
本文为大家带来几个非常实用的编程原则并附案例,让你一次学会应对编程中的问题,在你的晋升路上越走越顺。

一、编程的世界里十面埋伏
编程,是一件容易的事,也是一件不容易的事。说它容易,是因为掌握一些基本的数据类型和条件语句,就可以实现复杂的逻辑;说它不容易,是因为高性能高可用的代码,需要了解的知识有很多很多;编程的世界,也跟扫雷游戏的世界一样,充满雷区,十面埋伏,一不小心,随时都可能踩雷,随时都可能Game Over。
而玩过扫雷的人都知道,避免踩雷的最好方法,就是提前识别雷区并做标记(设防)避免踩踏。
鉴于此,编程的世界里,从输入到输出同样需要处处设防,步步为营。
1、对输入的不信任
(1)对空指针的检查
不只是输入,只有是使用到指针的地方,都应该先判断指针是否为NULL,而内存释放后,应当将指针设置为NULL。
【真实案例】:注册系统某段逻辑,正常使用情况下,都有对指针做检查,在某个错误分支,打印日志时,没检查就使用了该字符串;结果可正常运行,但当访问某个依赖模块超时走到改分支,触发bug,导致coredump。
(2)对数据长度的检查
使用字符串或某段buf,特别是memcpy/strcpy时,需要尽量对数据长度做下检查和截断。
【真实案例】:接手oauth系统后运行数月表现良好,突然有一天,发生了coredump,经查,是某个业务不按规定请求包中填写了超长长度,导致memcpy时发生段错误,根本原因,还是没有做好长度检查。
(3)对数据内容的检查
某些场景下,没有对数据内容做检查就直接使用,可能导致意想不到的结果。
【案例】:sql注入和xss攻击都是利用了服务端没有对数据内容做检查的漏洞。
2、对输出(变更)的不信任
变更的影响一般体现在输出,有时候输出的结果并不能简单的判断是否正常,如输出是加密信息,或者输出的内容过于复杂。
所以,对于每次变更
(1)修改代码时,采用不信任编码,正确的不一定是“对”的,再小的修改也应确认其对后续逻辑的影响,有些修正可能改变原来错误时的输出,而输出的改变,就会影响到依赖该改变字段的业务。
(2)发布前,应该对涉及到的场景进行测试和验证,测试可以有效的发现潜在的问题,这是众所周知的。
(3)发布过程,应该采用灰度发布策略,因为测试并非总是能发现问题,灰度发布,可以减少事故影响的范围。常见灰度发布的策略有机器灰度、IP灰度、用户灰度、按比例灰度等,各有优缺点,需要根据具体场景选择,甚至可以同时采用多种的组合。
(4)发布后,全面监控是有效发现问题的一种方法。因为测试环境和正式环境可能存在不一致的地方,也可能测试不够完整,导致上线后有问题,所以需采取措施补救。
A:如使用Monitor监控请求量、成功量、失败量、关键节点等
B:使用DLP告警监控成功率
C:发布完,在正式环境测试一遍
【案例】oauth系统某次修改后编译时,发现有个修改不相关的局部变量未初始化的告警,出于习惯对变量进行了初始化(初始化值和编译器默认赋值不一样),而包头某个字段采用了该未初始化的变量,但在测试用例中未能体现,监控也没细化到每个字段的值,导致测试正常,监控正常;但前端业务齐齐互动使用了该包头字段,导致发布后影响该业务。
二、服务程序的世界里防不胜防
一般的系统,都会有上下游的存在,正如下图所示
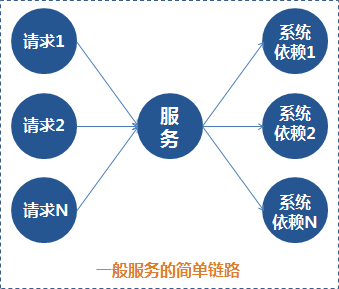
而上下游的整个链路中,每个点都是不能保证绝对可靠的,任何一个点都可能随时发生故障,让你措手不及。
因此,不能信任整个链路中的任何一个点,需进行设防。
1、对服务本身的不信任
主要措施如下:
(1)服务监控
前面所述的请求量、成功量、失败量、关键节点、成功率的监控,都是对服务环节的单点监控。
在此基础上,可以加上自动化测试,自动化测试可以模拟应用场景,实现对于流程的监控。
(2)进程秒起
人可能在程序世界里是不可靠的因素(大牛除外),前面的措施,多是依赖人来保证的;所以,coredump还是有可能发生的,这时,进程秒起的实现,就可以有效减少coredump的影响,继续对外提供服务。
2、对依赖系统的不信任
可采用柔性可用策略,对于根据模块的不可或缺性,区分关键路径和非关键路径,并采取不同的策略。
(1)对于非关键路径,采用柔性放过策略
当访问非关键路径超时时,简单的可采取有限制(一定数量、一定比重)的重试,结果超时则跳过该逻辑,进行下一步;复杂一点的统计一下超时的比例,当比例过高时,则跳过该逻辑,进行下一步。
(2)对于关键路径,提供弱化服务的柔性策略
关键路径是不可或缺的服务,不能跳过;某些场景,可以根据目的,在关键路径严重不可用时,提供弱化版的服务。举例如派票系统访问票据存储信息严重不可用时,可提供不依赖于存储的纯算法票据,为弥补安全性的确实,可采取缩短票据有效期等措施。
