
源码分析 RocketMQ DLedger 多副本系列已经进行到第 8 篇了,前面的章节主要是介绍了基于 raft 协议的选主与日志复制,从本篇开始将开始关注如何将 DLedger 应用到 RocketMQ中。
> 摘要:详细分析了RocketMQ DLedger 多副本(主从切换) 是如何整合到 RocketMQ中,本文的行文思路首先结合已掌握的DLedger 多副本相关的知识初步思考其实现思路,然后从 Broker启动流程、DLedgerCommitlog 核心类的讲解,再从消息发送(追加)与消息查找来进一步探讨 DLedger 是如何支持平滑升级的。
1、阅读源码之前的思考
RocketMQ 的消息存储文件主要包括 commitlog 文件、consumequeue 文件与 Index 文件。commitlog 文件存储全量的消息,consumequeue、index 文件都是基于 commitlog 文件构建的。要使用 DLedger 来实现消息存储的一致性,应该关键是要实现 commitlog 文件的一致性,即 DLedger 要整合的对象应该是 commitlog 文件,即只需保证 raft 协议的复制组内各个节点的 commitlog 文件一致即可。
我们知道使用文件存储消息都会基于一定的存储格式,rocketmq 的 commitlog 一个条目就包含魔数、消息长度,消息属性、消息体等,而我们再来回顾一下 DLedger 日志的存储格式: 
DLedger 要整合 commitlog 文件,是不是可以把 rocketmq 消息,即一个个 commitlog 条目整体当成 DLedger 的 body 字段即可。
还等什么,跟我一起来看源码吧!!!别急,再抛一个问题,DLedger 整合 RocketMQ commitlog,能不能做到平滑升级?
带着这些思考和问题,一起来探究 DLedger 是如何整合 RocketMQ 的。
2、从 Broker 启动流程看 DLedger
> 温馨提示:本文不会详细介绍 Broker 端的启动流程,只会点出在启动过程中与 DLedger 相关的代码,如想详细了解 Broker 的启动流程,建议关注笔者的《RocketMQ技术内幕》一书。
Broker 涉及到 DLedger 相关关键点如下: 
2.1 构建 DefaultMessageStore
DefaultMessageStore 构造方法
if(messageStoreConfig.isEnableDLegerCommitLog()) { // [@1](https://my.oschina.net/u/1198)
this.commitLog = new DLedgerCommitLog(this);
else {
this.commitLog = new CommitLog(this); // @2
}
代码@1:如果开启 DLedger ,commitlog 的实现类为 DLedgerCommitLog,也是本文需要关注的关键所在。
代码@2:如果未开启 DLedger,则使用旧版的 Commitlog实现类。
2.2 增加节点状态变更事件监听器
BrokerController#initialize
if (messageStoreConfig.isEnableDLegerCommitLog()) {
DLedgerRoleChangeHandler roleChangeHandler = new DLedgerRoleChangeHandler(this, (DefaultMessageStore) messageStore);
((DLedgerCommitLog)((DefaultMessageStore) messageStore).getCommitLog()).getdLedgerServer().getdLedgerLeaderElector().addRoleChangeHandler(roleChangeHandler);
}
主要调用 LedgerLeaderElector 的 addRoleChanneHandler 方法增加 节点角色变更事件监听器,DLedgerRoleChangeHandler 是实现主从切换的另外一个关键点。
2.3 调用 DefaultMessageStore 的 load 方法
DefaultMessageStore#load
// load Commit Log
result = result && this.commitLog.load(); // [@1](https://my.oschina.net/u/1198)
// load Consume Queue
