

HBase作为一个分布式存储的数据库,它是如何保证可用性的呢?对于分布式系统的CAP问题,它是如何权衡的呢?
最重要的是,我们在生产实践中,又应该如何保证HBase服务的高可用呢?
下面我们来仔细分析一下。
1. 什么是分布式系统的CAP?
CAP是指一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)。
- Consistency 一致性
一致性指更新操作成功并返回客户端完成后,分布式系统中所有节点在同一时间的数据完全一致。
从客户端的角度来看,一致性主要指的是并发访问时获取的数据一致。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
对于数据库来说,如果要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
- Availability 可用性
可用性指服务一直可用,整个系统是可以正常响应的。一般我们在衡量一个系统的可用性的时候,都是通过停机时间来计算的。我们经常说的3个9,4个9的SLA,就是对于可用性的量化表述。
- Partition Tolerance分区容错性
分区容错性指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
而CAP定理证明,一个分布式系统最多只能同时满足这三项中的两项。
由于分布式系统中必然存在网络分区,所以对于分布式系统而言,一般分为CP系统和AP系统。
也就是说,如果出现故障了,到底是选择可用性优先(AP)呢?还是选择一致性优先(CP)?
2.HBase的CAP权衡
HBase作为分布式数据库,同样满足CAP理论,那它是AP系统,还是CP系统呢?
我们从HBase的故障恢复过程来分析一下。
当某台region server fail的时候,它管理的region failover到其他region server时,需要根据WAL log(Write-Ahead Logging)来redo,这时候进行redo的region应该是不可用的,客户端请求对应region数据时,会抛出异常。
因此,HBase属于CP型架构,降低了可用性,具备强一致性读/写。
设想一下,如果redo过程中的region能够响应请求,那么可用性提高了,则必然返回不一致的数据(因为redo可能还没完成),那么hbase的一致性就降低了。
3.HBase的可用性分析
作为一个CP系统,HBase的可用性到底如何,我们还需要进一步分析它的各个组件。
下面是一个HBase集群的相关组件。
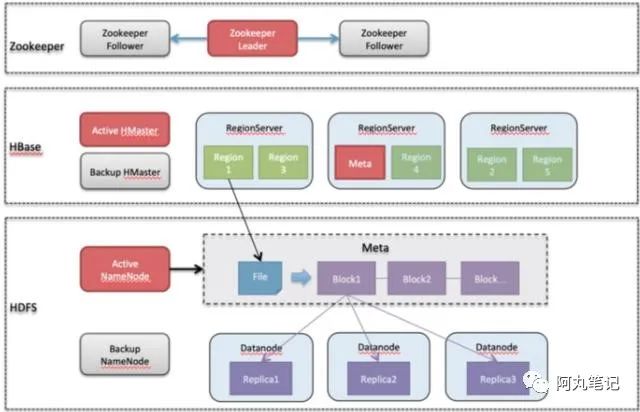
以HBase 单集群 2个master + 3个core 节点作为例子,各个组件的部署情况如下:
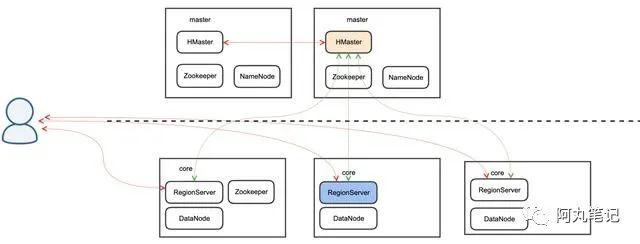
HBase:
两个HMaster互为主备,保证高可用
蓝色的region server表示会存有meta table
用户缓存meta table信息,直接与region server交互,查询,不需要经过HMaster
core可以横向扩展,存在多个region server和data node。
Zookeeper:
- 三节点集群
HDFS:
- 两个namenode,多个DataNode
在这样的部署下,各个组件的可用性分析如下:
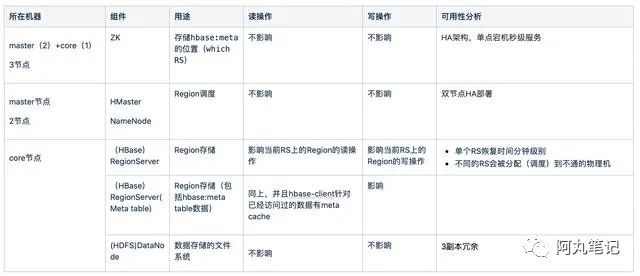
从上面的分析可以看到,HBase的不可用风险主要有两个:
1)某个region server不可用,导致该region server上的流量有分钟级的不可读写
2)集群整体不可用,所有流量不可读写
4. 如何提高HBase可用性
4.1 Region replica
上面提到了HBase为了保证数据的强一致性,在可用性上有所牺牲,根本原因是虽然是三副本的数据存储,但是同一时刻只有一个“在线”Region(保证一致性),所以一旦该region不可用,需要通过日志回放来重新拉起一个新的region,而且此时region不可读写(保证一致性)。
因此,如果能增加“在线”的Region数量,就可以提高可用性了,可以参考这个Region replica(https://issues.apache.org/jira/browse/HBASE-10070 )。需要注意,副本region只能作为读,不能作为写。因此主region挂了以后,仍然会有不可写入时间。
这个特性没有很多的生产实践案例,风险较高,因此不建议使用。
4.2 主备集群
既然单集群HBase的可用性不够,我们自然而然会想到可以使用主备集群来提高可用性。
如果一个集群的稳定性是99.9%, 那么两个独立集群的组合的稳定性是 1 - 0.1 * 0.1 = 99.99%。采用主备集群服务同一份数据,可以在最终一致性条件下提升一个数量级的稳定性。
我们参考下阿里云HBase的主备集群模式,一般有两种模式,主备双活与主备容灾。
1)主备双活(active-active模式)
可以实现两方面的能力,降低毛刺与自动容错
- 降低毛刺
当客户端发起请求后,会首先向主集群发起请求,在等待一段时间(Glitch Time)后如果主库仍没有返回结果,则并发向备库发起请求,最终取最快返回的值作为结果。

