

往期推荐:
本篇终于到了Flink的核心内容:时间与水印。最初接触这个概念是在Spark Structured Streaming中,一直无法理解水印的作用。直到使用了一段时间Flink之后,对实时流处理有了一定的理解,才想清楚其中的缘由。接下来就来介绍下Flink中的时间和水印,以及基于时间特性支持的窗口处理。
1 时间和水印
1.1 介绍
Flink支持不同的时间类型:
事件时间:事件发生的时间,是设备生产或存储事件的时间,一般都直接存储在事件上,比如Mysql Binglog中的修改时间;或者用户访问日志的访问时间等。
摄入时间:事件进入Flink的时间,这个时间不常用。
处理时间:某个特殊的算子处理事件的时间,当不在意事件的顺序时,为了保证高吞吐低延迟,会采用这种时间。
比如想要计算给定某天的第一个小时的股票价格趋势,就需要使用事件时间。如果选择处理时间进行计算,那么将会按照当前Flink应用处理的时间进行统计,就可能会造成数据一致性问题,历史数据的分析也很难复现。还有个典型的场景是流式处理往往是7*24小时不间断的运行,加入使用处理时间,当中间停机进行代码更新或者BUG处理时,再次启动,中间未处理的数据会堆积当重启时间一次性处理,这样对统计结果就造成大大的干扰。
1.2 使用EventTime
Flink默认使用的是处理时间,可以通过下面的方法修改成事件时间:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
如果需要使用事件时间,还需要提供时间抽取器和水印生成器,这样Flink才可以追踪到事件时间的处理进度。
1.3 水印
通过下面的例子,可以了解为什么需要水印,水印是怎么工作的。在这个例子中,每个事件都带有一个时间标识,下面的数字就是事件上的时间,很明显它们是乱序到达的。第一个到达的是4,然后是2:
23 19 22 24 21 14 17 13 12 15 9 11 7 2 4(第一个事件)
加入现在希望对流进行排序,那么每个事件到达的时候,就需要产生一个流,按照时间戳排好序输出每个到达的事件。
上帝视角:第一个到达的事件是4,但是不能立刻就把它当做第一个元素放入排序流中,因为现在事件是乱序的,无法确定前面的事件是否已经到达。当然现在你已经看到完整的事件顺序,当然会知道只要再等待一个事件,4之前的事件就都处理完了(这就是上帝视角),但在现实中我们是一条条接收的数据,无法知道4后面出现的是2。
缓存和延迟:如果使用缓存,那么很有可能会永远停止等待。第一个事件是4,第二个事件是2,我们是不是只需要等待一个事件就能保证事件的完整?可能是,也可能不是,比如现在事件就永远等待不到1。
排序策略:对于任何给定的时间事件停止等待之前的数据,直接进行排序。这就是水印的作用:用来定义何时停止等待更早的数据。Flink中的事件时间处理依赖于水印生成器,每当元素进入到Flink,会根据其事件时间,生成一个新的时间戳,即水印。对于t时间的水印,意味着Flink不会再接收t之前的数据,那么t之前的数据就可以进行排序产出顺序流了。在上面的例子中,当水印的时间戳到达2时,就会把2事件输出。
水印策略:每当事件延迟到达时,这些延迟都不是固定的,一种简单的方式是按照最大的延迟事件来判断。对于大部分的应用,这种固定水印都可以工作的比较好。
1.4 延迟和完整性
在批处理中,用户可以一次性看到全部的数据,因此可以很容易的知道事件的顺序。在流处理中总需要等待一段时间,确定事件完整后才能产生结果。可以很激进的配置一个较短的水印延迟时间,这样虽然输入结果不完整(有的时间延迟还未到达就已经开始计算),但是速度会很快。或者设置较长的延迟,数据会相对完整,但是会有一定的延迟。也可以采用混合的策略,刚开始延迟小一点,当处理了部分数据后,延迟增加。
1.5 延时
延时通过水印来定义,Watermark(t)代表了t时间的事件是完整的,即小于t的事件都可以开始处理了。
1.6 使用水印
为了支撑事件时间机制的处理,Flink需要知道每个事件的时间,然后为其产生一个水印。
DataStream<Event> stream = ...WatermarkStrategy<Event> strategy = WatermarkStrategy .<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20)) // 选择时间字段 .withTimestampAssigner((event, timestamp) -> event.timestamp);DataStream<Event> withTimestampsAndWatermarks = // 定义水印生成的策略 stream.assignTimestampsAndWatermarks(strategy);
2 窗口
Flink拥有丰富的窗口语义,接下来将会了解到:
如何在无限数据流上使用窗口聚合数据
Flink都支持什么类型的窗口
如何实现一个窗口聚合
2.1 介绍
