
本文由 网易云 发布。
本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
2.Spark Streaming架构及特性分析
2.1 基本架构
基于是spark core的spark streaming架构。
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数 据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset ) , 然 后 将 Spark Streaming 中 对 DStream 的 Transformation 操 作 变 为 针 对 Spark 中 对 RDD 的 Transformation操作,将RDD经 过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加, 或者存储到外部设备。
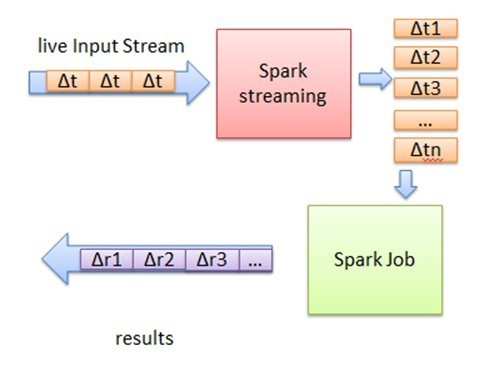
简而言之,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块,Spark Streaming会把每块数据作为一个 RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,然后分批次提交job到集群中去运行,运行每个 job的过程和真正的spark 任务没有任何区别。
JobScheduler
负责job的调度
JobScheduler是SparkStreaming 所有Job调度的中心, JobScheduler的启动会导致ReceiverTracker和JobGenerator的启动。 ReceiverTracker的启动导致运行在Executor端的Receiver启动并且接收数据,ReceiverTracker会记录Receiver接收到的数据 meta信息。JobGenerator的启动导致每隔BatchDuration,就调用DStreamGraph生成RDD Graph,并生成Job。JobScheduler 中的线程池来提交封装的JobSet对象(时间值,Job,数据源的meta)。Job中封装了业务逻辑,导致最后一个RDD的action被触 发,被DAGScheduler真正调度在Spark集群上执行该Job。
