
在哪里下载druid
正式版本下载:
maven中央仓库: http://central.maven.org/maven2/com/alibaba/druid/
怎么获取Druid的源码
Druid是一个开源项目,源码托管在github上,源代码仓库地址是 https://github.com/alibaba/druid。同时每次Druid发布正式版本和快照的时候,都会把源码打包,你可以从上面的下载地址中找到相关版本的源码
怎么配置maven
Druid 0.1.18 之后版本都发布到maven中央仓库中,所以你只需要在项目的pom.xml中加上dependency就可以了。例如:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid-version}</version>
</dependency>
也可以选择 Maven仓库查找公共的仓库地址:http://www.mvnrepository.com/artifact/com.alibaba/druid
怎么打开Druid的监控统计功能
Druid的监控统计功能是通过filter-chain扩展实现,如果你要打开监控统计功能,配置StatFilter,具体看这里:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilter
怎样使用Druid的内置监控页面
内置监控页面是一个Servlet,具体配置看这里:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatViewServlet%E9%85%8D%E7%BD%AE
内置监控中的Web和Spring关联监控怎么配置?
- Web关联监控配置
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_%E9%85%8D%E7%BD%AEWebStatFilter - Spring关联监控配置
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_Druid%E5%92%8CSpring%E5%85%B3%E8%81%94%E7%9B%91%E6%8E%A7%E9%85%8D%E7%BD%AE
怎么配置防御SQL注入攻击
Druid提供了WallFilter,它是基于SQL语义分析来实现防御SQL注入攻击的。具体配置看这里:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE-wallfilter
Druid有没有参考配置
不同的业务场景需求不同,你可以使用我们的参考配置,但建议你仔细阅读相关文档,了解清楚之后做定制配置。https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_DruidDataSource%E5%8F%82%E8%80%83%E9%85%8D%E7%BD%AE
我想日志记录JDBC执行的SQL,如何配置
Druid提供了Log4jFilter、CommonsLogFilter和Slf4jFilter,具体配置看这里https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_LogFilter
我的程序可能产生连接泄漏了,有什么办法?
Druid提供了多种监测连接泄漏的手段,具体看这里:https://github.com/alibaba/druid/wiki/%E8%BF%9E%E6%8E%A5%E6%B3%84%E6%BC%8F%E7%9B%91%E6%B5%8B
在Druid中使用PSCache会有内存占用过大问题么?
连接Oracle数据库,打开PSCache,在其他的数据库连接池都会存在内存占用过多的问题,Druid是唯一解决这个问题的连接池。具体看这里:https://github.com/alibaba/druid/wiki/Oracle%E6%95%B0%E6%8D%AE%E5%BA%93%E4%B8%8BPreparedStatementCache%E5%86%85%E5%AD%98%E9%97%AE%E9%A2%98%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88
有没有和其他数据库连接池的对比?
从其他连接池迁移要注意什么?
- 不同连接池的参数参照对比: http://code.alibabatech.com/wiki/pages/viewpage.action?pageId=6947005
- DBCP迁移 https://github.com/alibaba/druid/wiki/DBCP%E8%BF%81%E7%A7%BB
Druid中有没有类似Jboss DataSource中的ExceptionSorter
ExceptionSorter是JBoss DataSource中的优秀特性,Druid也有一样功能的ExceptionSorter,但不用手动配置,自动识别生效的。具体看这里:https://github.com/alibaba/druid/wiki/ExceptionSorter_cn
Druid中的maxIdle为什么是没用的?
maxIdle是Druid为了方便DBCP用户迁移而增加的,maxIdle是一个混乱的概念。连接池只应该有maxPoolSize和minPoolSize,druid只保留了maxActive和minIdle,分别相当于maxPoolSize和minPoolSize。
我的应用配置的是JNDI数据源,可以用DruidDataSource么?
DruidDataSource支持JNDI配置,具体看这里:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_JNDI_Tomcat
具体实现的类是这个:com.alibaba.druid.pool.DruidDataSourceFactory,你可以阅读代码加深理解。
我的应用已使用DBCP,是代码中写死的,怎样更换为Druid?
可以的,Druid提供了一个中完全平滑迁移DBCP的办法。
- 从http://repo1.maven.org/maven2/com/alibaba/druid/druid-wrapper/ 下载druid-wrapper-xxx.jar
- 加入druid-xxx.jar
- 从你的WEB-INF/lib/中删除dbcp-xxx.jar
- 按需要加上配置,比如JVM启动参数加上-Ddruid.filters=stat,动态配置druid的filters
这种用法,使得可以在一些非自己开发的应用中使用Druid,例如在sonar中部署druid,sonar是一个使用jruby开发的web应用,写死了DBCP,只能够通过这种方法来更换。
我想试用快照版本,怎么获取?
