
不少人看到 J2Cache 第一眼时,会认为这就是一个普普通通的缓存框架,和例如 Ehcache、Caffeine 、Spring Cache 之类的项目没什么区别,无非是造了一个新的轮子而已。事实上完全不是一回事!
目前缓存的解决方案一般有两种:
- 内存缓存(如 Ehcache) —— 速度快,进程内可用
- 集中式缓存(如 Redis)—— 可同时为多节点提供服务
现有的缓存框架已经非常成熟而且优秀,J2Cache 无心造一个新的轮子,它要解决的几个问题如下:
- 使用内存缓存时,一旦应用重启后,由于缓存数据丢失,缓存雪崩,给数据库造成巨大压力,导致应用堵塞
- 使用内存缓存时,多个应用节点无法共享缓存数据
- 使用集中式缓存,由于大量的数据通过缓存获取,导致缓存服务的数据吞吐量太大,带宽跑满。现象就是 Redis 服务负载不高,但是由于机器网卡带宽跑满,导致数据读取非常慢
在遭遇问题1、2 时,很多人自然而然会想到使用 Redis 来缓存数据,因此就难以避免的导致了问题3的发生。
当发生问题 3 时,又有很多人想到 Redis 的集群,通过集群来降低缓存服务的压力,特别是带宽压力。
但其实,这个时候的 Redis 上的数据量并不一定大,仅仅是数据的吞吐量大而已。
咱们假设这样一个场景:
有这么一个网站,某个页面每天的访问量是 1000万,每个页面从缓存读取的数据是 50K。缓存数据存放在一个 Redis 服务,机器使用千兆网卡。那么这个 Redis 一天要承受 500G 的数据流,相当于平均每秒钟是 5.78M 的数据。而网站一般都会有高峰期和低峰期,两个时间流量的差异可能是百倍以上。我们假设高峰期每秒要承受的流量比平均值高 50 倍,也就是说高峰期 Redis 服务每秒要传输超过 250 兆的数据。请注意这个 250 兆的单位是 byte,而千兆网卡的单位是“bit” ,你懂了吗? 这已经远远超过 Redis 服务的网卡带宽。
所以如果你能发现这样的问题,一般你会这么做:
- 升级到万兆网卡 —— 这个有多麻烦,相信很多人知道,特别是一些云主机根本没有万兆网卡给你使用(有些运维工程师会给这样的建议)
- 多个 Redis 搭建集群,将流量分摊多多台机器上
如果你采用第2种方法来解决上述的场景中碰到的问题,那么你最好准备 5 个 Redis 服务来支撑。在缓存服务这块成本直接攀升了 5 倍。你有钱当然没任何问题,但是结构就变得非常复杂了,而且可能你缓存的数据量其实不大,1000 万高频次的缓存读写 Redis 也能轻松应付,可是因为带宽的问题,你不得不付出 5 倍的成本。
那么 J2Cache 的用武之处就在这里。