当进行流处理时很自然的想针对一部分数据聚合分析,比如想要统计每分钟有多少浏览、每周每个用户有多少次会话、每分钟每个传感器的最大温度等。Flink的窗口分析依赖于两个抽象概念:窗口分配器Assigner(用来指定事件属于哪个窗口,在必要的时候新建窗口),窗口函数Function(应用于窗口内的数据)。Flink的窗口也有触发器Trigger的概念,它决定了何时调用窗口函数进行处理;Evictor用于剔除窗口中不需要计算的数据。可以像下面这样创建窗口:
stream. .keyBy(<key selector>) .window(<window assigner>) .reduce|aggregate|process(<window function>)
也可以在非key数据流上使用窗口,但是一定要小心,因为处理过程将不会并行执行:
stream. .windowAll(<window assigner>) .reduce|aggregate|process(<window function>)
2.2 窗口分配器
Flink有几种内置的窗口分配器:
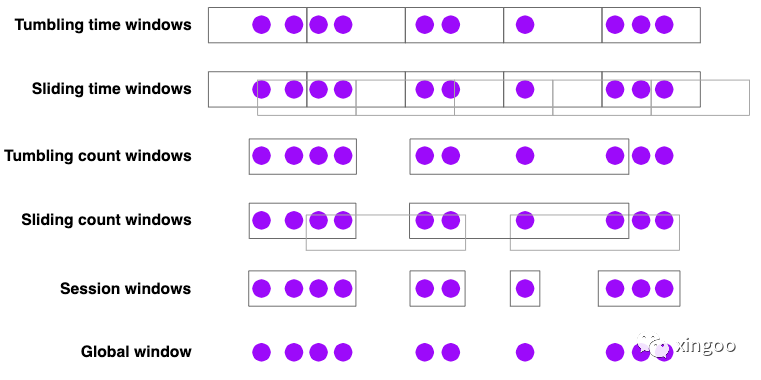
按照窗口聚合的种类可以大致分为:
滚动窗口:比如统计每分钟的浏览量,
TumblingEventTimeWindows.of(Time.minutes(1))滑动窗口:比如每10秒钟统计一次一分钟内的浏览量,
SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10))会话窗口:统计会话内的浏览量,会话的定义是同一个用户两次访问不超过30分钟,
EventTimeSessionWindows.withGap(Time.minutes(30))
窗口的时间可以通过下面的几种时间单位来定义:
毫秒,
Time.milliseconds(n)秒,
Time.seconds(n)分钟,
Time.minutes(n)小时,
Time.hours(n)天,
Time.days(n)
基于时间的窗口分配器支持事件时间和处理时间,这两种类型的时间处理的吞吐量会有差别。使用处理时间优点是延迟很低,但是也存在几个缺点:无法正确的处理历史数据;无法处理乱序数据;结果非幂等。当使用基于数量的窗口,如果数量不够,可能永远不会触发窗口操作。没有选项支持超时处理或部分窗口的处理,当然你可以通过自定义窗口的方式来实现。全局窗口分配器会在一个窗口内,统一分配每个事件。如果需要自定义窗口,一般会基于它来做。不过推荐直接使用ProcessFunction。
2.3 窗口函数
有三种选择来处理窗口中的内容:
当做批处理,使用
ProcessWindowFunction,基于Iterable处理窗口内容增量的使用
ReduceFunction和AggregateFunction依次处理窗口的每个数据上面两者结合,使用
ReduceFunction和AggregateFunction进行预聚合,然后使用ProcessFunction进行批量处理。
下面给出了方法1和方法3的例子,需求为在每分钟内寻找到每个传感器的值,产生<key,>的结果流。
2.3.1 ProcessWindowFunction的例子
DataStream<SensorReading> input = ...input .keyBy(x -> x.key) .window(TumblingEventTimeWindows.of(Time.minutes(1))) .process(new MyWastefulMax());public static class MyWastefulMax extends ProcessWindowFunction< SensorReading, // input type Tuple3<String, Long, Integer>, // output type String, // key type TimeWindow> { // window type @Override public void process( String key, Context context, Iterable<SensorReading> events, Collector<Tuple3<String, Long, Integer>> out) {
int max = 0; for (SensorReading event : events) {
max = Math.max(event.value, max); } out.collect(Tuple3.of(key, context.window().getEnd(), max)); }}
有一些内容需要了解:
所有窗口分配的时间都在Flink中按照key缓存起来,直到窗口触发,因此代价很昂贵。
ProcessWindowFunction中传入了Context对象,内部包含了对应的窗口信息,接口类似:
public abstract class Context implements java.io.Serializable {
