是新生的,但是,企业环境中容器的采用曲线加速了对该领域数据保护解决方案的需求。
用户建议:在企业中采用容器的组织应根据应用程序的重要性评估容器备份的需求。此外,采用容器备份解决方案不仅是技术选择,而且还需要与组织结构保持一致。与传统基础架构不同,容器备份操作将由应用工程团队执行。因此,工程团队和备份团队之间可能需要一定程度的协调。保护容器还需要对备份基础架构进行额外的投资。与企业中的所有其他数据源一样,组织应采用一种容器备份策略。组织可能首先需要采用专门的容器备份解决方案,因为它们会成为重点,而企业供应商的采用会随着时间的推移逐渐成熟。
业务影响:容器备份解决方案可解决与容器环境相关的数据丢失风险。随着企业生产环境中容器的使用开始逐渐增加,保护数据的工作应与企业要求保持一致,就像所有企业数据一样。此外,在企业环境中备份容器将进一步推动容器的采用,因为它更好地与企业数据保护策略保持一致。但是,从数据保护治理的角度来看,容器备份将是另一个需要照顾的数据源,这会增加组织的负担。
福利等级:中等
市场渗透率:不到目标受众的1%
成熟度:新兴
供应商样本:Cohesity; Commvault; Dell EMC; IBM; Kasten; Portworx; Rubrik; Trilio
西瓜哥还是比较看好容器备份,因为存储有了CSI标准,在支持有状态容器这块发展很快,推动了容器在生产环境的应用,也大大增加了对容器备份的需求。容器备份未来的地位,就和现在虚拟机备份的地位类似,应该是每一个备份厂商必备的功能。
dHCI(disaggregated HCI)
定义:分离式HCI是使用单独的计算和存储节点的三层存储体系结构。存储可以是基于外部控制器的横向扩展存储,也可以是专用的SDS。dHCI提供了简化的HCI管理模型,同时允许独立扩展计算和存储。
位置和采用速度的合理性:基于外部控制器(ECB)和软件定义的存储(SDS)的供应商已经推出了分离式HCI(dHCI)产品,以针对希望易于使用超融合系统但又需要非对称扩展的客户计算和存储。与超融合相比,dHCI还可以支持裸机工作负载,并且可以提供更可预测的延迟和更高的存储吞吐量。
Datrium于2016年推出了首个dHCI解决方案(DVX)。紧随其后的是其他供应商,包括2017年的NetApp HCI和2019年的HPE Nimble Storage dHCI。随着越来越多的供应商进入市场,dHCI越来越受到青睐,并推动了集成基础架构系统(IIS)的增长。
用户建议: dHCI解决方案提供了ECB存储解决方案的许多优点,并结合了超融合解决方案的简单性和VM级别的存储供应功能。当I&O主管的工作负载满足以下条件时,应评估dHCI解决方案:
需要混合使用不同的服务器大小和配置。
占用大量存储容量。
有不平衡的计算和存储增长要求。
要求极高的交易速率或吞吐量。
需要可预测的延迟。
在考虑实施dHCI解决方案时,I&O主管应:
确定适合dHCI系统的特定工作量或计划。
服务器,存储和虚拟化团队共同实施,因为这三者都需要技能和项目一致性。
首先部署作为概念验证,以确保满足性能,可用性,自动化和易用性期望。
业务影响: dHCI可以提供更高的敏捷性,降低的服务成本以及增加达到服务水平的可能性。成功实施dHCI解决方案的I&O领导者将把dHCI视为一项战略投资,该投资可实现自动化,敏捷的体系结构,从而提供现代业务所需的灵活性和可扩展性。
福利等级:中等
市场渗透率:目标受众的1%至5%
成熟度:新兴
供应商样本: Datrium;HPE;NetApp
我们知道,Nutanix发明了HCI,而且Nutanix也是HCI市场的领导者,虽然后来VMware迎头赶上。dHCI这个概念是Datrium发明的,但Datrium做得并不好,目前已经被VMware收购,而且其dHCI产品线停止销售,VMware只保留其DRaaS产品。现在市场上主推dHCI的主要是NetApp(NetApp没有HCI),后来HPE也加入(HPE一直有HCI)。西瓜哥比较看好dHCI,存储的厂商都比较喜欢dHCI,服务器厂商更喜欢HCI。dHCI如果采用SDS的方式,存储和计算独立扩展,但使用体验和HCI一样。大家需要注意的是,dHCI在市场数据统计的时候,Gartner是算在融合系统里,但不算在超融合里,但IDC是算在HCI市场里的。因此,以后dHCI市场如果起来的话,Gartner说的超融合和IDC说的HCI的市场数据可能差距会很大。
我们看到,存储技术也在发展,虽然没有互联网发展那么快。但存储是以稳为主的,可靠性比速度更重要。虽然存储现在没有那么火了,但我还是会继续坚持研究存储,继续和大家分享存储的学习经验。这个Gartner的报告其实7月6日就发布了,我一直没有解读,是希望里面有一些样本公司购买这份报告的reprint权限,这样我解读的时候就可以把原文分享给大家。但可惜的是,到目前为止,没有任何一家公司免费分享这份报告,大家只能看我的解读了,暂时没有机会看原文了。

本文分享自微信公众号 - 高端存储知识(High-end_Storage)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












