
知识体系图:
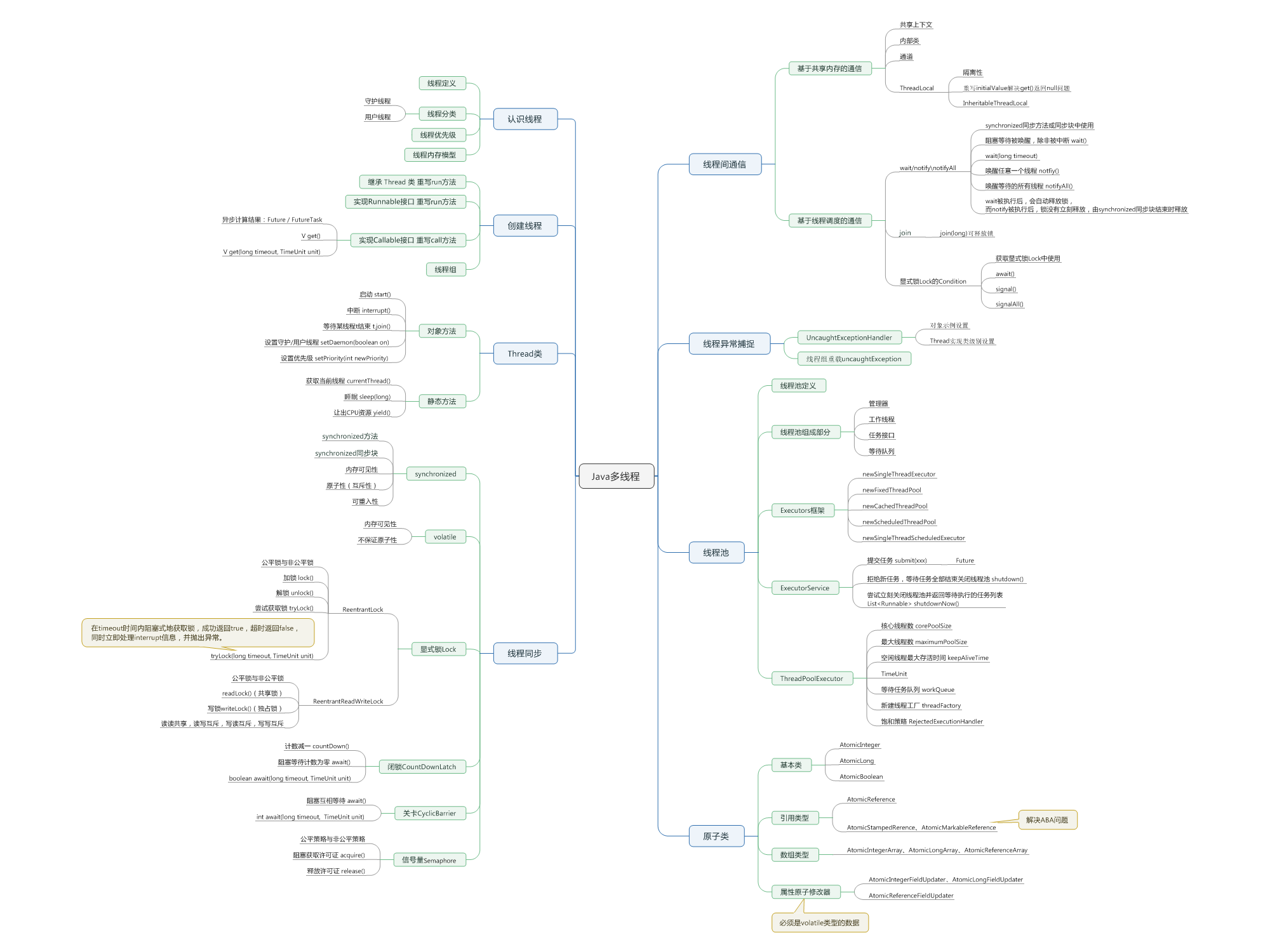
1、线程是什么?
线程是进程中独立运行的子任务。
2、创建线程的方式
方式一:将类声明为 Thread 的子类。该子类应重写 Thread 类的 run 方法
方式二:声明实现 Runnable 接口的类。该类然后实现 run 方法
推荐方式二,因为接口方式比继承方式更灵活,也减少程序间的耦合。
3、获取当前线程信息?
Thread.currentThread()
4、线程的分类
线程分为守护线程、用户线程。线程初始化默认为用户线程。
setDaemon(true) 将该线程标记为守护线程或用户线程。
特性:设置守护线程,会作为进程的守护者,如果进程内没有其他非守护线程,那么守护线程也会被销毁,即使可能线程内没有运行结束。
5、线程间的关系?
某线程a 中启动另外一个线程 t,那么我们称 线程 t是 线程a 的一个子线程,而 线程a 是 线程t 的 父线程。
最典型的就是我们在main方法中 启动 一个 线程去执行。其中main方法隐含的main线程为父线程。
6、线程API一览:如何启动、停止、暂停、恢复线程?
(1)start() 使线程处于就绪状态,Java虚拟机会调用该线程的run方法;
(2)stop() 停止线程,已过时,存在不安全性:
一是可能请理性的工作得不得完成;
二是可能对锁定的对象进行“解锁”,导致数据不同步不一致的情况。
推荐 使用 interrupt() +抛异常 中断线程。
(3)suspend() 暂停线程,已过时。
resume() 恢复线程,已过时。
suspend 与resume 不建议使用,存在缺陷:
一是可能独占同步对象;
二是导致数据不一致。
(4)yield() 放弃当前线程的CPU资源。放弃时间不确认,也有可能刚刚放弃又获得CPU资源。
(5)t.join() 等待该线程t 销毁终止。
7、synchronized关键字用法
一 原子性(互斥性):实现多线程的同步机制,使得锁内代码的运行必需先获得对应的锁,运行完后自动释放对应的锁。
二 内存可见性:在同一锁情况下,synchronized锁内代码保证变量的可见性。
三 可重入性:当一个线程获取一个对象的锁,再次请求该对象的锁时是可以再次获取该对象的锁的。
如果在synchronized锁内发生异常,锁会被释放。
总结:
(1)synchronized方法 与 synchronized(this) 代码块 锁定的都是当前对象,不同的只是同步代码的范围
(2)synchronized (非this对象x) 将对象x本身作为“对象监视器”:
a、多个线程同时执行 synchronized(x) 代码块,呈现同步效果。
b、当其他线程同时执行对象x里面的 synchronized方法时,呈现同步效果。
c、当其他线程同时执行对象x里面的 synchronized(this)方法时,呈现同步效果。
(3)静态synchronized方法 与 synchronized(calss)代码块 锁定的都是Class锁。Class 锁与 对象锁 不是同一个锁,两者同时使用情况可能呈异步效果。
(4)尽量不使用 synchronized(string),是因为string的实际锁为string的常量池对象,多个值相同的string对象可能持有同一个锁。
8、volatile关键字用法
一 内存可见性:保证变量的可见性,线程在每次使用变量的时候,都会读取变量修改后的最的值。
二 不保证原子性。
9、线程间的通信方式
线程间通信的方式主要为共享内存、线程同步。
线程同步除了synchronized互斥同步外,也可以使用wait/notify实现等待、通知的机制。
(1)wait/notify属于Object类的方法,但wait和notify方法调用,必须获取对象的对象级别锁,即synchronized同步方法或同步块中使用。
(2)wait()方法:在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,或者其他某个线程中断当前线程,导致当前线程一直阻塞等待。等同wait(0)方法。
wait(long timeout) 在其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量前,导致当前线程等待。 单位为毫秒。
void wait(long timeout, int nanos) 与 wait(long timeout) 不同的是增加了额外的纳秒级别,更精细的等待时间控制。
(3)notfiy方法:唤醒在此对象监视器上等待的单个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个 wait 方法,在对象的监视器上等待。
(4)notifyAll方法:唤醒在此对象监视器上等待的所有线程。
需要:wait被执行后,会自动释放锁,而notify被执行后,锁没有立刻释放,由synchronized同步块结束时释放。
应用场景:简单的生产、消费问题。
1
2
3
4
5
6
7
8
synchronized (lock) { //获取到对象锁lock
try {
lock.wait(); //等待通信信号, 释放对象锁lock
} catch (InterruptedException e) {
e.printStackTrace();
}
//接到通信信号
}
1
2
3
4
5
synchronized (lock) { //获取到对象锁lock
lock.notify(); //通知并唤醒某个正等待的线程
//其他操作
}
//释放对象锁lock
10、ThreadLocal与InheritableThreadLocal
让每个线程都有自己独立的共享变量,有两种方式:
一 该实例变量封存在线程类内部;如果该实例变量(非static)是引用类型,存在可能逸出的情况。