JobGenerator
负责Job的生成
通过定时器每隔一段时间根据Dstream的依赖关系生一个一个DAG图。
ReceiverTracker
负责数据的接收,管理和分配
ReceiverTracker在启动Receiver的时候他有ReceiverSupervisor,其实现是ReceiverSupervisorImpl, ReceiverSupervisor本身启 动的时候会启动Receiver,Receiver不断的接收数据,通过BlockGenerator将数据转换成Block。定时器会不断的把Block数据通会不断的把Block数据通过BlockManager或者WAL进行存储,数据存储之后ReceiverSupervisorlmpl会把存储后的数据的元数据Metadate汇报给ReceiverTracker,其实是汇报给ReceiverTracker中的RPC实体ReceiverTrackerEndpoint,主要。
2.2 基于Yarn层面的架构分析
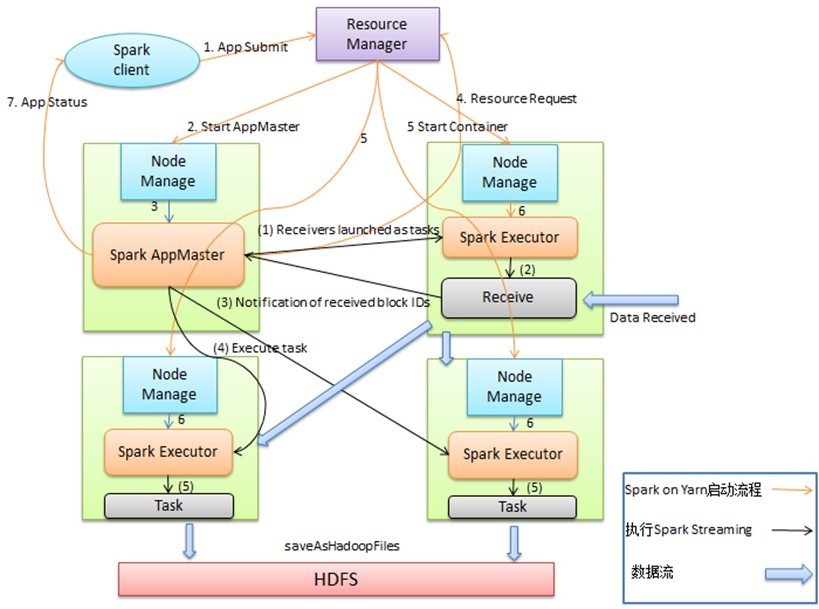
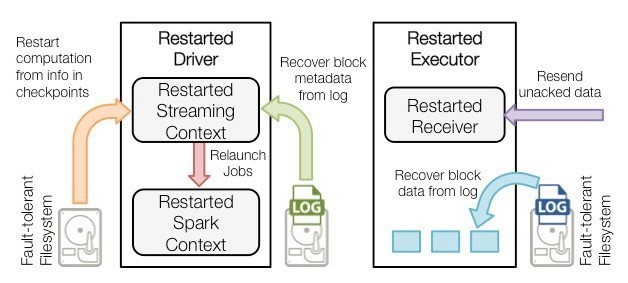
上图为spark on yarn 的cluster模式,Spark on Yarn启动后,由Spark AppMaster中的driver(在AM的里面会启动driver,主要 是StreamingContext对象)把Receiver作为一个Task提交给某一个Spark Executor;Receive启动后输入数据,生成数据块,然 后通知Spark AppMaster;Spark AppMaster会根据数据块生成相应的Job,并把Job的Task提交给空闲Spark Executor 执行。图 中蓝色的粗箭头显示被处理的数据流,输入数据流可以是磁盘、网络和HDFS等,输出可以是HDFS,数据库等。对比Flink和spark streaming的cluster模式可以发现,都是AM里面的组件(Flink是JM,spark streaming是Driver)承载了task的分配和调度,其他 container承载了任务的执行(Flink是TM,spark streaming是Executor),不同的是spark streaming每个批次都要与driver进行 通信来进行重新调度,这样延迟性远低于Flink。
具体实现
