
首发公众号:二进制社区,转载联系:binary0101@126.com
导读
"K8S为我们提供自动部署调度应用的能力,并通过健康检查接口自动重启失败的应用,确保服务的可用性,但这种自动运维在某些特殊情况下会造成我们的应用陷入持续的调度过程导致业务受损,本文就生产线上一个核心的平台应用被K8S频繁重启调度问题展开剖解,抽丝剥茧一步步从系统到应用的展开分析,最后定位到代码层面解决问题"
现象
在搭建devops基础设施后,业务已经全盘容器化部署,并基于k8s实现自动调度,但个别业务运行一段时间后会被k8s自动重启,且重启的无规律性,有时候发生在下午,有时发生在凌晨,从k8s界面看,有的被重启了上百次:
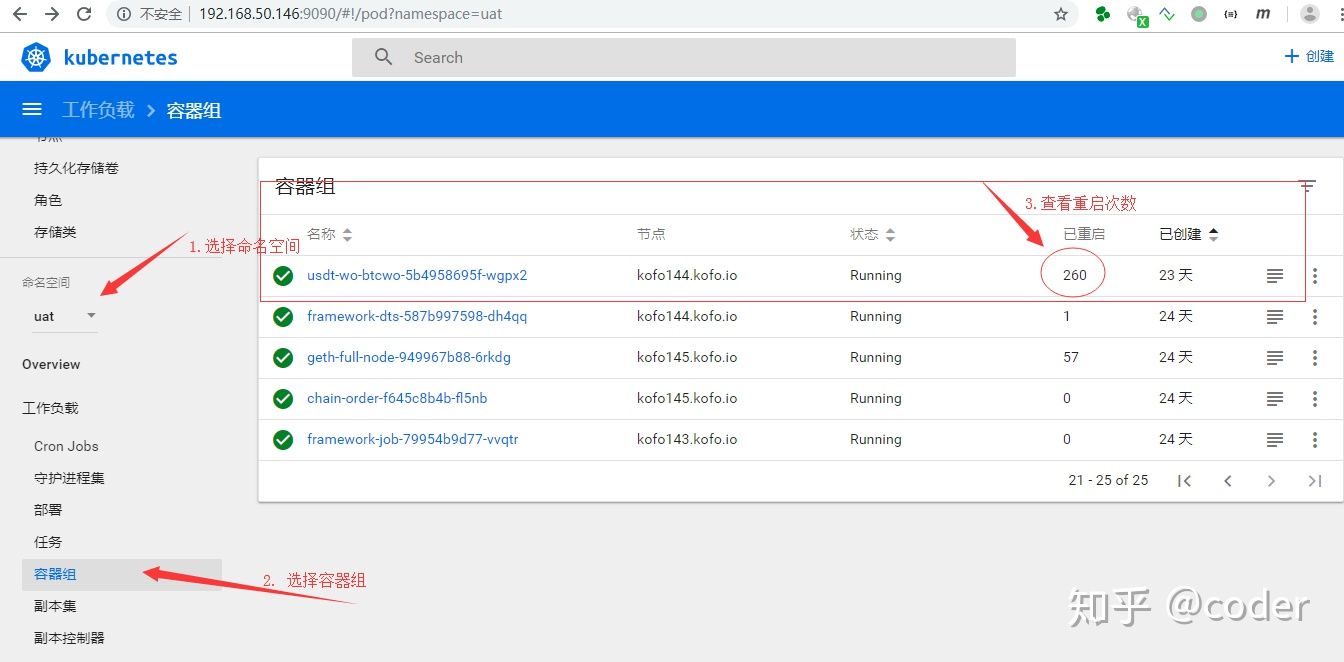
分析
平台侧分析:了解平台的重启策略
k8s是根据pod yaml里定义的重启策略执行重启,这个策略通过: .spec.restartPolicy 进行设置,支持以下三种策略:
- Always:当容器终止退出后,总是重启容器,默认策略。
- Onfailure:当容器种植异常退出(退出码非0)时,才重启容器。
- Never:当容器终止退出时,才不重启容器。
出问题的应用是走CICD自动打包发布,Yaml也是CD环节自动生成,并没有显示指定重启策略,所以默认采用Always策略,那么k8s在哪些情况会触发重启呢,主要有以下场景:
- 1. POD正常退出
- 2. POD异常退出
- 3. POD使用从CPU超过yaml里设置的CPU上限,或者超过容器所在namespace里配置的CPU上限
- 4. POD使用从内存超过yaml里设置的Memory上限,或者超过容器所在namespace里配置的Memory上限
- 5. 运行时宿主机的资源无法满足POD的资源(内存 CPU)时会自动调度到其他机器,也会出现重启次数+1
