
最近有些朋友问到 Kafka 消费者消费相关的问题,如下:

以上问题看出来这位朋友刚接触 Kafka,我们都知道 Kafka 相对 RocketMQ 来说,消费端是非常 “原生” 的,不像 RocketMQ 将消费线程模型都封装好,用户不用关注内部消费细节。
Kafka 的消费类 KafkaConsumer 是非线程安全的,意味着无法在多个线程中共享 KafkaConsumer 对象,因此创建 Kafka 消费对象时,需要用户自行实现消费线程模型,常见的消费线程模型如下:
1、每个线程维护一个 KafkaConsumer
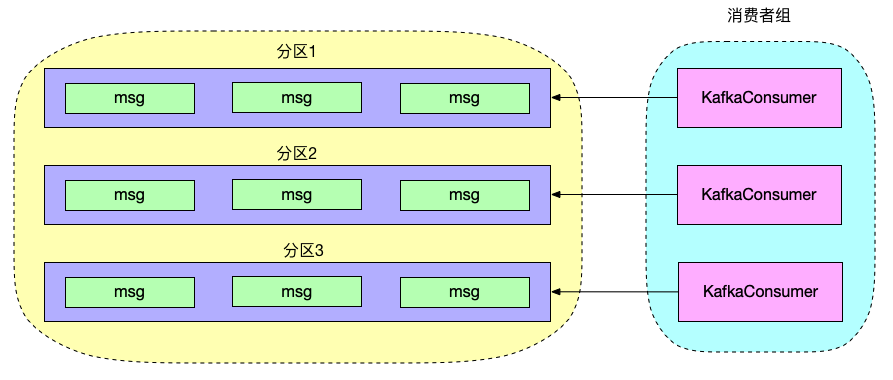
从消费消费模型可看出每个 KafkaConsumer 会负责固定的分区,因此无法提升单个分区的消费能力,如果一个主题分区数量很多,只能通过增加 KafkaConsumer 实例提高消费能力,这样一来线程数量过多,导致项目 Socket 连接开销巨大。
2、单 KafkaConsumer 实例 + 多 worker 线程
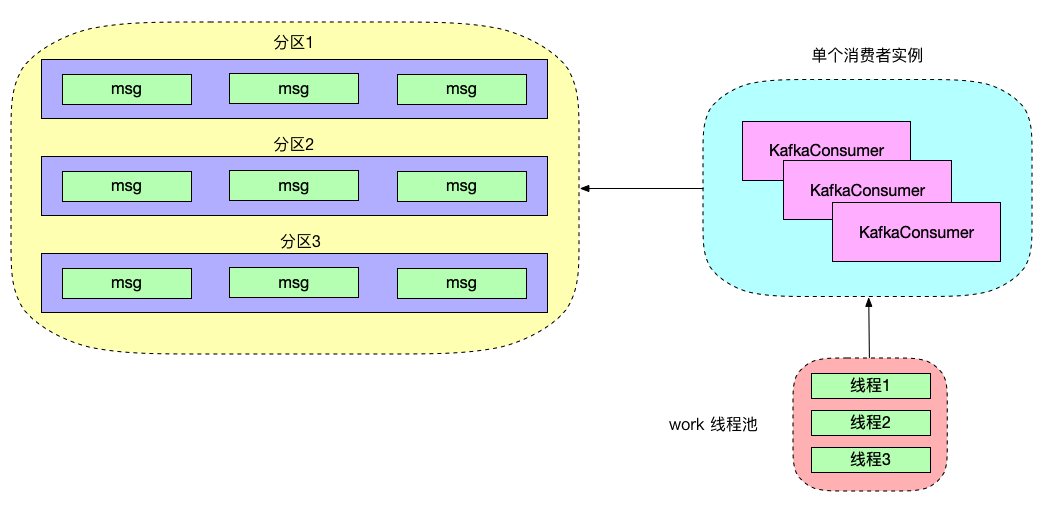
当 KafkaConsumer 实例与消息消费逻辑解耦后,我们不需要创建多个 KafkaConsumer 实例就可进行多线程消费,还可根据消费的负载情况动态调整 worker 线程,具有很强的独立扩展性,在公司内部使用的多线程消费模型就是用的单 KafkaConsumer 实例 + 多 worker 线程模型。