二 就是使用ThreadLocal在任意地方构建变量,即使是静态的(static)。具有很好的隔离性。
(1)重写initialValue()方法: 初始化ThreadLocal变量,解决get()返回null问题(
(2)InheritableThreadLocal 子线程可以读取父线程的值,但反之不行
11、ReentrantLock的使用
一个简单的示例:
1
2
3
4
5
6
7
8
9
private java.util.concurrent.locks.Lock lock = new ReentrantLock();
public void method() {
try {
lock.lock();
//获取到锁lock,同步块
} finally {
lock.unlock(); //释放锁lock
}
}
ReentrantLock 比 synchronized 功能更强大,主要体现:
(1)ReentrantLock 具有公平策略的选择。
(2)ReentrantLock 可以在获取锁的时候,可有条件性地获取,可以设置等待时间,很有效地避免死锁。
如 tryLock() 和 tryLock(long timeout, TimeUnit unit)
(3)ReentrantLock 可以获取锁的各种信息,用于监控锁的各种状态。
(4)ReentrantLock 可以灵活实现多路通知,即Condition的运用。
————————————————————————————–
一、公平锁与非公平锁
ReentrantLock 默认是非公平锁,允许线程“抢占插队”获取锁。公平锁则是线程依照请求的顺序获取锁,近似FIFO的策略方式。
二、锁的使用:
(1)lock() 阻塞式地获取锁,只有在获取到锁后才处理interrupt信息
(2)lockInterruptibly() 阻塞式地获取锁,立即处理interrupt信息,并抛出异常
(3)tryLock() 尝试获取锁,不管成功失败,都立即返回true、false,注意的是即使已将此锁设置为使用公平排序策略,tryLock()仍然可以打开公平性去插队抢占。如果希望遵守此锁的公平设置,则使用 tryLock(0, TimeUnit.SECONDS),它几乎是等效的(也检测中断)。
(4)tryLock(long timeout, TimeUnit unit)在timeout时间内阻塞式地获取锁,成功返回true,超时返回false,同时立即处理interrupt信息,并抛出异常。
如果想使用一个允许闯入公平锁的定时 tryLock,那么可以将定时形式和不定时形式组合在一起:
if (lock.tryLock() || lock.tryLock(timeout, unit) ) { … }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
private java.util.concurrent.locks.ReentrantLock lock = new ReentrantLock();
public void testMethod() {
try {
if (lock.tryLock( 1 , TimeUnit.SECONDS)) {
//获取到锁lock,同步块
} else {
//没有获取到锁lock
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (lock.isHeldByCurrentThread()) //如果当前线程持有锁lock,则释放锁lock
lock.unlock();
}
}
}
三、条件Condition的使用
条件Condition可以由锁lock来创建,实现多路通知的机制。
具有await、signal、signalAll的方法,与wait/notify类似,需要在获取锁后方能调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
private final java.util.concurrent.locks.Lock lock = new ReentrantLock();
private final java.util.concurrent.locks.Condition condition = lock.newCondition();
public void await() {
try {
lock.lock();
//获取到锁lock
condition.await(); //等待condition通信信号,释放condition锁
//接到condition通信
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock(); //释放对象锁lock
}
}
12、ReentrantReadWriteLock的使用
ReentrantReadWriteLock是对ReentrantLock 更进一步的扩展,实现了读锁readLock()(共享锁)和写锁writeLock()(独占锁),实现读写分离。读和读之间不会互斥,读和写、写和读、写和写之间才会互斥,提升了读写的性能。
读锁示例:
1
2
3
4
5
6
7
8
9
private final java.util.concurrent.locks.ReadWriteLock lock = new ReentrantReadWriteLock();
public void method() {
try {
lock.readLock().lock();
//获取到读锁readLock,同步块
} finally {
lock.readLock().unlock(); //释放读锁readLock
}
}
写锁示例:
1
2
3
4
5
6
7
8
9