- 6. 创建POD时指定的image找不到或者没有node节点满足POD的资源(内存 CPU)需求,会不断重启
出问题的应用正常运行一段时间才出现的重启,并且POD本身的Yaml文件以及所在的namespace并没设置CPU上限,那么可以排除:1 3 4 6, 业务是采用Springboot开发的,如果无故退出,JVM本身会产生dump文件,但由重启行为是K8s自己触发的,即使POD里产生里dump文件,因为运行时没有把dump文件目录映射到容器外面,所以没法去查看上次被重启时是否产生里dump文件,所以2 5都有可能导致k8s重启该业务,不过k8s提供命令可以查看POD上一次推出原因,具体命令如下:
NAMESPACE=prod SERVER=dts POD_ID=$(kubectl get pods -n ${NAMESPACE} |grep ${SERVER}|awk '{print $1}') kubectl describe pod $POD_ID -n ${NAMESPACE}
命令运行结果显示POD是因为memory使用超限,被kubelet组件自动kill重启(如果reason为空或者unknown,可能是上述的原因2或者是不限制内存和CPU但是该POD在极端情况下被OS kill,这时可以查看/var/log/message进一步分析原因),CICD在创建业务时默认为每个业务POD设置最大的内存为2G,但在基础镜像的run脚本中,JVM的最大最小都设置为2G:
exec java -Xmx2g -Xms2g -jar ${WORK_DIR}/*.jar
应用侧分析:剖析解JVM的运行状况
在分析应用运行的环境和,我们进一步分析应用使用的JVM本身的状态,首先看下JVM内存使用情况
命令: jmap -heap {PID}
