
Mongodb最基础入门教程
如果想了解一下redis的入门教程,可以去看一下我的上一篇博客
Mongodb的安装大家可以参考一下其他博主的博客,这里我就不做介绍了。不过值得注意的是,在Linux版本中如果启动mongodb的时候出现下面这个错误(在windows版本中不会出现下面的问题):
mongod: /usr/lib/libcurl.so.4: version `CURL_OPENSSL_3' not found (required by mongod)原因是因为mongodb启动需要的是libcurl.so.3。在我们安装好libcurl.so.3后,我们可以使用下面的命令打开,其中LD_PRELOAD后面跟随的是库的位置。(/data/db文件夹需要赋予可读写的权限)
LD_PRELOAD=/usr/lib/libcurl.so.3 mongod --dbpath /data/dblll简介
Mongodb是一种非关系性数据库(nosql),关于nosql的介绍可以去看一看菜鸟教程
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
下面是Sql与mongodb的术语对比
| SQL | Mongodb |
|---|---|
| 表(Talbe) | 集合(Collection) |
| 行(Row) | 文档(Document) |
| 列(Col) | 字段(Field) |
| 主键(Primary Key) | 对象ID(ObjectId) |
| 索引(Index) | 索引(Index) |
| 嵌套表(Embeded Table) | 嵌入式文档(Embeded Document) |
| 数组(Array) | 数组(Array) |
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。在Mongodb中,对于插入的格式并没有要求,字段类型可以随意变动。例如,在我创建一个集合后,我们可以在这个集合加入下面的数据:
{
"name":"this is a name",
"age":12
}同样我们也可以在这个数据库插入这样的数据。
{
"name":8888,
"address":"changsha"
}当插入这两个数据后,使用Robo3T数据库可视化工具显示如下:

通过这个我们知道,在向mongodb的同一个表中插入数据的时候,插入的数据字段类型可以不一样,即使是相同的字段数据类型也可以不一样。
不过即使mongodb可以这样做,也能够这样做,但是却不是我们应该这样做的理由,我们在设计数据库的时候,应尽量提前考虑好数据库应有的字段,同时每一个字段应该使用同一种数据类型,这样我们才能紧紧的将程序o把握在我们的手里面。
插入数据
首先我们先创建一个名字为test_data_1的集合。
插入一条文档
db.getCollection('test_data_1').insertOne(
{
"name":8888,
"address":"changsha"
}
)当然,将这一条语句写成一行也是没有问题的。其中,Key(也就是上面的name和address)是可以不带引号的,同时对于字符串也可以使用单引号,不过为了统一,在后面统一使用双引号。
下面是执行这一条数据返回的结果
{
"acknowledged" : true,
"insertedId" : ObjectId("5d5f9e5c0336f9e82b3f9d74")