- 自动容错
当主集群连续抛错或者连续超时超过用户指定次数时,即判定主集群存在故障需要进行”切换”,在切换状态下在主库服务恢复可以进行正常访问的情况会进行自动回切,对用户完全透明。
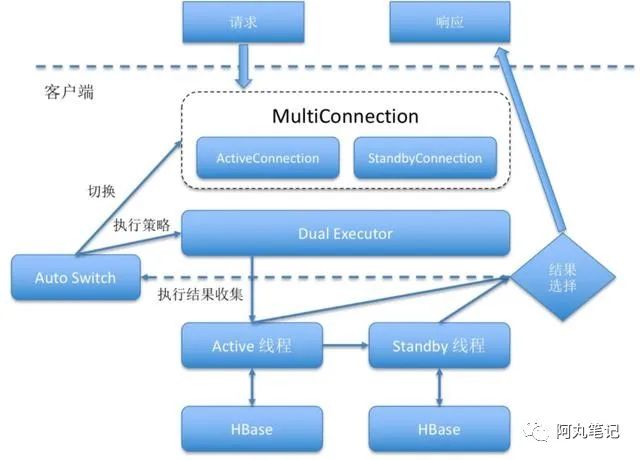
优点:
- 主备双活能大大提高HBase服务的可用性,能实现region server宕机的快速恢复和集群整体不可用的快速恢复。
缺点:
- 牺牲一致性后换来的高可用性。既然主备集群之间需要数据同步,那么必然存在延迟,那么在自动切换读取备集群的时候,就可能存在数据不一致的情况。而且数据不一致可能是一种低概率的常态化情况。
2)主备容灾(active-standby模式)
同样是主备集群,但是正常情况下都是访问主集群。如果主集群出现故障,那么就可以通过手动切换的方式,快速切换到备集群。
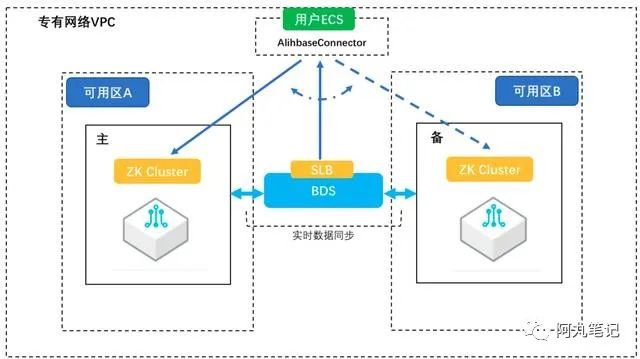
优点:
主备容灾在故障时能快速恢复,大大降低故障恢复时间,提高可用性。能实现region server宕机的快速恢复和集群整体不可用的快速恢复。
只有在切换到过程中,可能存在数据不一致的情况。
缺点:
无法像主备双活那样降低毛刺
手动切换,切换不够迅速、丝滑
4.3 互备双活
主备集群的方案虽然大大提高了可用性,但是我们可以明显感受到的是,成本double了。日常情况下,备用集群一般都是闲置的。这对于生产实践来说,是不容忽视的考虑因素。
因此,我们在主备集群的基础上,可以考虑“互为主备”的方案。
所谓“互为主备”,就是两个业务有各自的HBase集群,同时,通过数据双向同步,在对方的集群中备份数据,作为备集群。
得益于HBase的存储与计算分离的特点,我们只需要冗余存储,而不需要冗余计算资源。
优点:
通过主备集群的基础架构,提高了可用性,比如一般的某个region server宕机,可以大大提高恢复速度。
降低了成本,不再需要完全的double成本,且有一个集群日常空闲
缺点:
- 无法支持集群整体不可用后的切换。由于两个集群都是以自身业务容量来规划使用的,虽然日常安全使用水位是60%以下,可以支持region server宕机的流量切换,但是如果整个集群不可用导致的整个集群切换,那么势必会冲垮备用集群(除非冗余计算资源,那么还是成本double了,没有意义)。
5.总结
我们分析了HBase单集群的可用性,然后针对HBase的CP型分布式系统,给出了通过主备集群提高可用性的方案。并且,根据成本考虑,给出了非集群故障下的“互备双活”方案。
我们需要根据业务的重要程度、对于不可读写的容忍程度来评估具体的可用性方案,希望能对大家有所启发。
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
扫描下方二维码可以关注我哦~

觉得不错,就点个 再看 吧👇
本文分享自微信公众号 - 阿丸笔记(aone_note)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