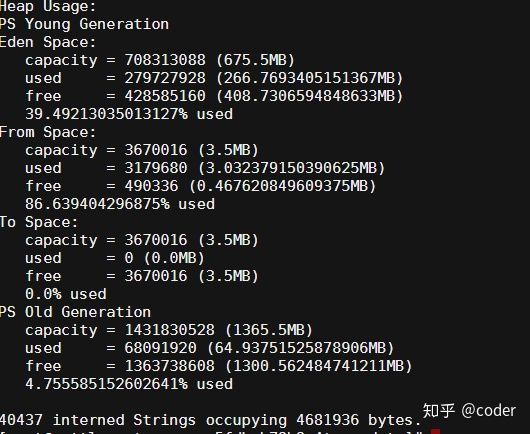
JVM申请的内存: (eden)675.5+(from)3.5+(to)3.5+(OldGeneration)1365.5=2048mb
理论上JVM一启动就会OOMKill,但事实是业务运行一段时间后才被kill,虽然JVM声明需要2G内存,但是没有立即消耗2G内存,通过top命令查看:
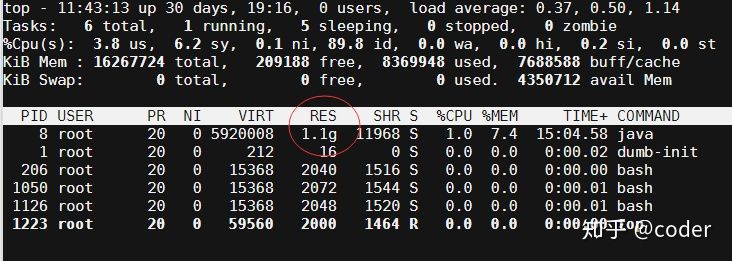
PS: top和free命令在docker里看到的内存都是宿主机的,要看容器内部的内存大小和使用,可以使用下列命令:
cat /sys/fs/cgroup/memory/memory.limit_in_bytes
当配-Xmx2g -Xms2g时,虚拟机会申请2G内存,但提交的页面在首次访问之前不会消耗任何物理存储,该业务进程当时实际使用的内存为1.1g,随着业务运行,到一定时间后JVM的使用内存会逐步增加,直到达到2G被kill。
内存管理相关文章推荐:
Reserving and Committing Memory
代码级分析: 剖解问题的根源
执行命令:
jmap -dump:format=b,file=./dump.hprof [pid]
导入JvisualVM分析,发现里面有大量的Span对象未被回收,未被回收的原因是被队列里item对象引用:
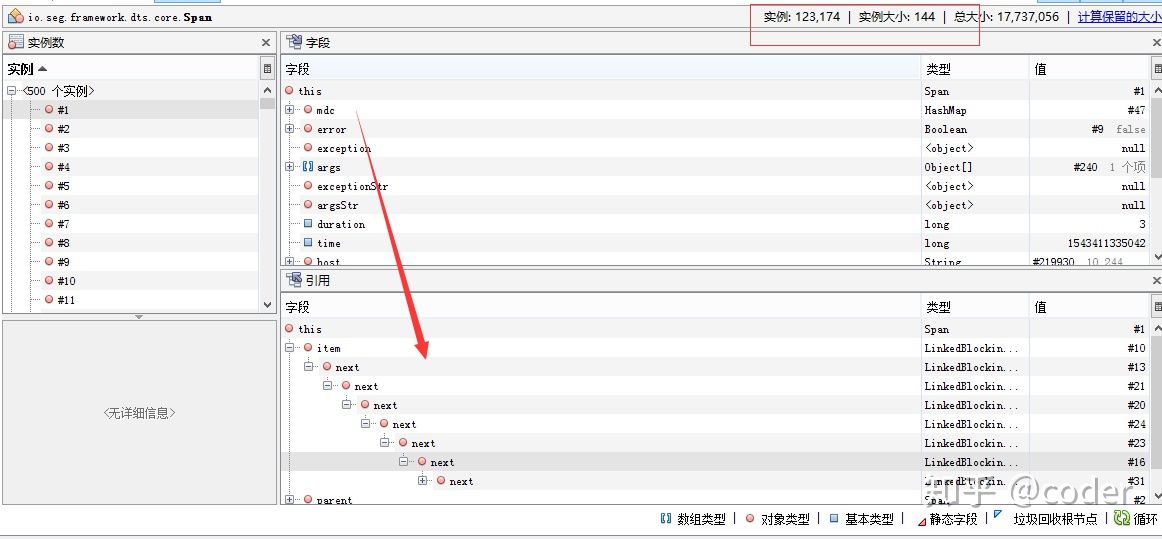
隔断时间执行:
jmap -histo pid |grep Span
发现span对象个数一直在增加,span属于业务工程依赖的分布式调用链追踪系统DTS里的对象,DTS是一个透明化无侵入的基础系统,而该业务也没有显示持有Span的引用,在DTS的设计里,Span是在业务线程产生,然后放入阻塞队列,等待序列化线程异步消费,生产和消费代码如下:
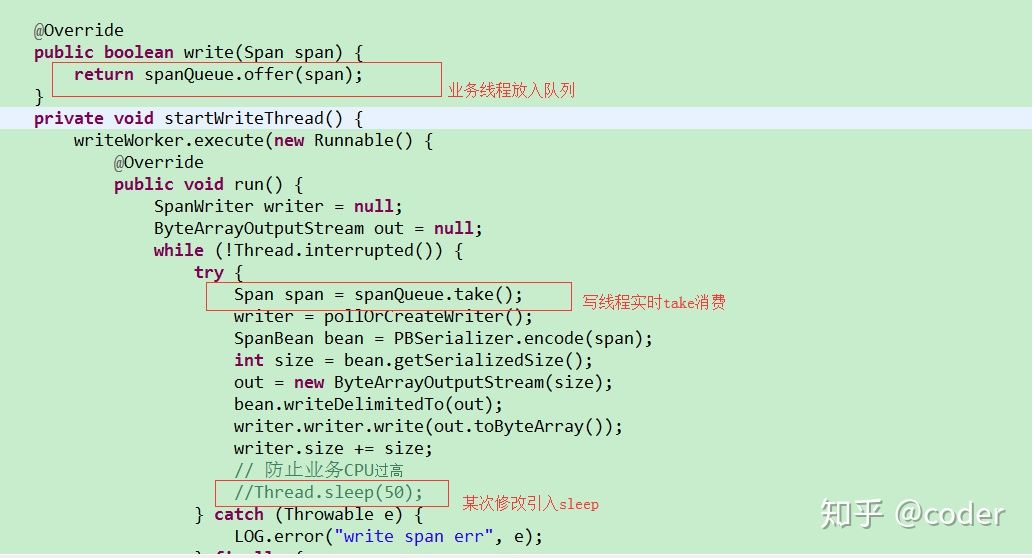
从以上代码看,Span在持续增加,应该就是消费者线程本身的消费速度小于了生产者的速度,消费线程执行的消费逻辑是顺序IO写盘,按照ECS普通盘30-40m的IOPS算,每个Span通过dump看到,平均大小在150byte,理论上每秒可以写:30*1024*1024/150=209715,所以不应该是消费逻辑导致消费率降缓,再看代码里有个sleep(50)也就是每秒最多可以写20个Span,该业务有个定时任务在运行,每次会产生较多的Span对象,且如果此时有其他业务代码在运行,也会产生大量的Span,远大于消费速度,所以出现了对象的积压,随着时间推移,内存消耗逐步增大,导致OOMKill。dump该业务的线程栈:
jstack pid >stack.txt
却发现有两个写线程,一个状态始终是waiting on condition,另一个dump多次为sleep:
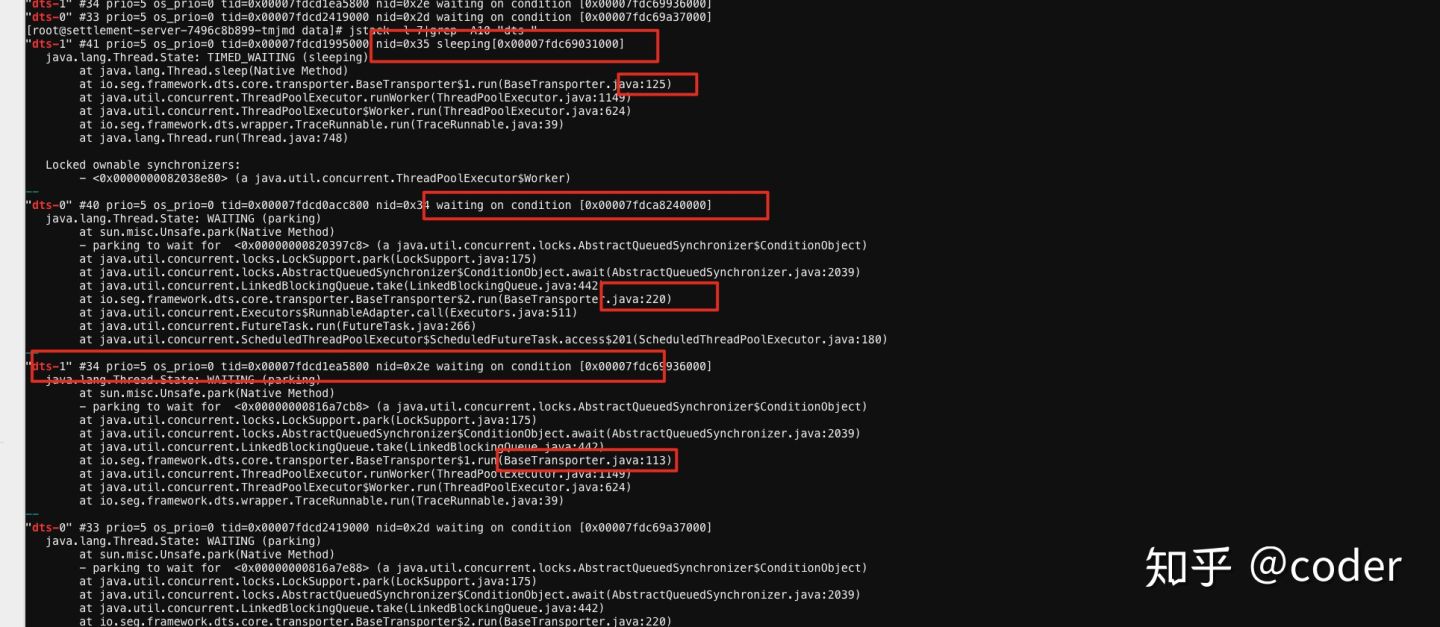
但是代码里是通过Executors.newSingleThreadExecutor(thf);起的单线程池,怎么会出现两个消费者呢? 进一步查看代码记录,原来始终11月份一次修改时把发送后端的逻辑集成到核心代码里,该功能在之前的版本里采用外部jar依赖注入的方式自动装配的,这样在现在的版本中会出现两个Sender对象,其中自动创建的Sender对象没有被DTS系统引用,他里面的队列始终未empty,导致旗下的消费者线程始终阻塞,而内置的Sender对象因为Sleep(50)导致消费速度下降从而出现堆积,Dump时是无法明确捕获到他的running状态,看上去一直在sleep,通过观察消费线程系列化写入的文件,发现数据一直在写入,说明消费线程确实是在运行的.