如果我们不用每次页面访问的时候都去 Redis 读取数据,那么 Redis 上的数据流量至少降低 1000 倍甚至更多,以至于一台 Redis 可以轻松应付。
J2Cache 其实不是一个缓存框架,它是一个缓存框架的桥梁。它利用现有优秀的内存缓存框架作为一级缓存,而把 Redis 作为二级缓存。所有数据的读取先从一级缓存中读取,不存在时再从二级缓存读取,这样来确保对二级缓存 Redis 的访问次数降到最低。
有人会质疑说,那岂不是应用节点的内存占用要飙升?我的答案是 —— 现在服务器的内存都是几十 G 打底,多则百 G 数百 G,这点点的内存消耗完全不在话下。其次一级缓存框架可以通过配置来控制在内存中存储的数据量,所以不用担心内存溢出的问题。
剩下的另外一个问题就是,当缓存数据更新的时候,怎么确保每个节点内存中的数据是一致的。而这一点算你问到点子上了,这恰恰是 J2Cache 的核心所在。
J2Cache 目前提供两种节点间数据同步的方案 —— Redis Pub/Sub 和 JGroups 。当某个节点的缓存数据需要更新时,J2Cache 会通过 Redis 的消息订阅机制或者是 JGroups 的组播来通知集群内其他节点。当其他节点收到缓存数据更新的通知时,它会清掉自己内存里的数据,然后重新从 Redis 中读取最新数据。
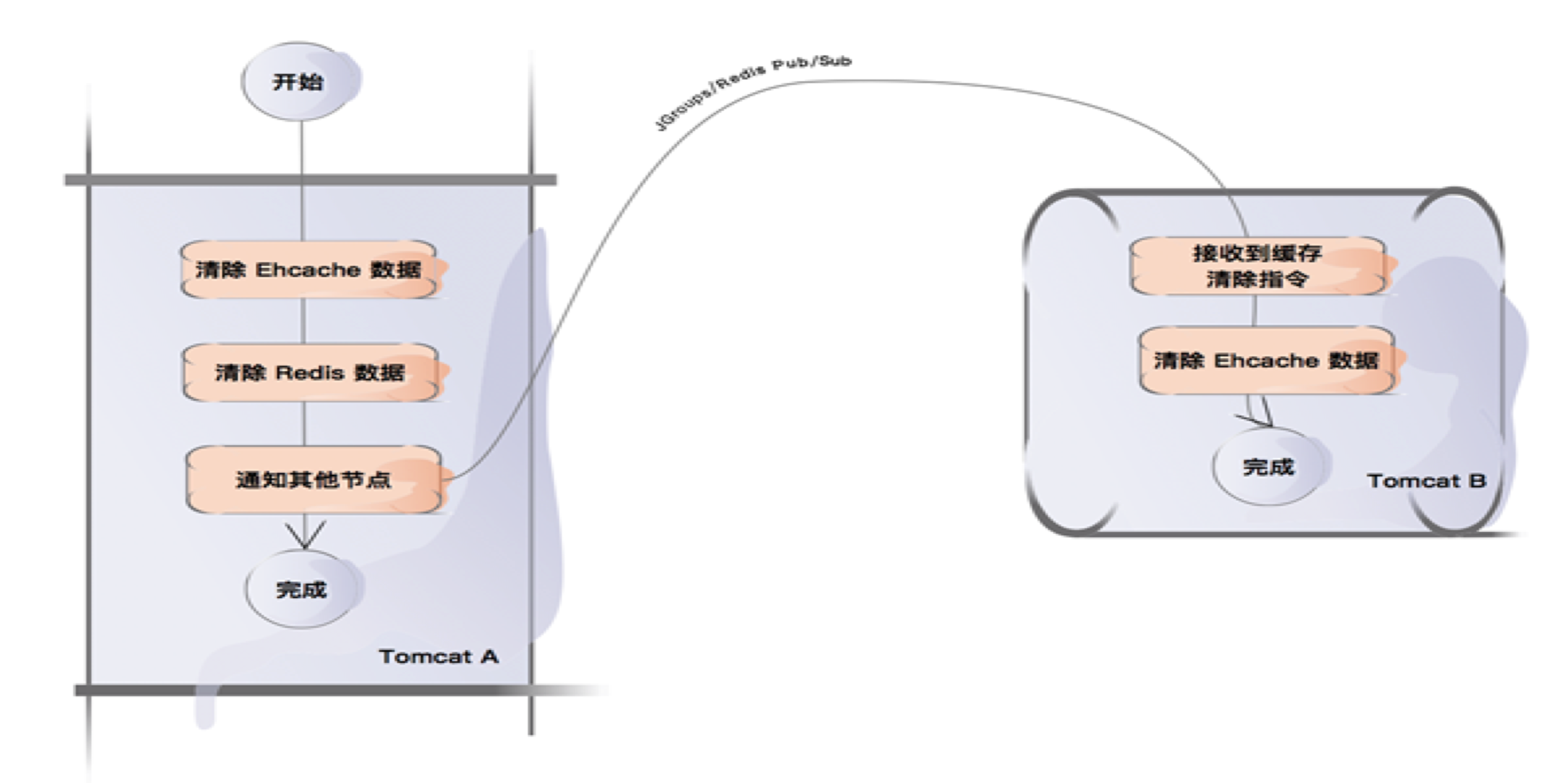
这就完成了 J2Cache 缓存数据读写的闭环。
为什么不用 Ehcache 的集群方案?
对 Ehcache 比较熟悉的人还会问的就是这个问题,Ehcache 本身是提供集群模式的,可以在多个节点同步缓存数据。但是 Ehcache 的做法是将整个缓存数据在节点间进行传输。如咱们前面的说的,一个页面需要读取 50K 的缓存数据,当这 50K 的缓存数据有更新时,那么需要在几个节点间传递整个 50K 的数据。这也会造成应用节点间大量的数据传输,这个情况完全不可控。
补充:当然这个单个数据传输量本身并不比使用 J2Cache 多,但是 ehcache 利用 jgroups 来同步数据的做法,在实际测试过程中发现可靠性还是略低,而且 jgroups 的同步数据在云主机上无法使用。
而 J2Cache 传输的仅仅是缓存的 key 而已,因此相比 Ehcache 的集群模式,J2Cache 要传输的数据极其小,对节点间的数据通信完全不会产生大的影响。
--------
更详细的介绍请参考 https://gitee.com/ld/J2Cache 项目的 Readme ,以及 Readme 里的视频讲解。