result = result && this.loadConsumeQueue();
if (result) {
this.storeCheckpoint = new StoreCheckpoint(StorePathConfigHelper.getStoreCheckpoint(this.messageStoreConfig.getStorePathRootDir()));
this.indexService.load(lastExitOK);
this.recover(lastExitOK); // @2
log.info("load over, and the max phy offset = {}", this.getMaxPhyOffset());
}
代码@1、@2 最终都是委托 commitlog 对象来执行,这里的关键又是如果开启了 DLedger,则最终调用的是 DLedgerCommitLog。
经过上面的铺垫,主角 DLedgerCommitLog “闪亮登场“了。
3、DLedgerCommitLog 详解
> 温馨提示:由于 Commitlog 的绝大部分方法都已经在《RocketMQ技术内幕》一书中详细介绍了,并且 DLedgerCommitLog 的实现原理与 Commitlog 文件的实现原理类同,本文会一笔带过关于存储部分的实现细节。
3.1 核心类图

DLedgerCommitlog 继承自 Commitlog。让我们一一来看一下它的核心属性。
- DLedgerServer dLedgerServer 基于 raft 协议实现的集群内的一个节点,用 DLedgerServer 实例表示。
- DLedgerConfig dLedgerConfig DLedger 的配置信息。
- DLedgerMmapFileStore dLedgerFileStore DLedger 基于文件映射的存储实现。
- MmapFileList dLedgerFileList DLedger 所管理的存储文件集合,对比 RocketMQ 中的 MappedFileQueue。
- int id 节点ID,0 表示主节点,非0表示从节点
- MessageSerializer messageSerializer 消息序列器。
- long beginTimeInDledgerLock = 0 用于记录 消息追加的时耗(日志追加所持有锁时间)。
- long dividedCommitlogOffset = -1 记录的旧 commitlog 文件中的最大偏移量,如果访问的偏移量大于它,则访问 dledger 管理的文件。
- boolean isInrecoveringOldCommitlog = false 是否正在恢复旧的 commitlog 文件。
接下来我们将详细介绍 DLedgerCommitlog 各个核心方法及其实现要点。
3.2 构造方法
public DLedgerCommitLog(final DefaultMessageStore defaultMessageStore) {
super(defaultMessageStore); // @1
dLedgerConfig = new DLedgerConfig();
dLedgerConfig.setEnableDiskForceClean(defaultMessageStore.getMessageStoreConfig().isCleanFileForciblyEnable());
dLedgerConfig.setStoreType(DLedgerConfig.FILE);
dLedgerConfig.setSelfId(defaultMessageStore.getMessageStoreConfig().getdLegerSelfId());
dLedgerConfig.setGroup(defaultMessageStore.getMessageStoreConfig().getdLegerGroup());
dLedgerConfig.setPeers(defaultMessageStore.getMessageStoreConfig().getdLegerPeers());
dLedgerConfig.setStoreBaseDir(defaultMessageStore.getMessageStoreConfig().getStorePathRootDir());
dLedgerConfig.setMappedFileSizeForEntryData(defaultMessageStore.getMessageStoreConfig().getMapedFileSizeCommitLog());