中通消息服务运维平台(ZMS)使用的 Kafka 消费线程模型是第二种:单 KafkaConsumer 实例 + 多 worker 线程。
以下我们来分析 ZMS 是如何实现单 KafkaConsumer 实例 + 多 worker 线程的消费线程模型的。
com.zto.consumer.KafkaConsumerProxy#addUserDefinedProperties
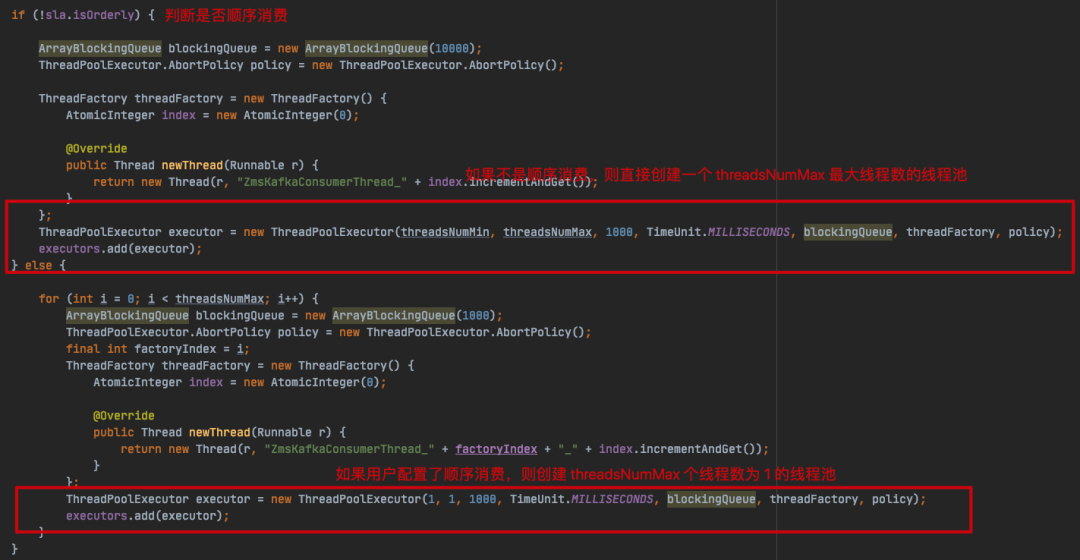
KafkaConsumerProxy 对 KafkaConsumer 进行了一层封装处理,是 ZMS 对外提供的 Kafka 消费对象,在创建一个 KafkaConsumerProxy 对象时,会进行以上属性赋值的具体操作,其中会根据用户配置进行消费线程的设置,从图中可看出,是否顺序消费对创建的线程池也是不一样的,ZMS 为什么会这么做呢?
单 KafkaConsumer 实例 + 多 worker 线程消费线程模型,由于消费逻辑是利用多线程进行消费的,因此并不能保证其消息的消费顺序,如果我们需要在 Kafka 中实现顺序消费,那么需要保证同一类消息放入同一个线程当中,我用如下图表示:
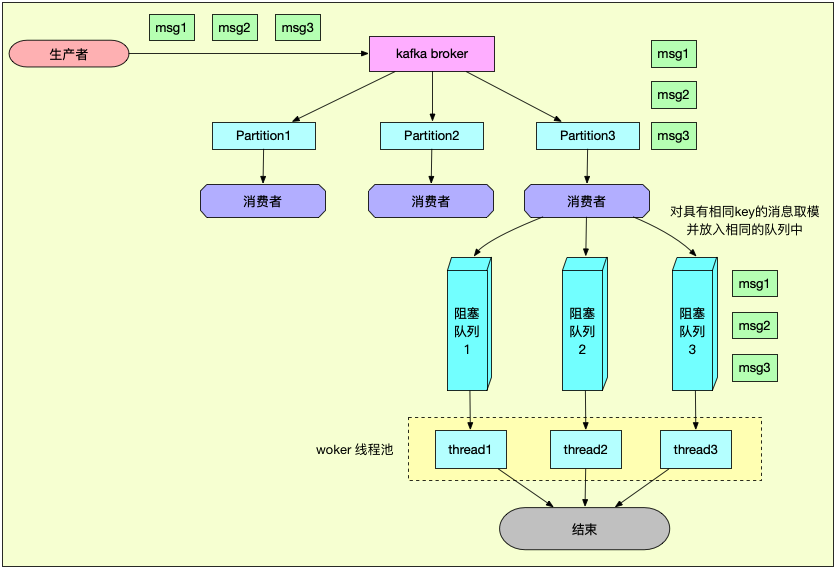
但需要注意的是,以上仅仅是保证正常情况下能够实现顺序消费,如果期间出现重平衡等异常情况,就会导致消费顺序被打乱,不过本身像 RocketMQ 一样是不能保证严格的顺序消费,对于能容忍消息短暂乱序的业务来说,这是一个不错的实现方式。