private final java.util.concurrent.locks.ReadWriteLock lock = new ReentrantReadWriteLock();
public void method() {
try {
lock.writeLock().lock();
//获取到写锁writeLock,同步块
} finally {
lock.writeLock().unlock(); //释放写锁writeLock
}
}
13、同步容器与异步容器概览
(1)同步容器
包括两部分:
一个是早期JDK的Vector、Hashtable;
一个是它们的同系容器,JDK1.2加入的同步包装类,使用Collections.synchronizedXxx工厂方法创建。
1
Map<String, Integer> hashmapSync = Collections.synchronizedMap( new HashMap<String, Integer>());
同步容器都是线程安全的,一次只有一个线程访问容器的状态。
但在某些场景下可能需要加锁来保护复合操作。
复合类操作如:新增、删除、迭代、跳转以及条件运算。
这些复合操作在多线程并发的修改容器时,可能会表现出意外的行为,
最经典的便是ConcurrentModificationException,
原因是当容器迭代的过程中,被并发的修改了内容,这是由于早期迭代器设计的时候并没有考虑并发修改的问题。
其底层的机制无非就是用传统的synchronized关键字对每个公用的方法都进行同步,使得每次只能有一个线程访问容器的状态。这很明显不满足我们今天互联网时代高并发的需求,在保证线程安全的同时,也必须有足够好的性能。
(2)并发容器
与Collections.synchronizedXxx()同步容器等相比,util.concurrent中引入的并发容器主要解决了两个问题:
1)根据具体场景进行设计,尽量避免synchronized,提供并发性。
2)定义了一些并发安全的复合操作,并且保证并发环境下的迭代操作不会出错。
util.concurrent中容器在迭代时,可以不封装在synchronized中,可以保证不抛异常,但是未必每次看到的都是”最新的、当前的”数据。
1
Map<String, Integer> concurrentHashMap = new ConcurrentHashMap<String, Integer>()
ConcurrentHashMap 替代同步的Map即(Collections.synchronized(new HashMap()))。众所周知,HashMap是根据散列值分段存储的,同步Map在同步的时候会锁住整个Map,而ConcurrentHashMap在设计存储的时候引入了段落Segment定义,同步的时候只需要锁住根据散列值锁住了散列值所在的段落即可,大幅度提升了性能。ConcurrentHashMap也增加了对常用复合操作的支持,比如”若没有则添加”:putIfAbsent(),替换:replace()。这2个操作都是原子操作。注意的是ConcurrentHashMap 弱化了size()和isEmpty()方法,并发情况尽量少用,避免导致可能的加锁(当然也可能不加锁获得值,如果map数量没有变化的话)。
CopyOnWriteArrayList和CopyOnWriteArraySet分别代替List和Set,主要是在遍历操作为主的情况下来代替同步的List和同步的Set,这也就是上面所述的思路:迭代过程要保证不出错,除了加锁,另外一种方法就是”克隆”容器对象。—缺点也明显,占有内存,且数据最终一致,但数据实时不一定一致,一般用于读多写少的并发场景。
ConcurrentSkipListMap可以在高效并发中替代SoredMap(例如用Collections.synchronzedMap包装的TreeMap)。
ConcurrentSkipListSet可以在高效并发中替代SoredSet(例如用Collections.synchronzedSet包装的TreeMap)。
ConcurrentLinkedQuerue是一个先进先出的队列。它是非阻塞队列。注意尽量用isEmpty,而不是size();
14、CountDownLatch闭锁的使用
CountDownLatch是一个同步辅助类。
通常运用场景:
(1)作为启动信号:将计数 1 初始化的 CountDownLatch 用作一个简单的开/关锁存器,或入口。
通俗描述:田径赛跑运动员等待(每位运动员为一个线程,都在await())的”发令枪”,当发令枪countDown(),喊0的时候,所有运动员跳过await()起跑线并发跑起来了。
(2)作为结束信号:在通过调用 countDown() 的线程打开入口前,所有调用 await 的线程都一直在入口处等待。用 N 初始化的 CountDownLatch 可以使一个线程在 N 个线程完成某项操作之前一直等待,或者使其在某项操作完成 N 次之前一直等待。
通俗描述:某裁判,在终点等待所有运动员都跑完,每个运动员跑完就计数一次(countDown())当为0时,就可以往下继续统计第一人到最后一个撞线的时间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
public long timeTasks( int nThreads, final Runnable task) throws InterruptedException {
/**
*一个启动信号,在 driver 为继续执行 worker 做好准备之前,它会阻止所有的 worker 继续执行。
*/
final CountDownLatch startSignal = new CountDownLatch( 1 );