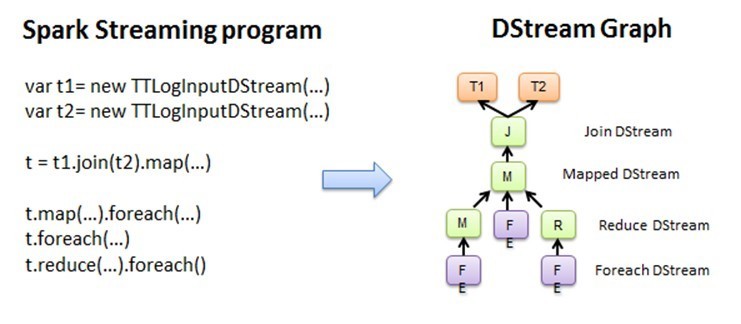
图2.1 Spark Streaming程序转换为DStream Graph
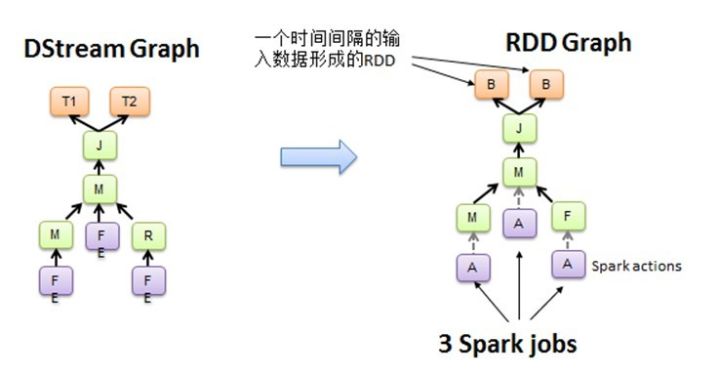
图2.2 DStream Graph转换为RDD的Graph
Spark Core处理的每一步都是基于RDD的,RDD之间有依赖关系。下图中的RDD的DAG显示的是有3个Action,会触发3个job, RDD自下向上依 赖,RDD产生job就会具体的执行。从DSteam Graph中可以看到,DStream的逻辑与RDD基本一致,它就是在 RDD的基础上加上了时间的依赖。RDD的DAG又可以叫空间维度,也就是说整个 Spark Streaming多了一个时间维度,也可以成 为时空维度,使用Spark Streaming编写的程序与编写Spark程序非常相似,在Spark程序中,主要通过操作RDD(Resilient Distributed Datasets弹性分布式数据集)提供的接口,如map、reduce、filter等,实现数据的批处理。而在Spark Streaming 中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。
Spark Streaming把程序中对 DStream的操作转换为DStream Graph,图2.1中,对于每个时间片,DStream Graph都会产生一个RDD Graph;针对每个输出 操作(如print、foreach等),Spark Streaming都会创建一个Spark action;对于每个Spark action,Spark Streaming都会产生 一个相应的Spark job,并交给JobScheduler。JobScheduler中维护着一个Jobs队列, Spark job存储在这个队列中, JobScheduler把Spark job提交给Spark Scheduler,Spark Scheduler负责调度Task到相应的Spark Executor上执行,最后形成 spark的job。
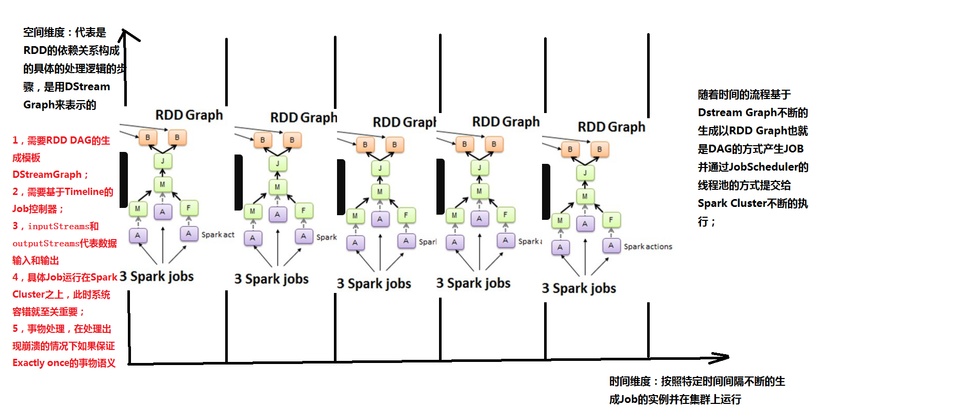
图2.3时间维度生成RDD的DAG
Y轴就是对RDD的操作,RDD的依赖关系构成了整个job的逻辑,而X轴就是时间。随着时间的流逝,固定的时间间隔(Batch Interval)就会生成一个job实例,进而在集群中运行。