直接获取快照版本的地址是:http://code.alibabatech.com/mvn/snapshots/com/alibaba/druid/ ,使用快照版本建议加入我们QQ群 92748305,遇到问题直接反馈给我们。
有一些SQL执行很慢,我希望日志记录下来,怎么设置?
在StatFilter配置中有慢SQL执行日志记录,看这里https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilter
我希望加密我的数据库密码怎么办?
运维和DBA都不希望把密码明文直接写在配置文件中,Druid提供了数据库秘密加密的功能。具体看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter
如何参与Druid的开发
Druid是一个通过github开源的项目,github的特性,使得你很容易参与其中。这里有详细说明https://github.com/alibaba/druid/wiki/%E5%A6%82%E4%BD%95%E5%8F%82%E4%B8%8E
Druid的发布周期是怎样?
Druid是一个活跃的项目,长期维护。每个月有一个发布窗口,除非遇到重大bug和非常紧急的需求,否则都是每个月最多发布一次。如果没有足够多的需求,发布窗口就不会被使用。
如果DruidDataSource在init的时候失败了,不再使用,是否需要close
是的,如果DruidDataSource不再使用,必须调用close来释放资源,释放的资源包括关闭Create和Destory线程。
DruidDataSource支持哪些数据库?
理论上说,支持所有有jdbc驱动的数据库。实际测试过的有
数据库
支持状态
mysql
支持,大规模使用
oracle
支持,大规模使用
sqlserver
支持
postgres
支持
db2
支持
h2
支持
derby
支持
sqlite
支持
sybase
支持
Oracle下jdbc executeBatch时,更新行数计算不正确
使用jdbc的executeBatch 方法,如果数据库为oracle,则无论是否成功更新到数据,返回值都是-2,而不是真正被sql更新到的记录数,这是Oracle JDBC Driver的问题,Druid不作特殊处理。
Druid如何自动根据URL自动识别DriverClass的
Druid是根据url前缀来识别DriverClass的,这样使得配置更方便简洁。
前缀
DriverCLass
描述信息
jdbc:odps
com.aliyun.odps.jdbc.OdpsDriver
jdbc:derby
org.apache.derby.jdbc.EmbeddedDriver
jdbc:mysql
com.mysql.jdbc.Driver
jdbc:oracle
oracle.jdbc.driver.OracleDriver
jdbc:microsoft
com.microsoft.jdbc.sqlserver.SQLServerDriver
jdbc:sybase:Tds
com.sybase.jdbc2.jdbc.SybDriver
jdbc:jtds
net.sourceforge.jtds.jdbc.Driver
jdbc:postgresql
org.postgresql.Driver
jdbc:fake
com.alibaba.druid.mock.MockDriver
jdbc:mock
com.alibaba.druid.mock.MockDriver
jdbc:hsqldb
org.hsqldb.jdbcDriver
jdbc:db2
COM.ibm.db2.jdbc.app.DB2Driver
DB2的JDBC Driver十分混乱,这个匹配不一定对
jdbc:sqlite
org.sqlite.JDBC
jdbc:ingres
com.ingres.jdbc.IngresDriver
jdbc:h2
org.h2.Driver
jdbc:mckoi
com.mckoi.JDBCDriver
jdbc:cloudscape
COM.cloudscape.core.JDBCDriver
jdbc:informix-sqli
com.informix.jdbc.IfxDriver
jdbc:timesten
com.timesten.jdbc.TimesTenDriver
jdbc:as400
com.ibm.as400.access.AS400JDBCDriver
jdbc:sapdb
com.sap.dbtech.jdbc.DriverSapDB
jdbc:JSQLConnect
com.jnetdirect.jsql.JSQLDriver
jdbc:JTurbo
com.newatlanta.jturbo.driver.Driver
jdbc:firebirdsql
org.firebirdsql.jdbc.FBDriver
jdbc:interbase
interbase.interclient.Driver
jdbc:pointbase
com.pointbase.jdbc.jdbcUniversalDriver
jdbc:edbc
ca.edbc.jdbc.EdbcDriver
jdbc:mimer:multi1
com.mimer.jdbc.Driver
如何保存监控记录
我想Log输出SQL执行的信息怎么办?