}其中acknowledged代表数据是否被承认。其中,每一条数据被插入的时候都会返回一个字段“_id”,也就是ObjectId,它是由时间、机器码、进程pid和自增计数器构成的。“_id”始终递增,并绝对不重复。
插入多个文档
mongodb也同时支持一次插入多个文档
db.getCollection('test_data_1').insertMany([
{
"name":"名字1",
},
{
"name":"名字2",
},
{
"address":"湖南"
},
]
)这里我们又可以想一想,我们是否可以使用insertOne实现insertMany的功能?肯定是可以的,但是会造成什么影响呢?我们可以从网络带宽,磁盘IO,机器性能,以及稳定性来考虑。
在插入相同大小的数据时,使用insertMany的性能要明显好于insertOne,因为insertOne会频繁的调用去插入数据,而insertMany却只会调用一次。如果mangodb数据库与调用者不在同一台机器上,那么性能相差便会更大,因为数据在网络传输的过程中会添加其他的报文。那么插入数据的时候是不是应该将数据全部一次插入呢?也不是!!试想一下,如果插入的数据过多,将磁盘的IO占满了,那么必会对其他程序造成影响。并且,如果在快要插入完所有数据的时候,服务器断电了,那么……所以说,应该合理的选择一次性插入数据库的数量。
查询数据
查询所有数据
db.getCollection('test_data_1').find({})其中{}里面包含的是查询条件,因为是查询所有的数据,所以直接为空就行了,或者省略{}也行。
查询特定的数据
db.getCollection('test_data_1').find({"字段1":"固定值1","字段2":"固定值2"})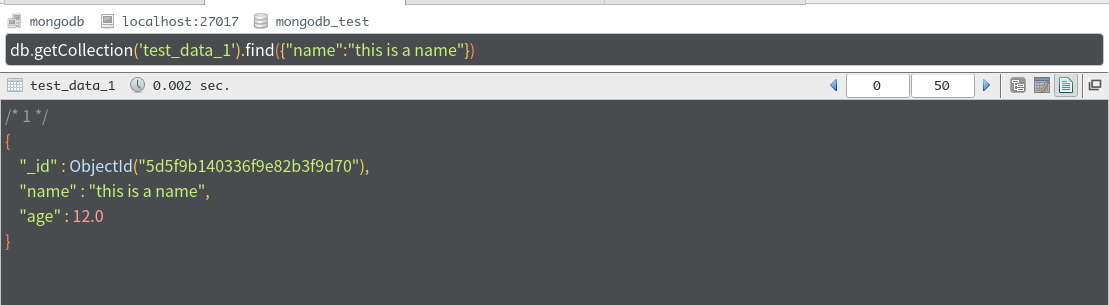
查询范围值数据
下面是查询i范围值的语法,至于操作符,我们后面再说。
db.getCollection('test_data_1').find(
{
"字段1":{"操作符1":边界1,"操作符2":边界2},
"字段2":{"操作符1":边界1,"操作符2":边界2}
}
)查询范围值的数据简单,举一个示例:
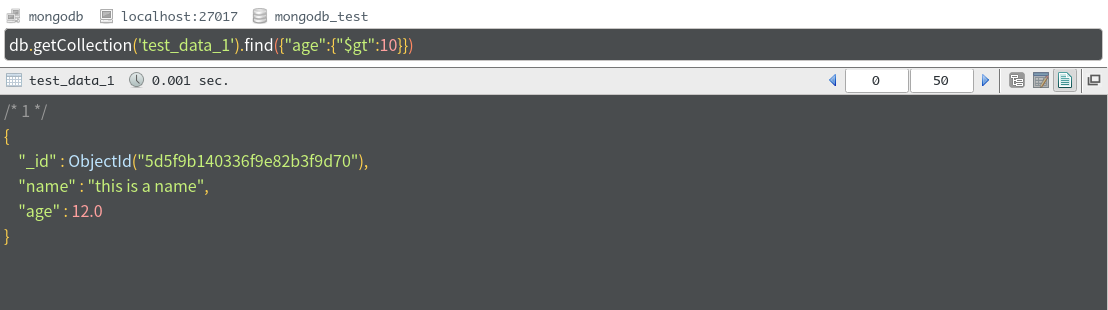
和前面查询特定的数据的方法一样,只不过固定值变成了范围({"$gt":10}代表大于10)。
下面是范围操作符及其意义:
| 操作符 | 意义 |
|---|---|
| $gt | 大于(great than) |
| $gte | 大于等于(great than equal) |
| $lt | 小于(less than) |
| $lte | 小于等于(less than equal) |
| $ne | 不等于(not equal) |
限定返回字段
在前面的几张图片中,我们可以看到,使用find操作的时候,返回了所有的字段,那么如果我们并不想要某一些字段的时候,我们应该怎么做呢?
db.getCollection('test_data_1').find(用于过滤的条件,用于限定的条件)下面便是两个例子:
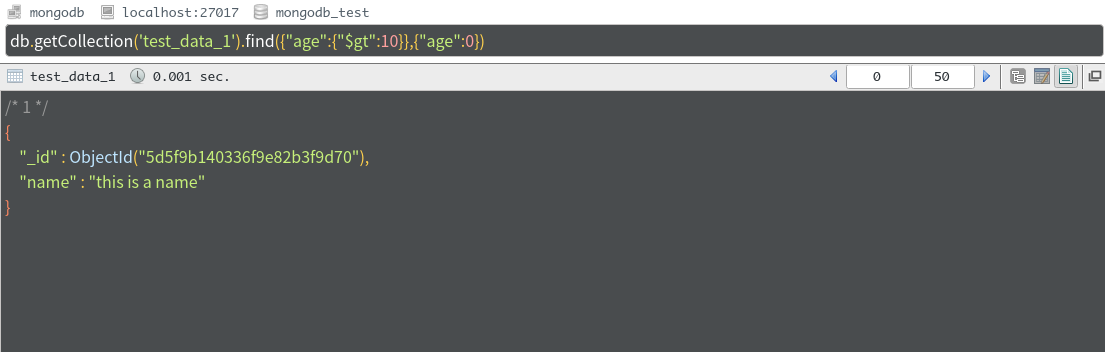
去除age
只返回age
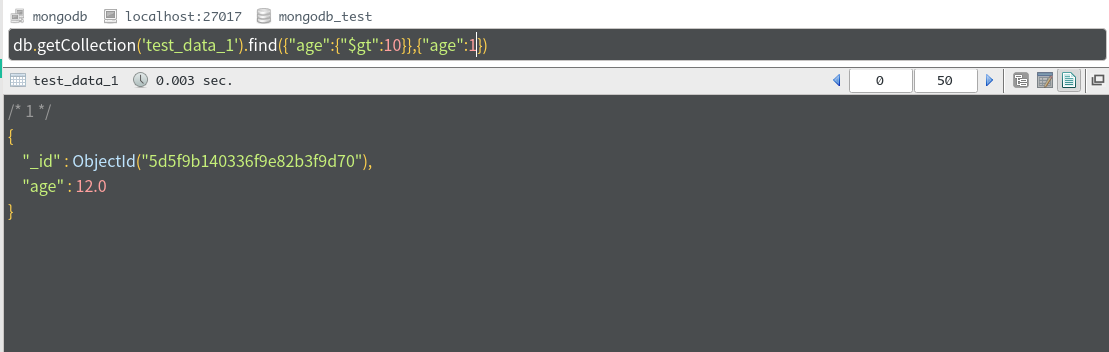
大家会发现,在后面的用于限定的条件中,如果age为1,则返回了age和**_id**,如果age为0,则返回了**_id和name**。在不考虑_id的情况下,我们可以理解:
如果某一个字段被限定为0,则代表该字段不返回(也就是默认其它字段为1),所以其他未被限定的字段则一定会被返回