代码实现
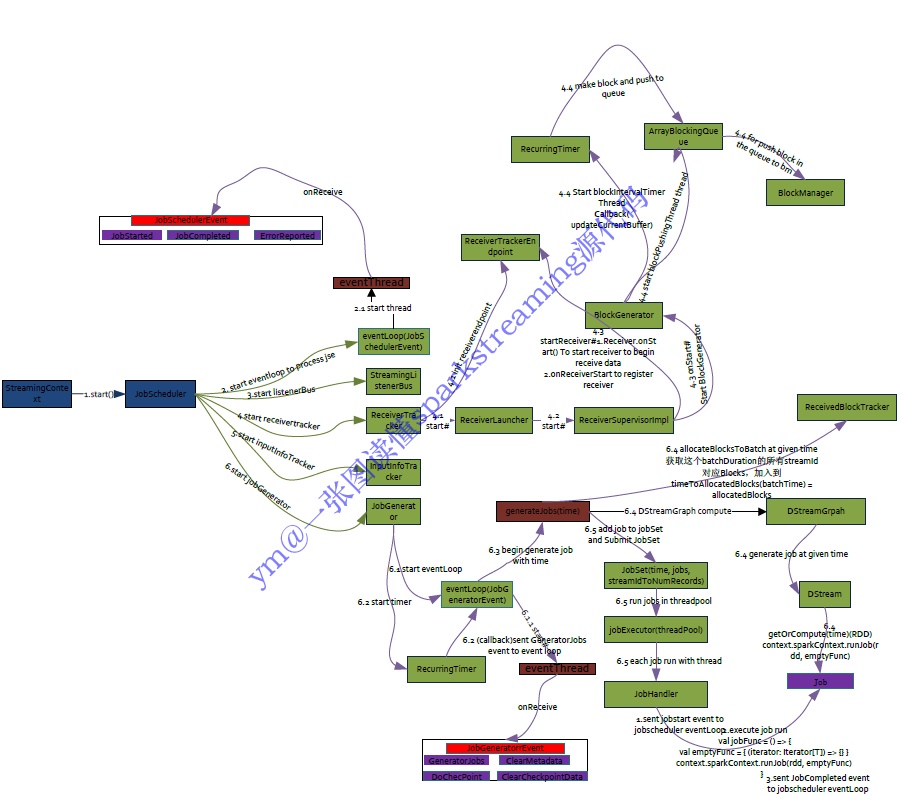
基于spark 1.5的spark streaming源代码解读,基本架构是没怎么变化的。
2.3 组件栈
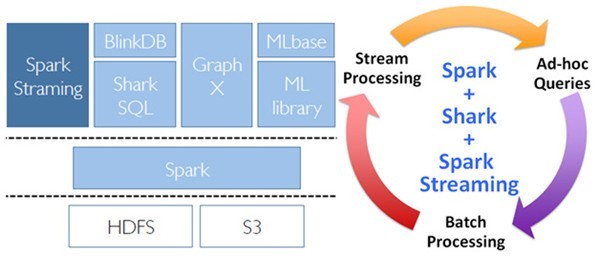
支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以 使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果 存储到文件系统,数据库和现场 仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处 理。
2.4 特性分析
吞吐量与延迟性
Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M records/s),其吞吐量也比流行的Storm高2~5倍,图4是Berkeley利用WordCount和Grep两个用例所做的测试,在 Grep这个 测试中,Spark Streaming中的每个节点的吞吐量是670k records/s,而Storm是115k records/s。
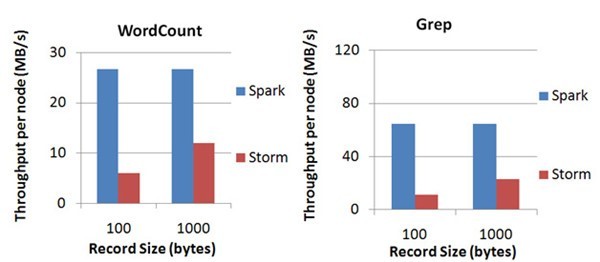
Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解,以及Spark的任务集的调 度过程,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足 除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
exactly-once 语义
更加稳定的exactly-once语义支持。
反压能力的支持
Spark Streaming 从v1.5开始引入反压机制(back-pressure),通过动态控制数据接收速率来适配集群数据处理能力.
Sparkstreaming如何反压?
简单来说,反压机制需要调节系统接受数据速率或处理数据速率,然而系统处理数据的速率是没法简单的调节。因此,只能估计当 前系统处理数据的速率,调节系统接受数据的速率来与之相匹配。
Flink如何反压?