/**
* 一个完成信号,它允许 driver 在完成所有 worker 之前一直等待。
*/
final CountDownLatch doneSignal = new CountDownLatch(nThreads);
for ( int i = 0 ; i < nThreads; i++) {
Thread t = new Thread() {
public void run() {
try {
startSignal.await(); /** 阻塞于此,一直到startSignal计数为0,再往下执行 */
try {
task.run();
} finally {
doneSignal.countDown(); /** doneSignal 计数减一,直到最后一个线程结束 */
}
} catch (InterruptedException ignored) {
}
}
};
t.start();
}
long start = System.currentTimeMillis();
startSignal.countDown(); /** doneSignal 计数减一,为0,所有task开始并发执行run */
doneSignal.await(); /** 阻塞于此,一直到doneSignal计数为0,再往下执行 */
long end = System.currentTimeMillis();
return end - start;
}
public static void main(String[] args) throws InterruptedException {
final Runnable task = new Runnable() {
@Override
public void run() {
try {
Thread.sleep(( long ) (Math.random() * 1000 ));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " end" );
}
};
long time = new CountDownLatchTest().timeTasks( 10 , task);
System.out.println( "耗时:" + time + "ms" );
}
更多的api:
boolean await(long timeout, TimeUnit unit) 使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断或超出了指定的等待时间。
15、CyclicBarrier关卡的使用
CyclicBarrier是一个同步辅助类。
CyclicBarrier让一个线程达到屏障时被阻塞,直到最后一个线程达到屏障时,屏障才会开门,所有被屏障拦截的线程才会继续执行
CyclicBarrier(int parties, Runnable barrierAction)构造函数,用于在所有线程都到达屏障后优先执行barrierAction的run()方法
使用场景:
可以用于多线程计算以后,最后使用合并计算结果的场景;
通俗描述:某裁判,在终点(await()阻塞处)等待所有运动员都跑完,所有人都跑完就可以做吃炸鸡啤酒(barrierAction),但是只要一个人没跑完就都不能吃炸鸡啤酒,当然也没规定他们同时跑(当然也可以,一起使用CountDownLatch)。
————————————————————————————–
CyclicBarrier与CountDownLatch的区别:
CountDownLatch强调的是一个线程等待多个线程完成某件事,只能用一次,无法重置;
CyclicBarrier强调的是多个线程互相等待完成,才去做某个事情,可以重置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
public static class WorkerThread implements Runnable {
private final CyclicBarrier cyclicBarrier;
public WorkerThread(CyclicBarrier cyclicBarrier) {
this .cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + " pre-working" );
/**
* 线程在这里等待,直到所有线程都到达barrier。
*/
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " working" );
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
int THREAD_NUM = 5 ;
final CyclicBarrier cyclicBarrier = new CyclicBarrier(THREAD_NUM, new Runnable() {
/**
* 当所有线程到达barrier时执行
*/
@Override
public void run() {
System.out.println( "--------------Inside Barrier--------------" );
}
});
for ( int i = 0 ; i < THREAD_NUM; i++) {
new Thread( new WorkerThread(cyclicBarrier)).start();
}
}
更多api:
int await(long timeout, TimeUnit unit) 在所有参与者都已经在此屏障上调用 await 方法之前将一直等待,或者超出了指定的等待时间。