dLedgerConfig.setDeleteWhen(defaultMessageStore.getMessageStoreConfig().getDeleteWhen());
dLedgerConfig.setFileReservedHours(defaultMessageStore.getMessageStoreConfig().getFileReservedTime() + 1);
id = Integer.valueOf(dLedgerConfig.getSelfId().substring(1)) + 1; // @2
dLedgerServer = new DLedgerServer(dLedgerConfig); // @3
dLedgerFileStore = (DLedgerMmapFileStore) dLedgerServer.getdLedgerStore();
DLedgerMmapFileStore.AppendHook appendHook = (entry, buffer, bodyOffset) -> {
assert bodyOffset == DLedgerEntry.BODY_OFFSET;
buffer.position(buffer.position() + bodyOffset + MessageDecoder.PHY_POS_POSITION);
buffer.putLong(entry.getPos() + bodyOffset);
};
dLedgerFileStore.addAppendHook(appendHook); // @4
dLedgerFileList = dLedgerFileStore.getDataFileList();
this.messageSerializer = new MessageSerializer(defaultMessageStore.getMessageStoreConfig().getMaxMessageSize()); // @5
}
代码@1:调用父类 即 CommitLog 的构造函数,加载 ${ROCKETMQ_HOME}/store/ comitlog 下的 commitlog 文件,以便兼容升级 DLedger 的消息。我们稍微看一下 CommitLog 的构造函数: 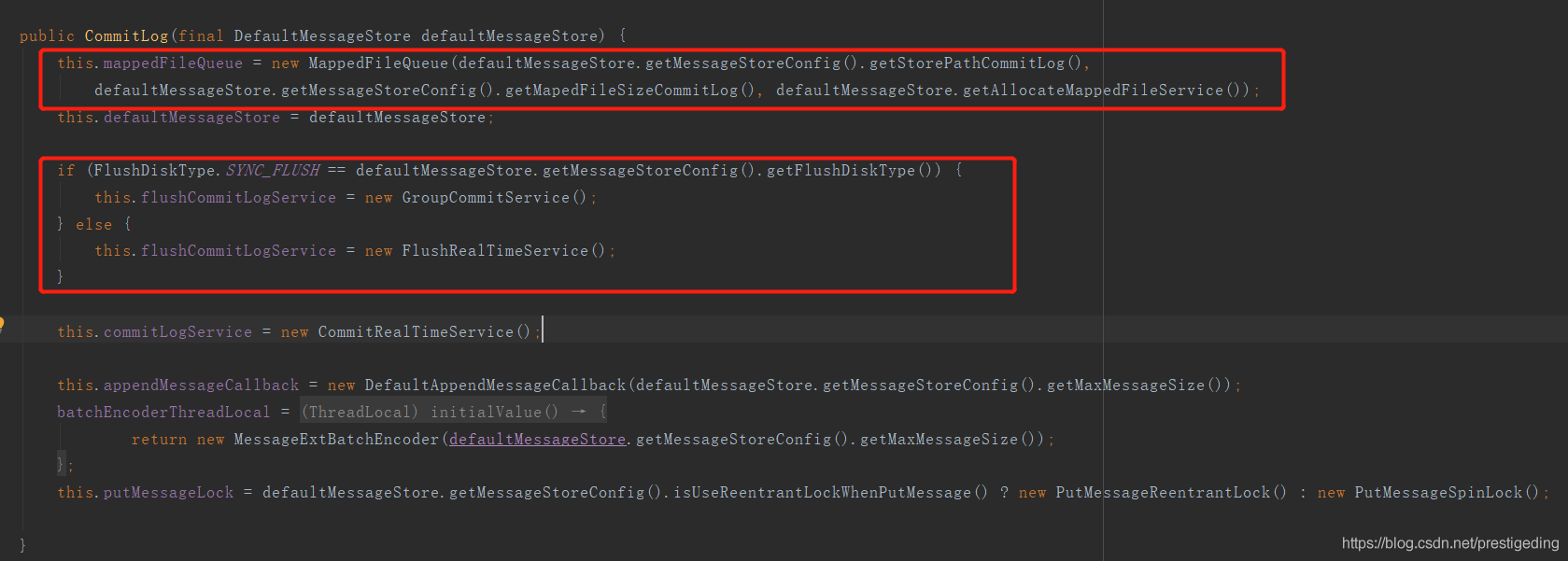
代码@2:构建 DLedgerConfig 相关配置属性,其主要属性如下:
- enableDiskForceClean 是否强制删除文件,取自 broker 配置属性 cleanFileForciblyEnable,默认为 true 。
- storeType DLedger 存储类型,固定为 基于文件的存储模式。
- dLegerSelfId leader 节点的 id 名称,示例配置:n0,其配置要求第二个字符后必须是数字。
- dLegerGroup DLeger group 的名称,建议与 broker 配置属性 brokerName 保持一致。
- dLegerPeers DLeger Group 中所有的节点信息,其配置示例 n0-127.0.0.1:40911;n1-127.0.0.1:40912;n2-127.0.0.1:40913。多个节点使用分号隔开。
- storeBaseDir 设置 DLedger 的日志文件的根目录,取自 borker 配件文件中的 storePathRootDir ,即 RocketMQ 的数据存储根路径。
- mappedFileSizeForEntryData 设置 DLedger 的单个日志文件的大小,取自 broker 配置文件中的 - mapedFileSizeCommitLog,即与 commitlog 文件的单个文件大小一致。
- deleteWhen DLedger 日志文件的删除时间,取自 broker 配置文件中的 deleteWhen,默认为凌晨 4点。
- fileReservedHours DLedger 日志文件保留时长,取自 broker 配置文件中的 fileReservedHours,默认为 72h。
代码@3:根据 DLedger 配置信息创建 DLedgerServer,即创建 DLedger 集群节点,集群内各个节点启动后,就会触发选主。
代码@4:构建 appendHook 追加钩子函数,这是兼容 Commitlog 文件很关键的一步,后面会详细介绍其作用。
代码@5:构建消息序列化。