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_LogFilter
如何配置Druid内置的log实现
示例项目:
https://github.com/windwant/spring-dubbo-service.git
https://github.com/windwant/spring-boot-service.git
Druid 是一个开源的,能够在大型数据集 (100’s of Billions entries, 100’s TB data)上面提供实时试探性查询的分析数据存储,Druid提供了廉价的,并且是持续的实时数据集成和任意数据探索的能力。
Druid的主要功能
- 为分析而生 - Druid是为了解决在OLAP workflows中进行探索分析而生的. 它提供了大量的filters, aggregators和 query 类型,并且提供了一个允许用户自定义插件从而来实现新功能的框架. 用户可以利用Druid的系统架构很简单的开发类似于top K和直方图等功能。
- 交互式查询 - Druid的低延时数据集成框架允许数据在生成之后的毫秒范围之内就可以被用户查询到。Druid通过读且只读需要的数据来优化查询的时延。
- 高可用性 - Druid可以被用来实现需要持续提供服务的SaaS应用。即使是在系统升级的过程中,你的数据仍然可以被查询。而且Druid cluster的扩容或者缩减不会带来数据的丢失。
- 可扩展性 - 现有的Druid系统可以很轻松的处理每天数十亿条记录和TB级别的数据。Druid本身是被设计来解决PB级别数据的。
为什么要用Druid?
Druid的初衷是为了解决在使用Hadoop进行查询时所遇见的高时延问题来满足交互性服务的需求的。
尤其是当你对data进行汇总之后并在你汇总之后的数据上面进行查询时效果更好。将你汇总之后的数据注入Druid,随着你的数据量在不断增长,你仍然可以对Druid的查询能力非常有信心。
当前的Druid安装实例已经可以很好的处理以2TB每小时实时递增的数据量。
你可以在拥有Hadoop的同时创建一个Druid系统。Druid提供了以一种互动切片、切块方式来访问数据的能力,它在查询的灵活性和存储格式直接寻找平衡从而来提供更好的查询速度。
如果想了解更多细节,请参考 White Paper 和 Design 文档.
什么情况下需要Druid?
- 当你需要在大数据集上面进行快速的,交互式的查询时
- 当你需要进行数据分析,而不只是简单的键值对存储时
- 当你拥有大量的数据时 (每天新增数百亿的记录、每天新增数十TB的数据)
- 当你想要分析实时产生的数据时
- 当你需要一个24x7x365无时无刻可用的数据存储时
什么情况下不需要用Druid?
- 当数据量可以在MySQL中很轻松的处理时
- 当你在查询某一天具体的记录而不是做分析时
- 当批量数据集成对你来说已经足够好的情况下
- 当你只需要执行固定的查询时
- 当系统偶尔down也没什么大不了的时候
Druid vs…
之在在项目中使用时序DB的时候,使用的是InfluxDB, 后来随着数据量的增大,InfluxDB无法满足需求(在数据量在百万以下使用InfluxDB真的很好用),在一个偶然的机会下看了Druid,当时还是8.x版本,经过两周的试用测试,性能表现完美,可以做到PB级数据的快速聚合查询
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析
Druid的具有以下主要特征:
- 为分析而设计——Druid是为OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类。
- 快速的交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到。
- 高可用性——Druid的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失。
- 可扩展——Druid每天能够处理数十亿事件和TB级数据。
现在Druid已经到了9.x版本,新版本在稳定性已经相当好,而且和Hadoop、kafka等结合的更紧密
节点介绍
Druid是由一组不同角色的节点,每种节点都是一个单独的子系统负责不同的功能,这些节点组成一个系统协同工作,我们来看一下Druid的整体架构见下图
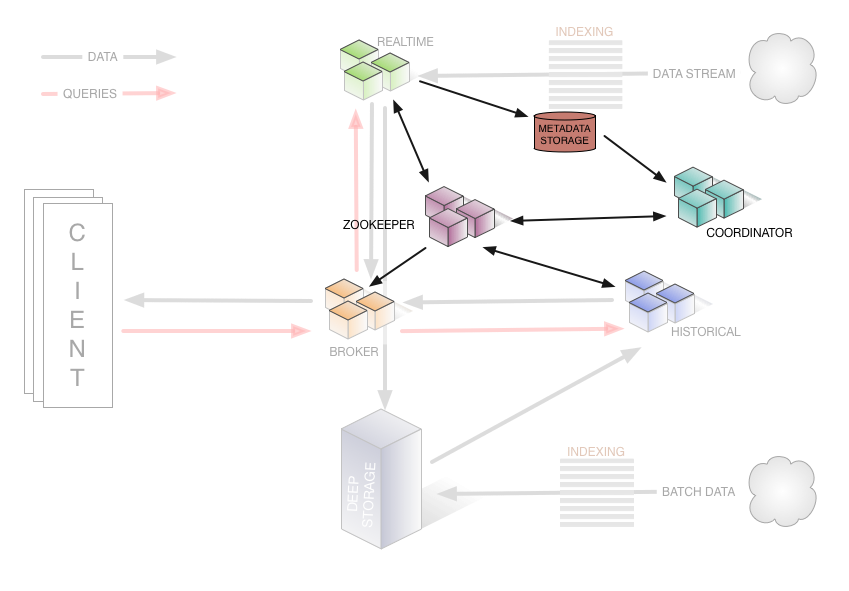
Coordinator Node
监控Historical节点组,以确保数据可用、可复制,并且在一般的“最佳”配置。它们通过从MySQL读取数据段的元数据信息,来决定哪些数据段应该在集群中被加载,使用Zookeeper来确定哪个Historical节点存在,并且创建Zookeeper条目告诉Historical节点加载和删除新数据段。
Historical Node
是对“historical”数据(非实时)进行处理存储和查询的地方。Historical节点响应从Broker节点发来的查询,并将结果返回给broker节点。它们在Zookeeper的管理下提供服务,并使用Zookeeper监视信号加载或删除新数据段。
Broker Node
接收来自外部客户端的查询,并将这些查询转发到Realtime和Historical节点。当Broker节点收到结果,它们将合并这些结果并将它们返回给调用者。由于了解拓扑,Broker节点使用Zookeeper来确定哪些Realtime和Historical节点的存在。
Real-time Node
实时摄取数据,它们负责监听输入数据流并让其在内部的Druid系统立即获取,Realtime节点同样只响应broker节点的查询请求,返回查询结果到broker节点。旧数据会被从Realtime节点转存至Historical节点。
ZooKeeper
为集群服务发现和维持当前的数据拓扑而服务;
MySQL
用来维持系统服务所需的数据段的元数据;
Deep Storage
保存“冷数据”,可以使用HDFS。
实践
在其中一个项目中使用Druid,验证了Druid的能力,约使用了10台机器(其中Druid集群 4 台,HDFS 3 台,web一台, 其它2台),项目结构如下图
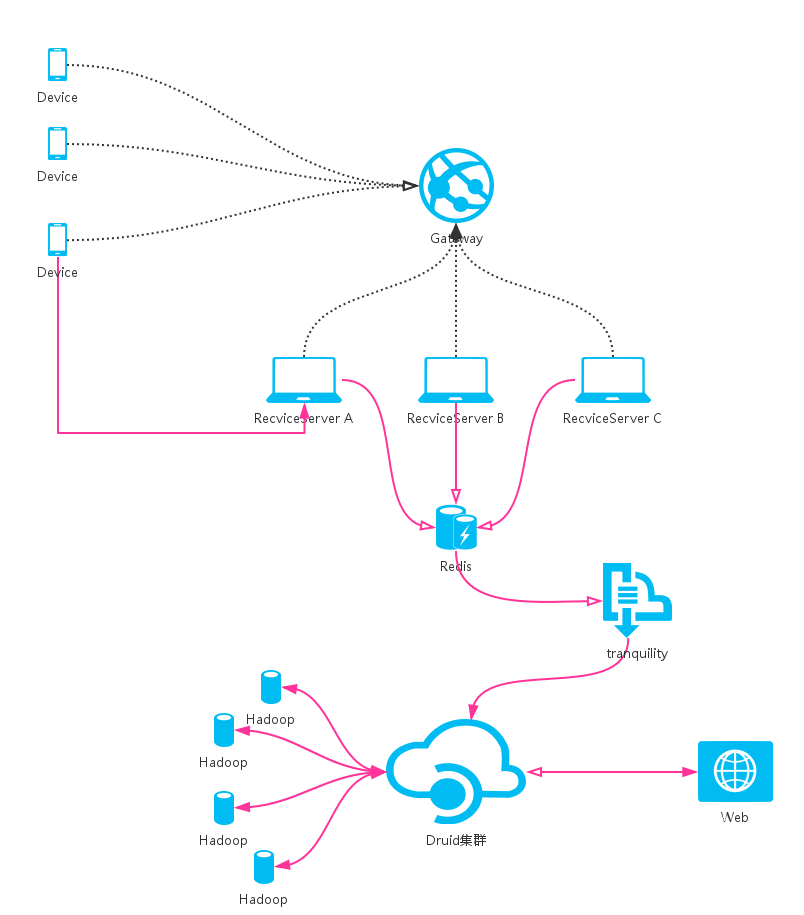
接收数据端使用Golang,快速的构建了一个分布式,性能还不错的接收服务,其中一个数据接收结点,每天千万级报活,每天上传近亿条数据,聚合查询半月内的数据(约10亿条),秒级可返回结果,完美解决问题。
之于为什么没选择Mysql?因为较大数据量下,本人功力有限,实在玩不转Mysql。综合需求最终总结为: 需要一个对于时序支持较好,可以海量数据快速查询,并且高可用的分布式的列存储系统, 因此最终决定尝试 Druid。
目前在国内使用Druid的企业越来越多,其中包括小米、嘀嘀、去那儿、猎豹、优酷等。
官方的使用文档写的相当不错,具体细节请移步至Druid Doc(0.9)
和其它项目的关系