16、Semaphore信号量的使用
Semaphore信号量是一个计数信号量。
可以认为,Semaphore维护一个许可集。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release() 添加一个许可,从而可能释放一个正在阻塞的获取者。
通俗描述:某个车库只有N个车位,车主们要泊车,请向车库保安处阻塞 acquire()等待获取许可证,当获得许可证,车主们才可以去泊车。当某个车主离开车位的时候,交还许可证release() ,从而其他阻塞等待的车主有机会获得许可证。
另外:
Semaphore 默认是非公平策略,允许线程“抢占插队”获取许可证。公平策略则是线程依照请求的顺序获取许可证,近似FIFO的策略方式。
17、Executors框架(线程池)的使用
(1)线程池是什么?
线程池是一种多线程的处理方式,利用已有线程对象继续服务新的任务(按照一定的执行策略),而不是频繁地创建销毁线程对象,由此提供服务的吞吐能力,减少CPU的闲置时间。具体组成部分包括:
a、线程池管理器(ThreadPool)用于创建和管理线程池,包括创建线程池、销毁线程池,添加新任务。
b、工作线程(Worker)线程池中的线程,闲置的时候处于等待状态,可以循环回收利用。
c、任务接口(Task)每个任务必须实现的接口类,为工作线程提供调用,主要规定了任务的入口、任务完成的收尾工作、任务的状态。
d、等待队列(Queue)存放等待处理的任务,提供缓冲机制。
(2)Executors框架常见的执行策略
Executors框架提供了一些便利的执行策略。
1
java.util.concurrent.ExecutorService service = java.util.concurrent.Executors.newFixedThreadPool( 100 );
- newSingleThreadExecutor:创建一个单线程的线程池。
这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
- newFixedThreadPool:创建固定大小的线程池。
每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
- newCachedThreadPool:创建一个可缓存的线程池。
如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
- newScheduledThreadPool:创建一个大小无限的线程池。
此线程池支持定时以及周期性执行任务的需求。
- newSingleThreadScheduledExecutor:创建一个单线程的线程池。
此线程池支持定时以及周期性执行任务的需求。
(3)ExecutorService线程池管理
ExecutorService的生命周期有3个状态:运行、关闭(shutting down)、停止。
提交任务submit(xxx)扩展了基本方法 Executor.execute(java.lang.Runnable)。
Future<?> submit(Runnable task) 提交一个 Runnable 任务用于执行,并返回一个表示该任务的 Future。
shutdown() 启动一次顺序关闭,执行以前提交的任务,但不接受新任务。
List
一个简单的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool( 10 );
for ( int i = 0 ; i < 100 ; i++) {
executorService.submit( new Runnable() {
@Override
public void run() {
System.out.println( "哈哈" );
}
});
}
/**
* 如果不再需要新任务,请适当关闭executorService并拒绝新任务
*/
executorService.shutdown();
}
(3)ThreadPoolExecutor机制
ThreadPoolExecutor为Executors的线程池内部实现类。
构造函数详解:

ThreadPoolExecutor线程池管理机制:

1.当线程池小于corePoolSize时,新提交任务将创建一个新线程执行任务,即使此时线程池中存在空闲线程。
2.当线程池达到corePoolSize时,新提交任务将被放入workQueue中,等待线程池中任务调度执行
3.当workQueue已满,且maximumPoolSize>corePoolSize时,新提交任务会创建新线程执行任务
4.当提交任务数超过maximumPoolSize时,新提交任务由RejectedExecutionHandler处理
5.当线程池中超过corePoolSize线程,空闲时间达到keepAliveTime时,关闭空闲线程
6.当设置allowCoreThreadTimeOut(true)时,线程池中corePoolSize线程空闲时间达到keepAliveTime也将关闭
一个简单的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public static void main(String[] args) {
java.util.concurrent.ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor( 10 , //corePoolSize 核心线程数
100 , //maximumPoolSize 最大线程数
30 , //keepAliveTime 线程池中超过corePoolSize数目的空闲线程最大存活时间;