根据上述的流程图,构建好 DefaultMessageStore 实现后,就是调用其 load 方法,在启用 DLedger 机制后,会依次调用 DLedgerCommitlog 的 load、recover 方法。
3.3 load
public boolean load() {
boolean result = super.load();
if (!result) {
return false;
}
return true;
}
DLedgerCommitLog 的 laod 方法实现比较简单,就是调用 其父类 Commitlog 的 load 方法,即这里也是为了启用 DLedger 时能够兼容以前的消息。
3.4 recover
在 Broker 启动时会加载 commitlog、consumequeue等文件,需要恢复其相关是数据结构,特别是与写入、刷盘、提交等指针,其具体调用 recover 方法。 DLedgerCommitLog#recover
public void recoverNormally(long maxPhyOffsetOfConsumeQueue) { // @1
recover(maxPhyOffsetOfConsumeQueue);
}
首先会先恢复 consumequeue,得出 consumequeue 中记录的最大有效物理偏移量,然后根据该物理偏移量进行恢复。 接下来看一下该方法的处理流程与关键点。
DLedgerCommitLog#recover
dLedgerFileStore.load();
Step1:加载 DLedger 相关的存储文件,并一一构建对应的 MmapFile,其初始化三个重要的指针 wrotePosition、flushedPosition、committedPosition 三个指针为文件的大小。
DLedgerCommitLog#recover
if (dLedgerFileList.getMappedFiles().size() > 0) {
dLedgerFileStore.recover(); // @1
dividedCommitlogOffset = dLedgerFileList.getFirstMappedFile().getFileFromOffset(); // @2
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
if (mappedFile != null) { // @3
disableDeleteDledger();
}
long maxPhyOffset = dLedgerFileList.getMaxWrotePosition();
// Clear ConsumeQueue redundant data
if (maxPhyOffsetOfConsumeQueue >= maxPhyOffset) { // @4
log.warn("[TruncateCQ]maxPhyOffsetOfConsumeQueue({}) >= processOffset({}), truncate dirty logic files", maxPhyOffsetOfConsumeQueue, maxPhyOffset);
this.defaultMessageStore.truncateDirtyLogicFiles(maxPhyOffset);
}
return;
}
Step2:如果已存在 DLedger 的数据文件,则只需要恢复 DLedger 相关数据文建,因为在加载旧的 commitlog 文件时已经将其重要的数据指针设置为最大值。其关键实现点如下:
- 首先调用 DLedger 文件存储实现类 DLedgerFileStore 的 recover 方法,恢复管辖的 MMapFile 对象(一个文件对应一个MMapFile实例)的相关指针,其实现方法与 RocketMQ 的 DefaultMessageStore 的恢复过程类似。
- 设置 dividedCommitlogOffset 的值为 DLedger 中所有物理文件的最小偏移量。操作消息的物理偏移量小于该值,则从 commitlog 文件中查找;物理偏移量大于等于该值的话则从 DLedger 相关的文件中查找消息。
- 如果存在旧的 commitlog 文件,则禁止删除 DLedger 文件,其具体做法就是禁止强制删除文件,并将文件的有效存储时间设置为 10 年。
- 如果 consumequeue 中存储的最大物理偏移量大于 DLedger 中最大的物理偏移量,则删除多余的 consumequeue 文件。
>温馨提示:为什么当存在 commitlog 文件的情况下,不能删除 DLedger 相关的日志文件呢?