3、对请求的不信任
(1)对请求来源的不信任
有利可图的地方,就会有黑产时刻盯着,伪造各种请求,对此,可采取如下措施:
A:权限控制
如ip鉴权、模块鉴权、白名单、用户登录态校验等
B:安全审计
权限控制仅能打击一下非正常流程的请求,但坏人经常能够成功模拟用户正常使用的场景;所以,对于一些重要场景,需要加入安全策略,打击如IP、号码等信息聚集,频率过快等机器行为,请求重放、劫持等请求)
(2)对请求量的不信任
前端的请求,不总是平稳的;有活动时,会暴涨;前端业务故障恢复后,也可能暴涨;前端遭到恶意攻击时,也可能暴涨;一旦请求量超过系统负载,将会发生雪崩,最终导致整个服务不可用,对此种种突发情况,后端服务需要有应对措施。
A:频率限制,控制各个业务的最大请求量(业务根据正常请求峰值的2-3倍申请,该值可修改),避免因一个业务暴涨影响所有业务的情况发生。
B:过载保护,虽然有频率限制,但业务过多时,依然有可能某个时间点,所有的请求超过了系统负载,或者到某个IDC,某台机器的请求超过负载,为避免这种情况下发生雪崩,将超过一定时间的请求丢弃,仅处理部分有效的请求,使得系统对外表现为部分可用,而非完全不可用。
三、运营的世界里不可预测
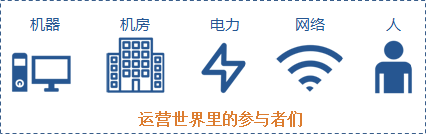
1、对机器的不信任
机器故障时有发生,如果服务存在单点问题,故障时,则服务将完全不可用,而依赖人工的恢复是不可预期的,对此,可通过以下措施解决。
(1)容灾部署
即至少有两台以上的机器可以随时对外提供服务。
(2)心跳探测
用于监控机器是否可用,当机器不可用时,若涉及到主备机器的,应做好主备机器的自动切换;若不涉及到主备的,禁用故障机器对外提供服务即可。
2、对机房的不信任
现实生活中,整个机房不可用也是有发生过的,如2015年的天津滨海新区爆炸事故,导致腾讯在天津的多个机房不能对外提供正常服务,对此采取的措施有:
(1)异地部署
不同IDC、不同城市、不同国家等部署,可用避免整个机房不可用时,有其他机房的机器可以对外提供服务。
(2)容量冗余
对于类似QQ登陆这种入口型的系统,必须保持两倍以上的冗余;如此,可以保证当有一个机房故障时,所有请求迁移到其他机房不会引发系统过载。
3、对电力的不信任
虽然我们越来越离不开电力,但电力却不能保证一直在为我们提供服务。断电时,其影响和机器故障、机房故障类似,机器会关机,数据会丢失,所以,需要对数据进行备份。
(1)磁盘备份
来电后,机器重启,可以从磁盘中恢复数据,但可能会有部分数据丢失。
(2)远程备份
机器磁盘坏了,磁盘的数据会丢失,使用对于重要系统,相关数据应当考虑采用远程备份。
4、对网络的不信任
(1)不同地方,网络时延不一样
一般来说,本地就近的机器,时延要好于异地的机器, 所以,比较简单的做法就是近寻址,如CMLB。
也有部分情况,是异地服务的时延要好于本地服务的时延,所以,如果要做到较好的最优路径寻址,就需要先做网络探测,如Q调。
(2)常有网络有波动或不可用情况
和机器故障一样处理,应当做到自动禁用;但网络故障和机器故障又不一样,经常存在某台机器不可用,但别的机器可以访问的情况,这时就不能在服务端禁用机器了,而应当采用本地回包统计策略,自动禁用服务差机器;同时需配合定时探测禁用机器策略,自动恢复可正常提供服务机器。
5、对人的不信任
人的因素在运营的世界里其实是不稳定的因素(大牛除外),所以,不能对人的操作有过多的信任。
(1)操作备份
每一步操作都有记录,便于发生问题时的回溯,重要的操作需要review,避免个人考虑不周导致事故。
(2)效果确认
实际环境往往和测试环境是存在一些差异,所有在正式环境做变更后,应通过视图review和验证来确认是否符合预期。
(3)变更可回滚
操作前需对旧程序、旧配置等做好备份,以便发生故障时,及时恢复服务。
(4)自动化部署
机器的部署,可能有一堆复杂的流程,如各种权限申请,各种客户端安装等,仅靠文档流程操作加上测试验证时不够的,可能某次部署漏了某个步骤而测试又没测到,上线后就可能发生事故若能所有流程实现自动化,则可有效避免这类问题。
(5)一致性检查
现网的发布可能因某个节点没同步导致漏发,也就是不同的机器服务不一样;对此,有版本号的,可通过版本号监控发现;没版本号的,则需借助进程、配置等的一致性检查来发现问题。
备注:以上提到的不信任策略,有的不能简单的单条使用,需要结合其他的措施一起使用的。
本文分享自微信公众号 - IT技术分享社区(gh_a27c0758eb03)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