// TimeUnit keepAliveTime时间单位
TimeUnit.SECONDS,
//workQueue 阻塞任务队列
new LinkedBlockingQueue<Runnable>( 1000 ),
//threadFactory 新建线程的工厂
Executors.defaultThreadFactory(),
//RejectedExecutionHandler当提交任务数超过maxmumPoolSize+workQueue之和时,
// 任务会交给RejectedExecutionHandler来处理
new ThreadPoolExecutor.AbortPolicy()
);
for ( int i = 0 ; i < 100 ; i++) {
threadPoolExecutor.submit( new Runnable() {
@Override
public void run() {
System.out.println( "哈哈" );
}
});
}
/**
* 如果不再需要新任务,请适当关闭threadPoolExecutor并拒绝新任务
*/
threadPoolExecutor.shutdown();
}
18、可携带结果的任务Callable 和 Future / FutureTask
(1)为解决Runnable接口不能返回一个值或受检查的异常,可以采用Callable接口实现一个任务。
1
2
3
4
5
6
7
8
9
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
(2)Future表示异步计算的结果,可以对于具体的Runnable或者Callable任务进行查询是否完成,查询是否取消,获取执行结果,取消任务等操作。
V get() throws InterruptedException, ExecutionException 如有必要,等待计算完成,然后获取其结果。
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException 如有必要,最多等待为使计算完成所给定的时间之后,获取其结果(如果结果可用)。
(3)FutureTask
FutureTask则是一个RunnableFuture
简单示例一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public static void main(String[] args) throws InterruptedException {
FutureTask<Integer> future = new FutureTask<Integer>( new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// 返回一个值或受检查的异常
//throw new Exception();
return new Random().nextInt( 100 );
}
});
new Thread(future).start();;
/**
* 模拟其他业务逻辑
*/
Thread.sleep( 1000 );
//Integer result = future.get(0, TimeUnit.SECONDS);
Integer result = null ;
try {
result = future.get();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println( "result========" + result);
}
简单示例二,采用Executors:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public static void main(String[] args) throws InterruptedException {
java.util.concurrent.ExecutorService threadPoolExecutor =
java.util.concurrent.Executors.newCachedThreadPool();
Future<Integer> future = threadPoolExecutor.submit(
new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// 返回一个值或受检查的异常
//throw new Exception();
return new Random().nextInt( 100 );
}
});
/**
* 如果不再需要新任务,请适当关闭threadPoolExecutor并拒绝新任务
*/
threadPoolExecutor.shutdown();
/**
* 模拟其他业务逻辑
*/
Thread.sleep( 1000 );
//Integer result = future.get(0, TimeUnit.SECONDS);
Integer result = null ;
try {
result = future.get();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println( "result========" + result);
}
简单示例三,采用Executors+CompletionService:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
static class MyCallable implements Callable<Integer> {