因为在此种情况下,如果 DLedger 中的物理文件有删除,则物理偏移量会断层。 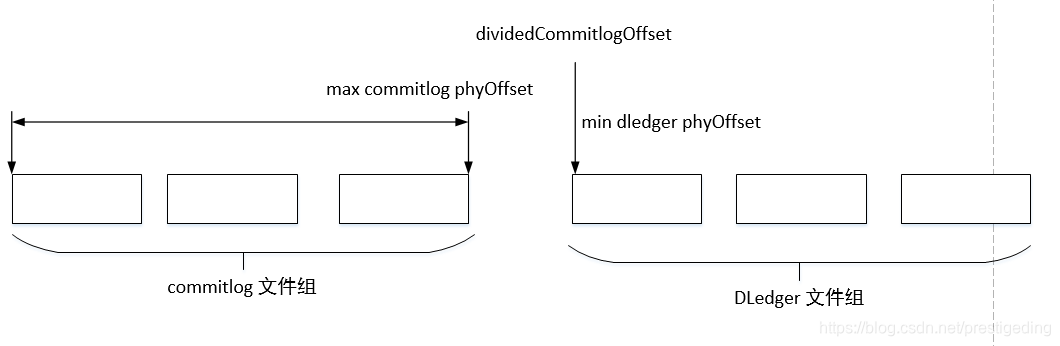
正常情况下, maxCommitlogPhyOffset 与 dividedCommitlogOffset 是连续的,这样非常方便是访问 commitlog 还是 访问 DLedger ,但如果DLedger 部分文件删除后,这两个值就变的不连续,就会造成中间的文件空洞,无法被连续访问。
DLedgerCommitLog#recover
isInrecoveringOldCommitlog = true;
super.recoverNormally(maxPhyOffsetOfConsumeQueue);
isInrecoveringOldCommitlog = false;
Step3:如果启用了 DLedger 并且是初次启动(还未生成 DLedger 相关的日志文件),则需要恢复 旧的 commitlog 文件。
DLedgerCommitLog#recover
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
if (mappedFile == null) { // @1
return;
}
ByteBuffer byteBuffer = mappedFile.sliceByteBuffer();
byteBuffer.position(mappedFile.getWrotePosition());
boolean needWriteMagicCode = true;
// 1 TOTAL SIZE
byteBuffer.getInt(); //size
int magicCode = byteBuffer.getInt();
if (magicCode == CommitLog.BLANK_MAGIC_CODE) { // @2
needWriteMagicCode = false;
} else {
log.info("Recover old commitlog found a illegal magic code={}", magicCode);
}
dLedgerConfig.setEnableDiskForceClean(false);
dividedCommitlogOffset = mappedFile.getFileFromOffset() + mappedFile.getFileSize(); // @3
log.info("Recover old commitlog needWriteMagicCode={} pos={} file={} dividedCommitlogOffset={}", needWriteMagicCode, mappedFile.getFileFromOffset() + mappedFile.getWrotePosition(), mappedFile.getFileName(), dividedCommitlogOffset);
if (needWriteMagicCode) { // @4
byteBuffer.position(mappedFile.getWrotePosition());
byteBuffer.putInt(mappedFile.getFileSize() - mappedFile.getWrotePosition());
byteBuffer.putInt(BLANK_MAGIC_CODE);
mappedFile.flush(0);
}
mappedFile.setWrotePosition(mappedFile.getFileSize()); // @5
mappedFile.setCommittedPosition(mappedFile.getFileSize());
mappedFile.setFlushedPosition(mappedFile.getFileSize());
dLedgerFileList.getLastMappedFile(dividedCommitlogOffset);
log.info("Will set the initial commitlog offset={} for dledger", dividedCommitlogOffset);
