
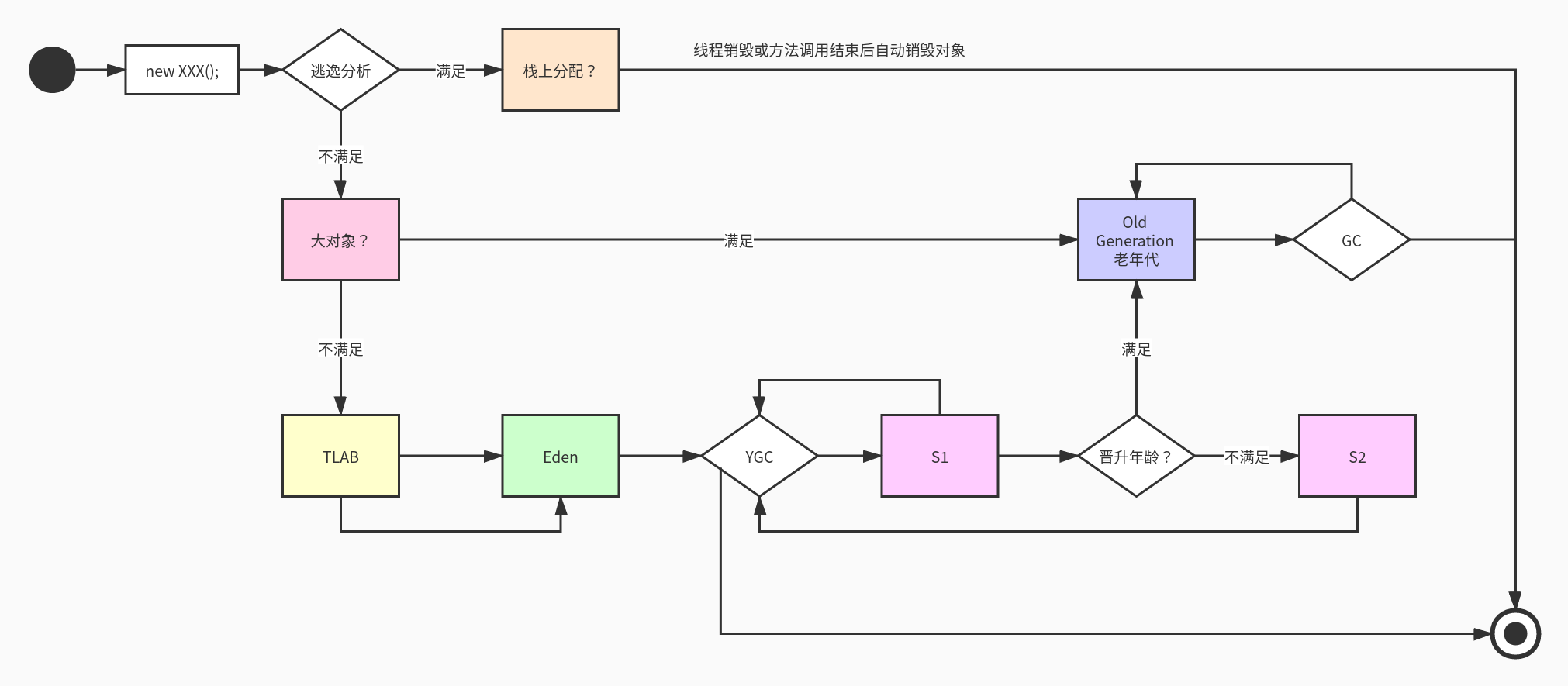
对象分配过程
- 1)依据逃逸分析,判断是否能栈上分配?
- 如果可以,使用标量替换方式,把对象分配到
VM Stack中。如果 线程销毁或方法调用结束后,自动销毁,不需要 GC 回收器 介入。 - 否则,继续下一步。
- 如果可以,使用标量替换方式,把对象分配到
- 2)判断是否大对象?
- 如果是,直接分配到堆上
Old Generation老年代上。如果对象变为垃圾后,由老年代GC 收集器(比如 Parallel Old, CMS, G1)回收。 - 否则,继续下一步。
- 如果是,直接分配到堆上
- 3)判断是否可以在
TLAB中分配?- 如果是,在
TLAB中分配堆上Eden区。 - 否则,在
TLAB外堆上的Eden区分配。
- 如果是,在
栈上分配
本质上是JVM提供的一个优化技术。
- 基本思想:将线程私有的对象打散分配在栈
VM Stack上 - 优点:
- 可以在函数调用结束后自行销毁对象,不需要垃圾回收器的介入,有效避免垃圾回收带来的负面影响
- 栈上分配速度快,提高系统性能
- 局限性:
- 栈空间小,对于大对象无法实现栈上分配
- 技术基础:
逃逸分析、标量替换
什么是逃逸分析?