private final int i;
public MyCallable( int i) {
super ();
this .i = i;
}
@Override
public Integer call() throws Exception {
// 返回一个值或受检查的异常
//throw new Exception();
return new Integer(i);
}
}
public static void main(String[] args) throws InterruptedException {
java.util.concurrent.ExecutorService threadPoolExecutor =
java.util.concurrent.Executors.newCachedThreadPool();
java.util.concurrent.CompletionService<Integer> completionService =
new java.util.concurrent.ExecutorCompletionService<Integer>(threadPoolExecutor);
final int threadNum = 10 ;
for ( int i = 0 ; i < threadNum; i++) {
completionService.submit( new MyCallable(i + 1 ));
}
/**
* 如果不再需要新任务,请适当关闭threadPoolExecutor并拒绝新任务
*/
threadPoolExecutor.shutdown();
/**
* 模拟其他业务逻辑
*/
Thread.sleep( 2000 );
for ( int i = 0 ; i < threadNum; i++) {
try {
System.out.println( "result========" + completionService.take().get());
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
注意的是提交到CompletionService中的Future是按照完成的顺序排列的,而不是按照添加的顺序排列的。
19、Atomic系列-原子变量类
其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。其中的类可以分成4组
基本类:AtomicInteger、AtomicLong、AtomicBoolean;
引用类型:AtomicReference、AtomicStampedRerence、AtomicMarkableReference;–AtomicStampedReference 或者 AtomicMarkableReference 解决线程并发中,导致的ABA问题
数组类型:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray —数组长度固定不可变,但保证数组上每个元素的操作绝对安全的
属性原子修改器(Updater):AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater
Updater使用限制:
限制1:操作的目标不能是static类型,前面说到unsafe的已经可以猜测到它提取的是非static类型的属性偏移量,如果是static类型在获取时如果没有使用对应的方法是会报错的,而这个Updater并没有使用对应的方法。
限制2:操作的目标不能是final类型的,因为final根本没法修改。
限制3:必须是volatile类型的数据,也就是数据本身是读一致的。
限制4:属性必须对当前的Updater所在的区域是可见的,也就是private如果不是当前类肯定是不可见的,protected如果不存在父子关系也是不可见的,default如果不是在同一个package下也是不可见的。
简单示例:
1
2
3
4
5
static class A {
volatile int intValue = 100 ;
}
private AtomicIntegerFieldUpdater<A> atomicIntegerFieldUpdater
= AtomicIntegerFieldUpdater.newUpdater(A. class , "intValue" );
20、总结
什么叫线程安全?
线程安全就是每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的。
线程安全就是说多线程访问同一代码,不会产生不确定的结果。
线程安全问题多是由全局变量和静态变量引起的,当多个线程对共享数据只执行读操作,不执行写操作时,一般是线程安全的;当多个线程都执行写操作时,需要考虑线程同步来解决线程安全问题。
什么叫线程同步?
多个线程操作一个资源的情况下,导致资源数据前后不一致。这样就需要协调线程的调度,即线程同步。 解决多个线程使用共通资源的方法是:线程操作资源时独占资源,其他线程不能访问资源。使用锁可以保证在某一代码段上只有一条线程访问共用资源。
有两种方式实现线程同步:
1、synchronized
2、同步锁(Lock)
什么叫线程通信?
有时候线程之间需要协作和通信。
有两种方式实现线程通信:
1、synchronized 实现内存可见性,满足线程共享变量
2、wait/notify\notifyAll(synchronized同步方法或同步块中使用) 实现内存可见性,及生产消费模式的相互唤醒机制
3、同步锁(Lock)的Condition(await\signal\signalAll)
4、管道,实现数据的共享,满足读写模式