}
Step4:如果存在旧的 commitlog 文件,需要将最后的文件剩余部分全部填充,即不再接受新的数据写入,新的数据全部写入到 DLedger 的数据文件中。其关键实现点如下:
- 尝试查找最后一个 commitlog 文件,如果未找到,则结束。
- 从最后一个文件的最后写入点(原 commitlog 文件的 待写入位点)尝试去查找写入的魔数,如果存在魔数并等于 CommitLog.BLANK_MAGIC_CODE,则无需再写入魔数,在升级 DLedger 第一次启动时,魔数为空,故需要写入魔数。
- 初始化 dividedCommitlogOffset ,等于最后一个文件的起始偏移量加上文件的大小,即该指针指向最后一个文件的结束位置。
- 将最后一个 commitlog 未写满的数据全部写入,其方法为 设置消息体的 size 与 魔数即可。
- 设置最后一个文件的 wrotePosition、flushedPosition、committedPosition 为文件的大小,同样有意味者最后一个文件已经写满,下一条消息将写入 DLedger 中。
在启用 DLedger 机制时 Broker 的启动流程就介绍到这里了,相信大家已经了解 DLedger 在整合 RocketMQ 上做的努力,接下来我们从消息追加、消息读取两个方面再来探讨 DLedger 是如何无缝整合 RocketMQ 的,实现平滑升级的。
4、从消息追加看 DLedger 整合 RocketMQ 如何实现无缝兼容
> 温馨提示:本节同样也不会详细介绍整个消息追加(存储流程),只是要点出与 DLedger(多副本、主从切换)相关的核心关键点。如果想详细了解消息追加的流程,可以阅读笔者所著的《RocketMQ技术内幕》一书。
DLedgerCommitLog#putMessage
AppendEntryRequest request = new AppendEntryRequest();
request.setGroup(dLedgerConfig.getGroup());
request.setRemoteId(dLedgerServer.getMemberState().getSelfId());
request.setBody(encodeResult.data);
dledgerFuture = (AppendFuture<appendentryresponse>) dLedgerServer.handleAppend(request);
if (dledgerFuture.getPos() == -1) {
return new PutMessageResult(PutMessageStatus.OS_PAGECACHE_BUSY, new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR));
}
关键点一:消息追加时,则不再写入到原先的 commitlog 文件中,而是调用 DLedgerServer 的 handleAppend 进行消息追加,该方法会有集群内的 Leader 节点负责消息追加以及在消息复制,只有超过集群内的半数节点成功写入消息后,才会返回写入成功。如果追加成功,将会返回本次追加成功后的起始偏移量,即 pos 属性,即类似于 rocketmq 中 commitlog 的偏移量,即物理偏移量。
DLedgerCommitLog#putMessage
long wroteOffset = dledgerFuture.getPos() + DLedgerEntry.BODY_OFFSET;
ByteBuffer buffer = ByteBuffer.allocate(MessageDecoder.MSG_ID_LENGTH);
String msgId = MessageDecoder.createMessageId(buffer, msg.getStoreHostBytes(), wroteOffset);
eclipseTimeInLock = this.defaultMessageStore.getSystemClock().now() - beginTimeInDledgerLock;