严格来说,Flink无需进行反压,因为系统接收数据的速率和处理数据的速率是自然匹配的。系统接收数据的前提是接收数据的Task 必须有空闲可用的Buffer,该数据被继续处理的前提是下游Task也有空闲可用的Buffer。因此,不存在系统接受了过多的数据,导 致超过了系统处理的能力。
由此看出,Spark的micro-batch模型导致了它需要单独引入反压机制。
反压与高负载
反压通常产生于这样的场景:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。
但是,系统能够承受多高的负载是系统数据处理能力决定的,反压机制并不是提高系统处理数据的能力,而是系统所面临负载高于 承受能力时如何调节系统接收数据的速率。
容错
Driver和executor采用预写日志(WAL)方式去保存状态,同时结合RDD本身的血统的容错机制。
API 和 类库
Spark 2.0中引入了结构化数据流,统一了SQL和Streaming的API,采用DataFrame作为统一入口,能够像编写普通Batch程序或 者直接像操作SQL一样操作Streaming,易于编程。
广泛集成
除了可以读取HDFS, Flume, Kafka, Twitter andZeroMQ数据源以外,我们自己也可以定义数据源,支持运行在Yarn, Standalone及EC2上,能够通过Zookeeper,HDFS保证高可用性,处理结果可以直接写到HDFS
部署性
依赖java环境,只要应用能够加载到spark相关的jar包即可。
3.Storm架构及特性分析
3.1 基本架构
Storm集群采用主从架构方式,主节点是Nimbus,从节点是Supervisor,有关调度相关的信息存储到ZooKeeper集群中。架构如下:
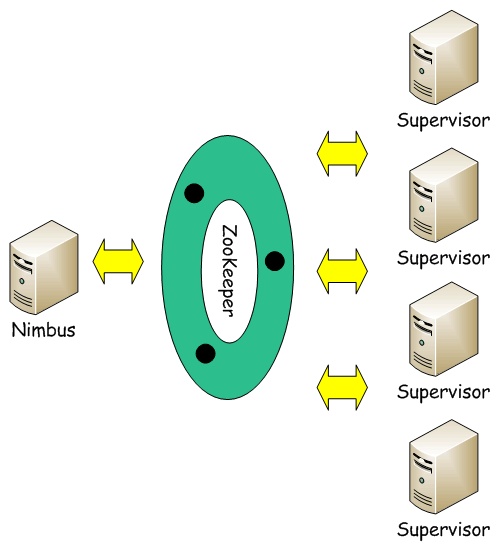
Nimbus
Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件 (Spout/Bolt)的Task。
Supervisor
Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。通过Storm的配置文件中的 supervisor.slots.ports配置项,可以指定在一个Supervisor上最大允许多少个Slot,每个Slot通过端口号来唯一标识,一个端口号 对应一个Worker进程(如果该Worker进程被启动)。
ZooKeeper