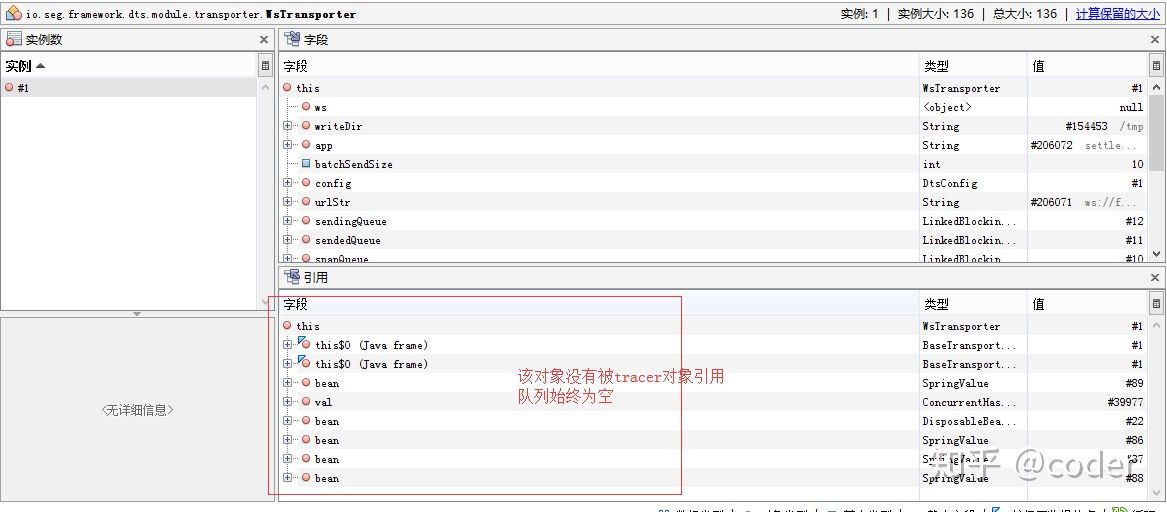
通过代码提交记录了解到,上上个版本业务在某些情况会产生大量的Span,Span的消费速度非常快,会导致该线程CPU飙升的比较厉害,为了缓解这种情况,所以加了sleep,实际上发现问题后业务代码已经进行优化,DTS系统是不需要修改的,DTS应是发现问题,推动业务修复和优化,基础系统的修改应该非常慎重,因为影响面非常广。
针对POD的最大内存等于虚拟机最大内存的问题,通过修改CD代码,默认会在业务配置的内存大小里加200M,为什么是200M不是更多呢?因为k8s会计算当前运行的POD的最大内存来评估当前节点可以容量多少个POD,如果配置为+500m或者更多,会导致K8S认为该节点资源不足导致浪费,但也不能过少过少,因为应用除了本身的代码外,还会依赖部分第三方共享库等,也可能导致Pod频繁重启.
总结
上述问题的根因是人为降低了异步线程的消费速度,导致消息积压引起内存消耗持续增长导致OOM,但笔者更想强调的是,当我们把应用部署到K8S或者Docker时,POD和Docker分配的内存需要比应用使用的最大内存适当大一些,否则就会出现能正常启动运行,但跑着跑着就频繁重启的场景,如问题中的场景,POD指定里最大内存2G,理论上JVM启动如果立即使用里2G肯定立即OOM,开发或者运维能立即分析原因,代价会小很多,但是因为现代操作系统内存管理都是VMM(虚拟内存管理)机制,当JVM参数配置为: -Xmx2g -Xms2g时,虚拟机会申请2G内存,但提交的页面在首次访问之前不会消耗任何物理存储,所以就出现理论上启动就该OOM的问题延迟到应用慢慢运行直到内存达到2G时被kill,导致定位分析成本非常高。另外,对于JVM dump这种对问题分析非常重要的日志,一定要映射存储到主机目录且保证不被覆盖,不然容器销毁时很难去找到这种日志。