com.zto.consumer.KafkaConsumerProxy#register
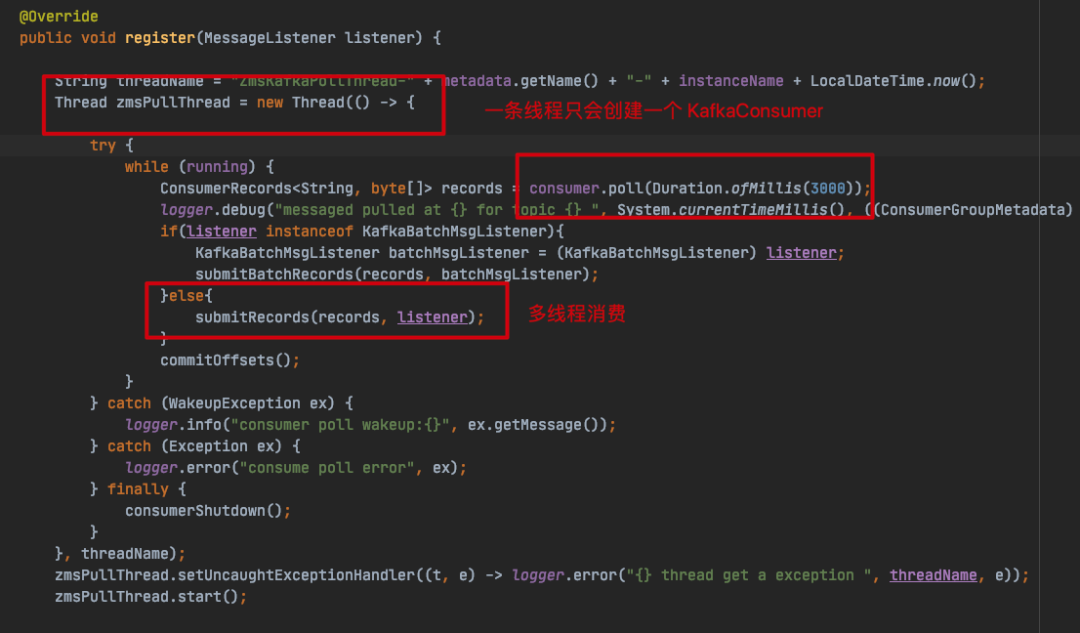
以上,ZMS 每注册一个 KafkaConsumerProxy,都会使用新的线程去处消费 KafkaConsumer,前面也说过了 KafkaConsumer 是非线程安全的。
com.zto.consumer.KafkaConsumerProxy#submitRecords
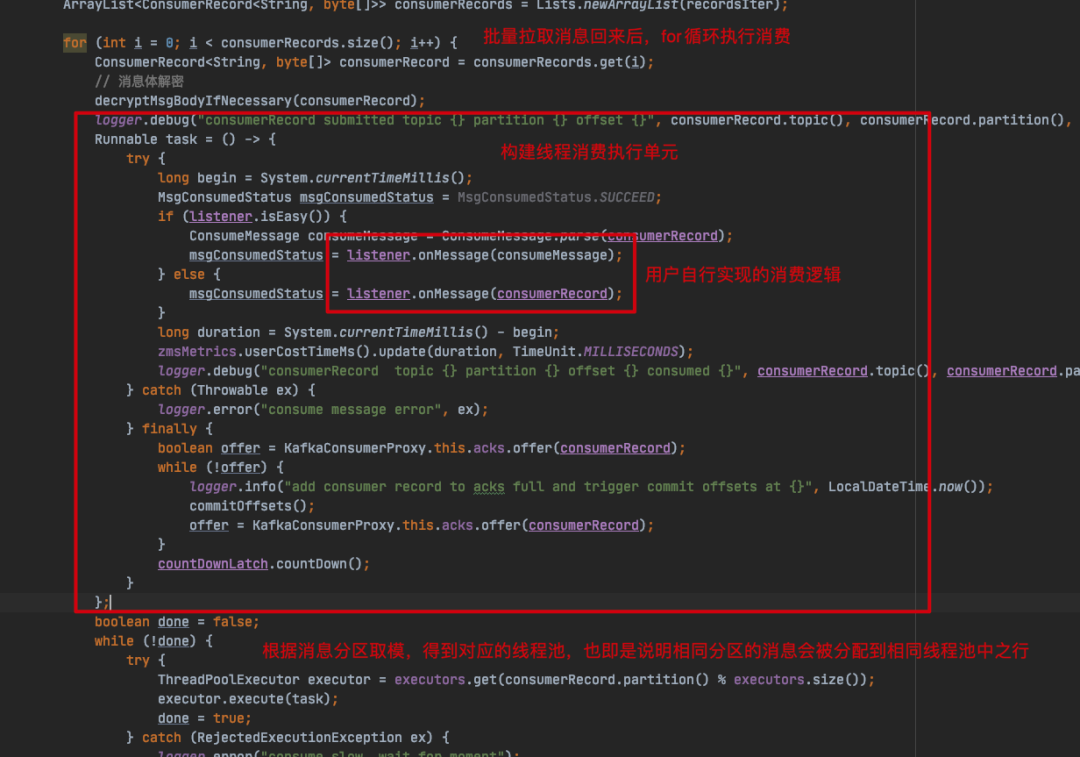
以上是 ZMS 实现多线程消费逻辑的核心,ZMS 会对用消息分区和线程池列表缓存进行取模,从而使得相同分区的消息会被分配到相同线程池中执行,对于顺序消费来说至关重要,前面我也说了,当用户配置了顺序消费时,每个线程池只会分配一个线程,如果相同分区的消息分配到同一个线程池中执行,也就意味着相同分区的消息会串行执行,实现消息消费的顺序性。
以上就是 ZMS Kafka 消费线程模型的简单分析。
最后附上 ZMS 的 GitHub 地址:
https://github.com/ZTO-Express/zms
欢迎大家提出宝贵意见。
本文分享自微信公众号 - 后端进阶(objcoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