用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配 Topology到其它可用的Supervisor上运行。
运行架构
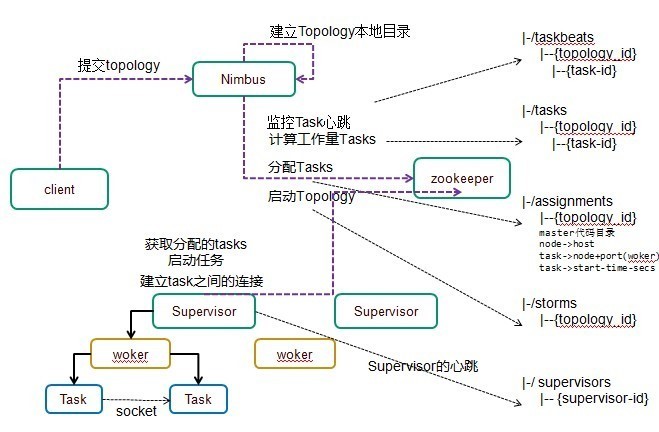
运行流程
1)户端提交拓扑到nimbus。
2) Nimbus针对该拓扑建立本地的目录根据topology的配置计算task,分配task,在zookeeper上建立assignments节点存储 task和supervisor机器节点中woker的对应关系;
在zookeeper上创建taskbeats节点来监控task的心跳;启动topology。
3) Supervisor去zookeeper上获取分配的tasks,启动多个woker进行,每个woker生成task,一个task一个线程;根据topology 信息初始化建立task之间的连接;Task和Task之间是通过zeroMQ管理的;后整个拓扑运行起来。
3.2 基于Yarn层面的架构
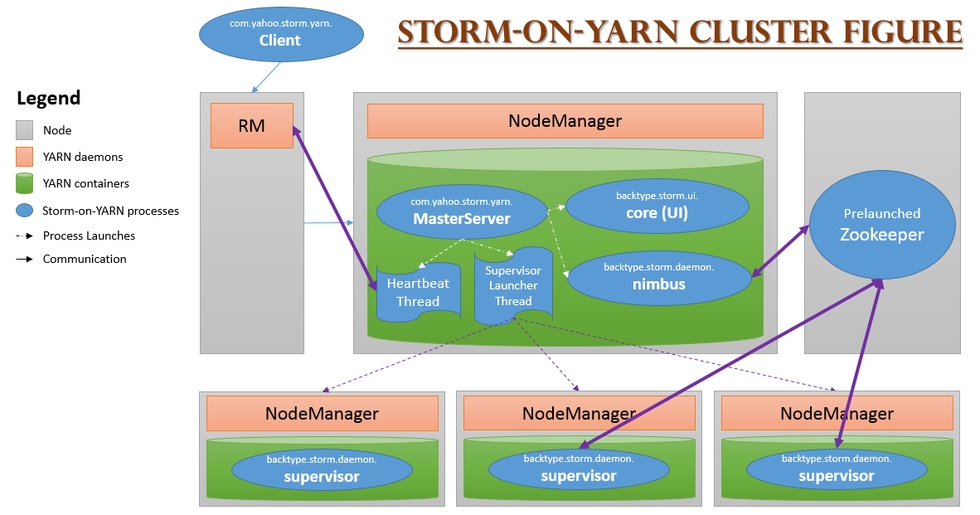
在YARN上开发一个应用程序,通常只需要开发两个组件,分别是客户端和ApplicationMaster,其中客户端主要作用是提交应用程 序到YARN上,并和YARN和ApplicationMaster进行交互,完成用户发送的一些指令;而ApplicationMaster则负责向YARN申请 资源,并与NodeManager通信,启动任务。
不修改任何Storm源代码即可将其运行在YARN之上,最简单的实现方法是将Storm的各个服务组件(包括Nimbus和Supervisor) 作为单独的任务运行在YARN上,而Zookeeper作为一个公共的服务运行在YARN集群之外的几个节点上。
1)通过YARN-Storm Client将Storm Application提交到YARN的RM上;
2)RM为YARN-Storm ApplicationMaster申请资源,并将其运行在一个节点上(Nimbus);
3)YARN-Storm ApplicationMaster 在自己内部启动Nimbus和UI服务;
4)YARN-Storm ApplicationMaster 根据用户配置向RM申请资源,并在申请到的Container中启动Supervisor服务;
3.3 组件栈
3.4 特性分析
简单的编程模型。
类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性。
服务化
一个服务框架,支持热部署,即时上线或下线App.