关于 Java 逃逸分析的定义:
逃逸分析(Escape Analysis)简单来讲就是,Java Hotspot 虚拟机可以分析新创建对象的使用范围,并决定是否在 Java 堆上分配内存的一项技术。
逃逸分析的 JVM 参数如下:
- 开启逃逸分析:
-XX:+DoEscapeAnalysis - 关闭逃逸分析:
-XX:-DoEscapeAnalysis - 显示分析结果:
-XX:+PrintEscapeAnalysis
逃逸分析技术在 Java SE 6u23+ 开始支持,并默认设置为启用状态,可以不用额外加这个参数。
逃逸分析优化
针对上面第三点,当一个对象没有逃逸时,可以得到以下几个虚拟机的优化。
1) 锁消除
我们知道线程同步锁是非常牺牲性能的,当编译器确定当前对象只有当前线程使用,那么就会移除该对象的同步锁。
例如,StringBuffer 和 Vector 都是用 synchronized 修饰线程安全的,但大部分情况下,它们都只是在当前线程中用到,这样编译器就会优化移除掉这些锁操作。
锁消除的 JVM 参数如下:
- 开启锁消除:
-XX:+EliminateLocks - 关闭锁消除:
-XX:-EliminateLocks
锁消除在 JDK8 中都是默认开启的,并且锁消除都要建立在逃逸分析的基础上。
2) 标量替换
首先要明白标量和聚合量,基础类型和对象的引用可以理解为标量,它们不能被进一步分解。而能被进一步分解的量就是聚合量,比如:对象。
对象是聚合量,它又可以被进一步分解成标量,将其成员变量分解为分散的变量,这就叫做标量替换。
这样,如果一个对象没有发生逃逸,那压根就不用创建它,只会在栈或者寄存器上创建它用到的成员标量,节省了内存空间,也提升了应用程序性能。
标量替换的 JVM 参数如下:
- 开启标量替换:
-XX:+EliminateAllocations - 关闭标量替换:
-XX:-EliminateAllocations - 显示标量替换详情:
-XX:+PrintEliminateAllocations
标量替换同样在 JDK8 中都是默认开启的,并且都要建立在逃逸分析的基础上。
3) 栈上分配
当对象没有发生逃逸时,该对象就可以通过标量替换分解成成员标量分配在栈内存中,和方法的生命周期一致,随着栈帧出栈时销毁,减少了 GC 压力,提高了应用程序性能。
示例代码
import java.time.Instant;
/**
* 栈上分配,依赖于逃逸分析和标量替换
*
* @author Sven Augustus
*/
public class TestTLAB {
// private static User u;
/**
* 一个User对象的大小:markdown 8 + class pointer 4 + int 4 + string (oops) 4 + padding 4 = 24B <br> 如果分配 100_000_000 个,则需要
* 2400_000_000 字节, 约 2.24 GB。
*/
static class User {
private int id;
private String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
}
private static void alloc() {
User u = new User(1, "SvenAugustus");
// u = new User(1, "SvenAugustus");
}
public static void main(String[] args) throws InterruptedException {
long start = Instant.now().toEpochMilli();
for (int i = 0; i < 100_000_000; i++) {
alloc();
}
System.out.println(Instant.now().toEpochMilli() - start);
}
}
上述代码调用了1亿次alloc(),如果是分配到堆上,大概需要 2.2 GB的堆空间,如果堆空间小于该值,必然会触发GC。
使用如下VM参数运行,发现不会触发GC:
-server -Xmx15m -Xms15m -XX:+DoEscapeAnalysis -XX:+PrintGC -XX:-UseTLAB -XX:+EliminateAllocations
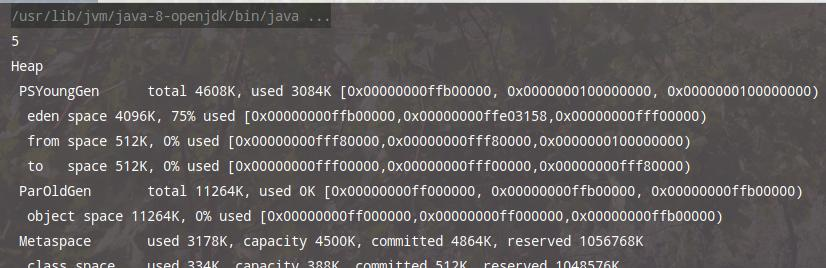
使用如下参数(任意一行)运行,会发现触大量 GC:
//不使用逃逸分析
-server -Xmx15m -Xms15m -XX:+PrintGCDetails -XX:-UseTLAB -XX:-DoEscapeAnalysis -XX:+EliminateAllocations
//不使用标量替换
-server -Xmx15m -Xms15m -XX:+PrintGCDetails -XX:-UseTLAB -XX:+DoEscapeAnalysis -XX:-EliminateAllocations

TLAB 分配
TLAB,全称Thread Local Allocation Buffer, 即:线程本地分配缓存。这是一块线程专用的内存分配区域。
TLAB占用的是eden区的空间。
在TLAB启用的情况下(默认开启),JVM会为每一个线程分配一块TLAB区域。
为什么需要TLAB?
这是为了加速对象的分配。
由于对象一般分配在堆上,而堆是线程共用的,因此可能会有多个线程在堆上申请空间,而每一次的对象分配都必须线程同步,会使分配的效率下降。
考虑到对象分配几乎是Java中最常用的操作,因此JVM使用了TLAB这样的线程专有区域来避免多线程冲突,提高对象分配的效率。
- 局限性: TLAB空间一般不会太大(占用eden区),所以大对象无法进行
TLAB分配,只能直接分配到堆Heap上。
大对象
大对象的 JVM 参数如下:
- 大对象到底多大:
-XX:PreTenureSizeThreshold=n(仅适用于DefNew/ParNew新生代垃圾回收器 ) https://bugs.openjdk.java.net/browse/JDK-8050209 G1回收器的大对象判断,则依据Region的大小(-XX:G1HeapRegionSize)来判断,如果对象大于Region50%以上,就判断为大对象Humongous Object。
by Sven Augustus https://my.oschina.net/langxSpirit
@SvenAugustus(https://www.flysium.xyz/)
更多请关注微信公众号【编程不离宗】,专注于分享服务器开发与编程相关的技术干货:













