
1. 为啥需要 defaultLoadFactor
现在主流的 HashMap,一般的实现思路都是开放地址法+链地址法的方式来实现。 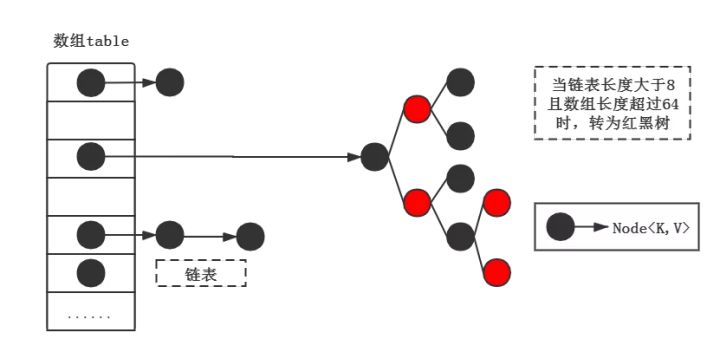 即数组 + 链表的实现方式,通过计算哈希值,找到数组对应的位置,如果已存在元素,就加到这个位置的链表上。在 Java 8 之后,链表过长还会转化为红黑树。红黑树相较于原来的链表,多占用了一倍的空间,但是查询速度快乐一个数量级,属于空间换时间。 同时,链表转换红黑树也是一个耗时的操作。并且,一个效率高的哈希表,这个链表不应该过长。
即数组 + 链表的实现方式,通过计算哈希值,找到数组对应的位置,如果已存在元素,就加到这个位置的链表上。在 Java 8 之后,链表过长还会转化为红黑树。红黑树相较于原来的链表,多占用了一倍的空间,但是查询速度快乐一个数量级,属于空间换时间。 同时,链表转换红黑树也是一个耗时的操作。并且,一个效率高的哈希表,这个链表不应该过长。
所以,如果数组的很多元素上面已经有值了,那么就需要将这个数组扩充下,重建哈希表,也就是 rehash,因此这个 rehash 相当耗时。那么什么时候扩容呢?
**当数组填满的时候?**那么在数组快要填满的时候,会发生很多需要将元素加到对应位置的链表上的情况,并且增加产生红黑树的概率。这显然不可取。
这个 defaultLoadFactor 就是一个比较合适的,哈希表需要扩容的时候的 数组中有占用元素的比例。
2. 这个比例如何计算?
其实,这个并没有一个统一的结论,因为不同场景下,肯定考虑的方面不同,这个数字最好能最通用。但是,目前不同语言的 defaultLoadFactor 并不一样,比如 Java 是 0.75,Go 中是 0.65,Dart 中是0.8,python 中是0.762.
首先,这个基于一个假设,那么就是当一个事件发生的概率大于 0.5,那么这件事就是很可能发生的。
然后,假设当前有 s 个桶,那么每次放入一个元素进入某一个桶的概率就是:
\frac{1}{s}
放入了第 n 个元素,那么,某一个桶元素个数为e的概率,根据二项式分布就是:
\frac{n!}{e!(n-e)!}(\frac{1}{s})^{e}(1-\frac{1}{s})^{n-e}
将e=0代入,得出:
\frac{n!}{0!(n-0)!}(\frac{1}{s})^{0}(1-\frac{1}{s})^{n-0} \Rightarrow (1-\frac{1}{s})^n
让这个概率 大于 0.5 也就是 1/2
那么解这个不等式,得到:
\frac{log(2)}{log(\frac{s}{s - 1})} > n
如果让 s 趋近于无穷大,那么 n/s 就无限接近于 log(2). 也就是放入的元素数量是所有桶的数量的 log(2) ~ 0.693
3. 为何 Java 8 中的红黑树是链表大于8的时候转换
这个是在 defaultLoadFactor = 0.75 的基础上,根据泊松分布概率计算得出的结论。我们要保证,这个界限,不能太大,否则遇到链表确实比较长的时候,查询效率低。更不能太小,否则转换的性能损耗还有空间占用大。所以,我们期望,每个桶上面元素个数超过 k 的概率尽量小,并且这个 k 不算很大,就可以了。
首先,对于任意一个 HashMap 的数组上面的元素,存入一个数据,要么放入要么不放入,概率分别是 50%,期望 E 是 0.5. 泊松分布是二项分布的极限形式,就是有且只有两个相互对立的结果的概率分布,对于这个位置上面链表元素个数为 k ,其概率公式是:
\frac{E^ke^{-E}}{k!}
期望 E = 0.5,代入,对于 k=1 到 8 的情况,概率分别是:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
k=8 时,概率足够小,所以采用 8 作为变成红黑树的界限。









