
使用分组、聚合和映射-归并
MongoDB的强大功能之一,是直接在服务器对文档的值进行复杂的操作,而不用先发文档发送到客户端在进行处理。
结果分组
对大型数据集进行查询操作时,通常会根据文档的字段值对其进行分组。这可以在取回文档后通过代码来完成,但在服务器端查找的同时进行分组效率跟高。
要将查询结果分组,可使用Collection对象的方法 group()。该语法为:
db.collection_name.group({key, reduce, initial, [keyf], [cond], finalize})
参数列表:
- key:指定要根据哪些健进行分组。其属性为要用于分组的字段,值为 1。
- reduce:一个接受参数 obj 和 prev 的函数( function(obj,prev))。对于每个与查询匹配的文档,都执行这个参数。其中参数 obj 为当前文档,而 prev 是根据参数 initial 创建的对象。(可以通过obj来更新prev,如计数或累计)。
- initial:可以创建一个group分组字段,并包含初始值,用于在分组期间聚合数据。(常见的是使用一个计数器来跟踪匹配的文档数。{ initial : {"count" : 0 } } )。
- keyf:可选。指定一个函数,这个函数返回一个用于分组的key对象,用于替代参key。这样可以使用函数动态地指定根据哪些字段分组。
- cond:可选。查找条件,表示从哪些结果集中进行分组。
- finalize:可选。在reduce执行之后,结果集返回之前,对结果集进行的最终操作。可以精简数据。
示例:
数据集:

执行分组命令:
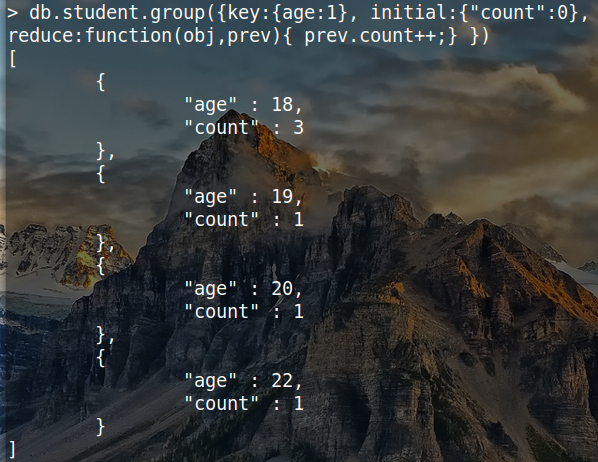
db.student.group({
key:{age:1},
initial:{"count":0},
reduce:function(obj,prev) {
prev.count++;
}
})
MongoDB聚合
理解 aggregate() 方法
Collection对象提供了对数据执行聚合操作的方法 aggregate()。该方法主要用于数据处理(诸如统计平均值,求和等),并返回计算的结果。
db.collection_name.aggregate( operator, [ operator ,...] )
参数 operator 是一系列聚合运算符,让您指定要在流水线的各个阶段对数据执行哪种聚合操作。执行的一个运算符后,将结果传给下一个运算符继续运算。
该方法直接返回一个包含聚合结果的迭代器。

使用聚合框架运算符
MongoDB提供的聚合框架非常强大,通过 aggrgate() 方法可以反复将一个聚合运算符的结果传递给下一个运算符。
注意在引用文档中的字段名时,需要在字段名前加 $ ,表示这是一个字段值而不是字符串。
运算符
描述
示例
$project
通过重命名、添加或删除字段来重新定义文档。还能重新计算值以及添加子文档
{ $project : { title : " $name " } }
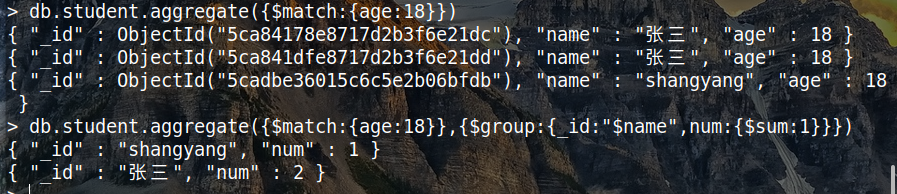
$match
可以实现查找的功能
{ $match : { value : { $gt : 50 } } }
$limit
限制文档数,返回结果集中的前 n 个数
{ $limit : 5 }
$skip
丢弃结果集中的前 n 个文档,效率较低,依然会遍历前 n 个文档
{ $skip : 5 }
$unwind
其值必须是数组字段的名称。对指定的数组进行分拆,为其中的每个值创建一个文档
{ $unwind : { $myArr } }
$group
将文档分组并生成新的文档,可以进行一系列子命令
{ $group : { _id : " $name " , num : { $sum : 1 } } }
$sort
将文档排序
{ $sort : { name : 1 , age : -1 } }
MapReduce() 方法
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
db.collection_name.mapReduce( map , reduce , arguments );
其中 map 是一个函数,用于分组,它将对数据集的每个对象执行它来生成一个键和值,这些值被加入到与键相关联的数组中,供归并阶段使用。
// map 函数
function() {
emit ( key , value );
}
参数 reudce 也是一个函数,将对 map 函数生成的每个对象执行它。reduce 函数必须将键作为第一个参数,将与键相关联的值数组作为第二个参数,并使用值数组来计算得到与键相关联的单个值,再返回结果。
// reduce 函数 处理需要统计的字段
function ( key , value ) {
......统计字段处理
return result;
}
参数 arguments 是一个对象,指定了检索传递给 map 函数的文档时使用的选项。
{
out : collection, // 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
query : document, // 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
sort : document, // 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
limit : number // 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
}




