
hello,小伙伴们大家好

今天给大家介绍的开源项目是文章爬虫利器
爱收集的小伙伴们的福利哦!
假如你在工作中接到产品小姐姐的需求,需求是获取V2EX,知乎,简书,知否(SegmentFault),掘金,CSDN博客,微信公众号文章,cnblogs等中文网站中输出正文内容、标题、作者、发布时间、正文中的图片地址和正文所在的标签源代码 转化为Markdown,你会怎么做,假如你 code 功力还没有经过九九八十一天的修炼,还没有练到元婴期,你脑子里应该想的是我要写这么多规则,可怎么办,要累死人呢!要是有一个通用工具就好了,我要分享的这个github的开源项目:
在线体验地址:在线体验
项目链接:github
一键解析Markdown V2EX,知乎,简书,知否(SegmentFault),掘金,CSDN博客,微信公众号文章,cnblogs的页面->解析为markdown
ToMarkdown
功能描述: 将HTTP页面 解析为Markdown格式
目前支持: 知乎,简书,知否(SegmentFault),掘金,CSDN博客,微信公众号,V2EX 一键解析
体验地址: http://markdown.liangtengyu.com:9999
后端技术栈:
- springboot v2.1.4.RELEASE
- Jsoup
- Remark
前端:
- axios 请求组件
- mavoneditor markdown显示编辑组件
- ant-design-vue
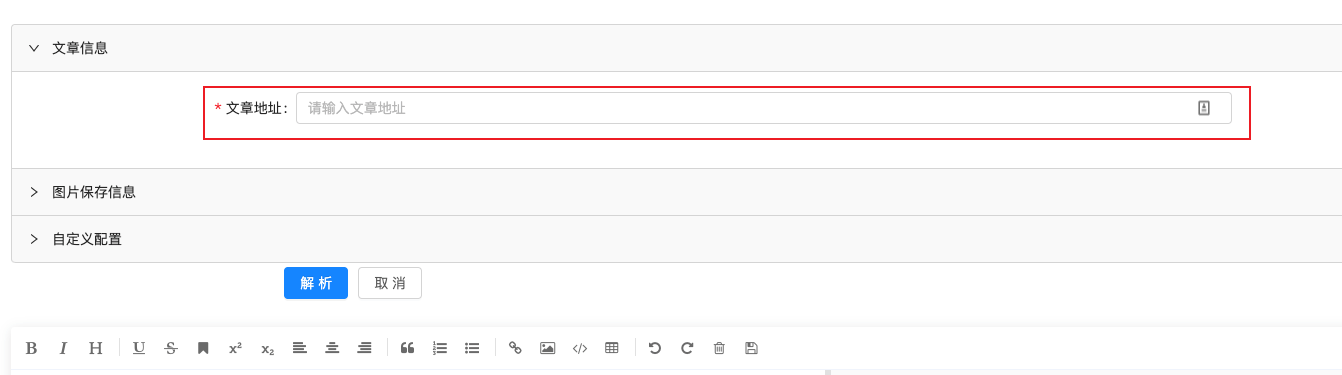
使用方式也特别简单:
打开地址-->输入文章地址-->点击解析-->完成
有兴趣的小伙伴可以尝试应用一下,如果在使用期间遇到问题请在下方留言或私信我!
今天的推荐不知道大家喜欢吗?如果你们喜欢话,请在文章底部留言和点赞,以表示对我的支持,你们的留言,点赞和转发关注是我持续更新的动力哦!
关注公众号:java宝典