可以使用各种编程语言
你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单 的Storm通信协议即可。
容错性
Storm会管理工作进程和节点的故障。
水平扩展
计算是在多个线程、进程和服务器之间并行进行的。
可靠的消息处理
Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
快速
系统的设计保证了消息能得到快速的处理,使用ZeroMQ作为其底层消息队列。
本地模式
Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
部署性
依赖于Zookeeper进行任务状态的维护,必须首先部署Zookeeper。
4.三种框架的对比分析
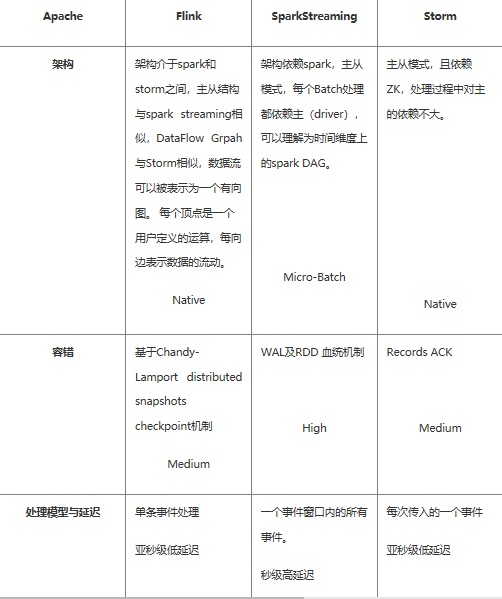
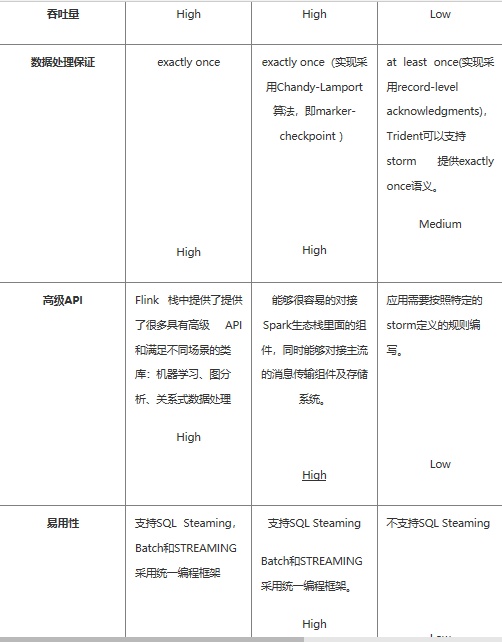
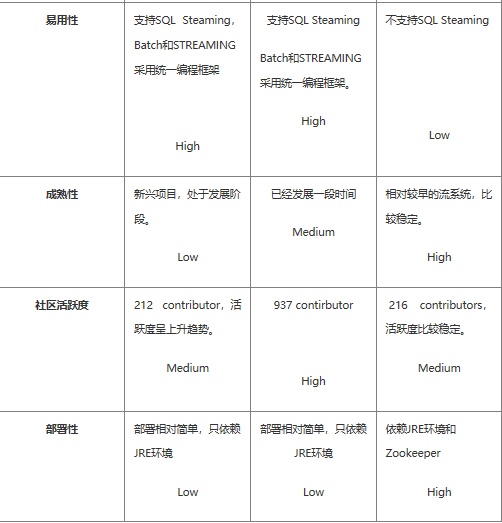
对比分析
如果对延迟要求不高的情况下,建议使用Spark Streaming,丰富的高级API,使用简单,天然对接Spark生态栈中的其他组 件,吞吐量大,部署简单,UI界面也做的更加智能,社区活跃度较高,有问题响应速度也是比较快的,比较适合做流式的ETL,而 且Spark的发展势头也是有目共睹的,相信未来性能和功能将会更加完善。
如果对延迟性要求比较高的话,建议可以尝试下Flink,Flink是目前发展比较火的一个流系统,采用原生的流处理系统,保证了低延迟性,在API和容错性上也是做的比较完善,使用起来相对来说也是比较简单的,部署容易,而且发展势头也越来越好,相信后面社区问题的响应速度应该也是比较快的。
个人对Flink是比较看好的,因为原生的流处理理念,在保证了低延迟的前提下,性能还是比较好的,且越来越易用,社区也在不断 发展。
网易有数:企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。可点击这里免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/