appendResult = new AppendMessageResult(AppendMessageStatus.PUT_OK, wroteOffset, encodeResult.data.length, msgId, System.currentTimeMillis(), queueOffset, eclipseTimeInLock);
关键点二:根据 DLedger 的起始偏移量计算真正的消息的物理偏移量,从开头部分得知,DLedger 自身有其存储协议,其 body 字段存储真实的消息,即 commitlog 条目的存储结构,返回给客户端的消息偏移量为 body 字段的开始偏移量,即通过 putMessage 返回的物理偏移量与不使用Dledger 方式返回的物理偏移量的含义是一样的,即从开偏移量开始,可以正确读取消息,这样 DLedger 完美的兼容了 RocketMQ Commitlog。关于 pos 以及 wroteOffset 的图解如下: 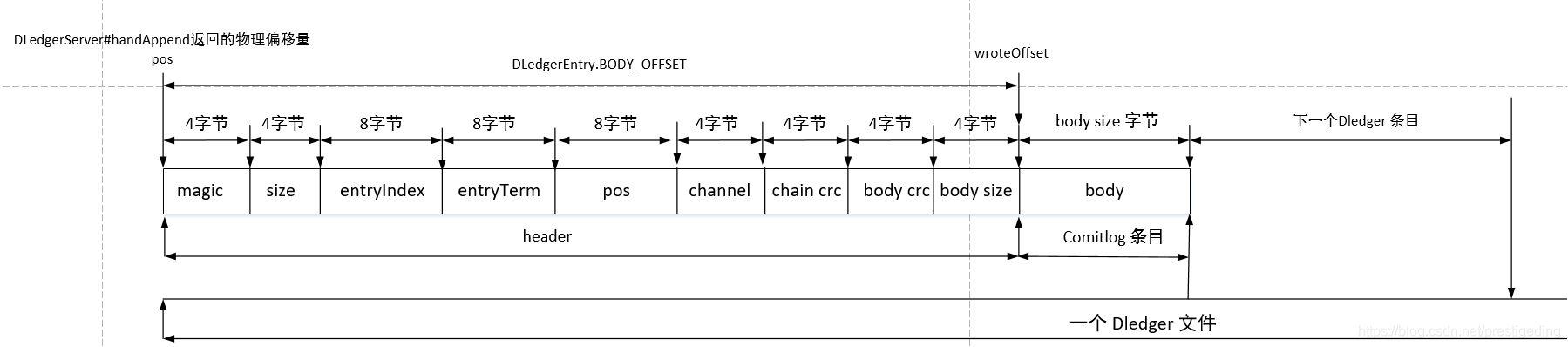
5、从消息读取看 DLedger 整合 RocketMQ 如何实现无缝兼容
DLedgerCommitLog#getMessage
public SelectMappedBufferResult getMessage(final long offset, final int size) {
if (offset < dividedCommitlogOffset) { // @1
return super.getMessage(offset, size);
}
int mappedFileSize = this.dLedgerServer.getdLedgerConfig().getMappedFileSizeForEntryData();
MmapFile mappedFile = this.dLedgerFileList.findMappedFileByOffset(offset, offset == 0); // @2
if (mappedFile != null) {
int pos = (int) (offset % mappedFileSize);
return convertSbr(mappedFile.selectMappedBuffer(pos, size)); // @3
}
return null;
}
消息查找比较简单,因为返回给客户端消息,转发给 consumequeue 的消息物理偏移量并不是 DLedger 条目的偏移量,而是真实消息的起始偏移量。其实现关键点如下:
- 如果查找的物理偏移量小于 dividedCommitlogOffset,则从原先的 commitlog 文件中查找。
- 然后根据物理偏移量按照二分方找到具体的物理文件。
- 对物理偏移量取模,得出在该物理文件中中的绝对偏移量,进行消息查找即可,因为只有知道其物理偏移量,从该处先将消息的长度读取出来,然后即可读出一条完整的消息。
5、总结
根据上面详细的介绍,我想读者朋友们应该不难得出如下结论:
- DLedger 在整合时,使用 DLedger 条目包裹 RocketMQ 中的 commitlog 条目,即在 DLedger 条目的 body 字段来存储整条 commitlog 条目。
- 引入 dividedCommitlogOffset 变量,表示物理偏移量小于该值的消息存在于旧的 commitlog 文件中,实现 升级 DLedger 集群后能访问到旧的数据。
- 新 DLedger 集群启动后,会将最后一个 commitlog 填充,即新的数据不会再写入到 原先的 commitlog 文件。
- 消息追加到 DLedger 数据日志文件中,返回的偏移量不是 DLedger 条目的起始偏移量,而是DLedger 条目中 body 字段的起始偏移量,即真实消息的起始偏移量,保证消息物理偏移量的语义与 RocketMQ Commitlog一样。
RocketMQ 整合 DLedger(多副本)实现平滑升级的设计技巧就介绍到这里了。
如果本文对您有一定的帮助话,麻烦帮忙点个赞,非常感谢。
> 作者简介:《RocketMQ技术内幕》作者,RocketMQ 社区布道师,维护公众号:中间件兴趣圈,重点关注JAVA集合、JAVA并发包、Netty、Dubbo、RocketMQ、Mybatis、Elasticsearch、Netty。可扫描如下二维码与作者进行互动。