如果某一个字段被限定为1,则代表该字段返回(也就是默认其它字段为0),所以其他未被限定的字段则不会被返回
_id比较特殊,无论怎样,都要默认返回,当是如果我们真的不需要,那么必须就要把"_id"设置为0。
修饰返回结果
得到数据的条数
db.getCollection('test_data_1').find({}).count()限定返回结果数量
db.getCollection('test_data_1').find({}).limit(限制返回的数量)对结果进行排序
db.getCollection('test_data_1').find({}).sort({"字段名":-1或者1})其中-1为逆序,1为正序。
修改数据
修改数据的前一部分是需要找到数据,然后才能进行修改。同样,在mongodb中,有两种方法修改数据(实际上有很多种)
- updateOne:只更新第一条符合条件的数据
- updateMany:更新所有符合条件的数据
下面介绍updateMany的更新数据
db.getCollection('test_data_1').updateMany(
// 下面是查询条件
{
"字段名1":"查找条件1","字段名2":"查找条件2"
},
// 进行修改
{
"$set":{"字段名":"新的数据","字段名":"新的数据"}
}
)其中,如果在进行在_进行修改_的步骤中,如果字段名以前不存在则会进行增添。
当然,更新数据的内容不可能就这么一点点,但是因为这仅仅是一个基础入门教程,其他的就拜拜吧!想了解更多可以去看看其他的教程。
删除数据
删除数据也有两种操作,deleteOne和deleteMany。和修改数据的情况差不多,一个是删除第一条满足条件的,一个是删除所有满足条件的。
还是以deleteMany来说:
db.getCollection('test_data_1').deleteMany(
// 删除的条件
{
"字段名1":"值","字段名2":"值2"
}
)说完简单的mongodb的操作(增删改查)我们现在可以来说一说稍微复杂一点点的操作了。
数据去重
在mongodb中进行数据去重是一个很简单的操作。使用distinct即可。它可以接收两个参数,第一个参数为需要被去重的字段名,第二个参数是进行去重的条件(去重条件也就是进行查询操作的第一个参数,可以省略)。
db.getCollection('test_data_1').distinct(去重的字段名,去重的条件)下面举个例子:
db.getCollection('test_data_1').distinct("name",{"age":{"$ne":10}})这个的含义就是,在age不等于10的条件下对name字段进行去重!那么返回的数据是什么呢?是一个数组,里面是去重后的表中name字段的非重复的数据。
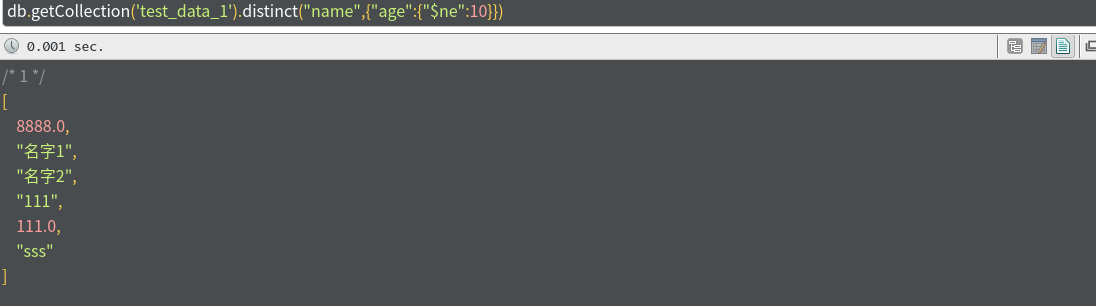
注意:这个去重是对返回值去重,而不是对数据库里面数据去重,也就是说,执行了这个操作,数据库没有发生任何改变。
在这一章只介绍了mongodb的最最基础的一些东西,本来是想介绍一下Mongodb的其他操作,但是发现其他的操作稍微要复杂一点,所以准备在下一章写。这一章的介绍就介绍到这里,下一篇博客我将介绍一下Mongodb的其他操作。
参考
参考书籍:《左手Mongodb,右手Redis》
本文转自 https://www.cnblogs.com/xiaohuiduan/p/11403891.html,如有侵权,请联系删除。