public abstract W window(); public abstract long currentProcessingTime(); public abstract long currentWatermark(); public abstract KeyedStateStore windowState(); public abstract KeyedStateStore globalState();}
其中windowState和globalState会为每个key、每个窗口或者全局存储信息,当需要记录窗口的某些信息的时候会很有用。
2.3.2 Incremental Aggregation例子
DataStream<SensorReading> input = ...input .keyBy(x -> x.key) .window(TumblingEventTimeWindows.of(Time.minutes(1))) .reduce(new MyReducingMax(), new MyWindowFunction());private static class MyReducingMax implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r1 : r2; }}private static class MyWindowFunction extends ProcessWindowFunction< SensorReading, Tuple3<String, Long, SensorReading>, String, TimeWindow> {
@Override public void process( String key, Context context, Iterable<SensorReading> maxReading, Collector<Tuple3<String, Long, SensorReading>> out) {
SensorReading max = maxReading.iterator().next(); out.collect(Tuple3.of(key, context.window().getEnd(), max)); }}
注意iterable只会执行一次,即只有MyReducingMax输出的值才会传入这里。
2.4 延迟事件
默认当使用基于事件时间窗口时,延迟事件会直接丢弃。有两种方法可以处理这个问题:你可以把需要丢弃的事件重新搜集起来输出到另一个流中,也叫侧输出;或者配置水印的延迟时间。
OutputTag<Event> lateTag = new OutputTag<Event>("late"){};SingleOutputStreamOperator<Event> result = stream. .keyBy(...) .window(...) .sideOutputLateData(lateTag) .process(...);DataStream<Event> lateStream = result.getSideOutput(lateTag);
通过指定允许延迟的间隔时间,当在允许的延迟范围内,仍然可以分配到对应的窗口(窗口对应的状态信息将会保留一段时间)。但是会导致对应窗口重新计算(也叫做延迟响应late firing)默认允许的延迟是0,也就是说一旦事件在水印之后就会被丢弃掉。
stream. .keyBy(...) .window(...) .allowedLateness(Time.seconds(10)) .process(...);
当配置延迟后,只有那些在允许的延迟之外的数据会被丢弃或者使用侧输出搜集起来。
3 注意
Flink的窗口处理可能跟你想的不太一样,基于在flink用户邮件中常问的问题,整理如下
3.1 滑动窗口造成数据拷贝
滑动窗口会造成大量的窗口对象,并且会拷贝每个对象到对应的窗口中。比如,你的滑动窗口为每15分钟统计24小时的窗口长度,那么每个时间将会复制到4*24=96个窗口中。
3.2 时间窗口会对齐到系统时间
如果使用1个小时的窗口,那么当应用在12:05启动时,并不是说第一个窗口的时间范围是到1:05,事实上第一个窗口的时间是12:05到01:00,只有55分钟而已。注意,滚动窗口和滑动窗口都支持偏移值的参数配置。
3.3 窗口后面可以接窗口
比如:
stream .keyBy(t -> t.key) .timeWindow(<time specification>) .reduce(<reduce function>) .timeWindowAll(<same time specification>) .reduce(<same reduce function>)
这样的代码能够工作主要是因为第一个窗口输出的内容系统会自动添加一个窗口结束的时间,后面的处理可以基于这个时间再次进行窗口操作,但是需要窗口的配置统一或者整数倍。
3.4 空窗口没有输出
只有对应的事件到达时,才会创建对应的窗口。因此如果没有对应的事件,窗口就不会创建,因此也不会有任何输出。
3.5 延迟数据造成延迟合并
对于会话窗口,实际上会为每个事件在一开始分配一个新的窗口,当新的事件到达时,会根据时间间隔合并窗口。因此如果事件延迟到达,很有可能会造成窗口的延迟合并。











