

今天就来带大家写一个简单而又完整的爬虫,我们来抓取整站的图片的,并且保存到电脑上!

准备工作
工具:Python3.6、pycharm
库:requests、re、time、random、os
目标网站:妹子图(具体url大家自己去代码里看。。。)

在写代码之前
在我们开始写代码之前,要先对网站进行分析,重点有这个几个地方:
1、先判断网页是否静态网页,这个关系我们采用的爬虫手段!
简单的说,网页中的内容,在网页源代码中都可以找到,那么就可以断定,这个网站是静态的了;如果没有找到,就需要去开发者工具中查找,看看是抓包呢还是分析js结构或者其他的方式。
2、看看网页的结构,大致清楚抓取目标数据,需要几层循环,每次循环的方式,以及是否保证没有遗漏!
3、根据网页源代码来决定采用的匹配方式
一般来说,正则表达式是处理字符串最快的方式,但是在爬虫中它的效率并不是很高,因为它需要遍历整个html来匹配相关内容,如果网页源代码比较规整的话,建议采用bs4或者xpath等等解析网页结构的方式比较好!
当然,今天我们是基础向的爬虫,就用正则表达式了,毕竟正则是必须掌握的内容!
那么,具体怎么写爬虫代码呢~?简单的举例给大家说下:
如果是手工操作的话,大概是这个流程
打开主页==>选择一个分类==>选择一个图集==>依次选择图片==>右键保存==>重复以上保存其他图片
那么这个过程放到代码中呢,它的结构大概是这样:
访问主页url==>找到并循环所有分类==>创建分类文件夹==>访问分类url==>找到页码构建循环分类所有页==>循环页面所有图集==>创建图集文件夹==>找到图集内所有图片url==>保存到对应文件夹
好了,思路也有了,那就废话不多说了,我们来写代码吧~!

完整代码和运行效果
在请求中加入了时间模块的暂停功能,不加入的话可能会被网页拒绝访问!
在最后请求图片地址的时候,需要加入UA来告诉服务器你是浏览器而不是脚本,这个是最常用的反爬手段了
#author:云飞
下载一段时间后的效果
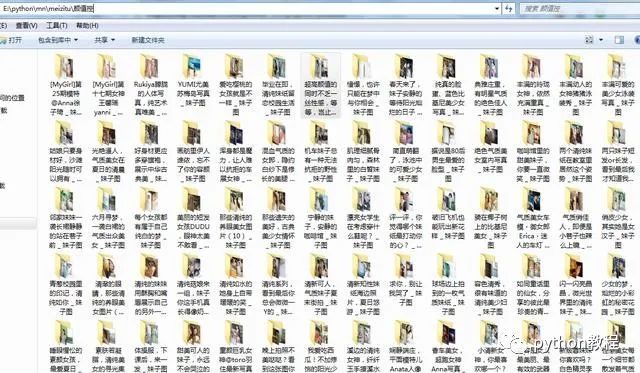
**********---**--****-------------- End **********---**--****--------------
扫下方二维码加老师微信或是搜索老师微信号:XTUOL1988【备注学习Python】领取Python web开发,Python爬虫,Python数据分析,人工智能等学习教程。带你从零基础系统性的学好Python!也可以加老师建的Python技术学习教程qq裙:245345507,二者加一个就可以!

欢迎大家点赞,留言,转发,转载,****感谢大家的相伴与支持
万水千山总是情,点个【在看】行不行
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
/今日留言主题/
随便说一两句吧~~
本文分享自微信公众号 - python教程(pythonjc)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











