
我在这里面给个非官方的定义吧。当一个集群的不同部分在同一时间都认为自己是活动的时候,我们就可以将这个现象称为脑裂症状。我们当如何理解这句话呢?
首先我们需要是个集群。
其次当中有业务是Master-Backup模式或双星模式。也就是说当主节点挂掉了,备用节点需要接管业务或者是两个节点直接有数据同步。
让我们举个例子(图片来自https://blog.process-one.net/angie_introducing_flexarch/):
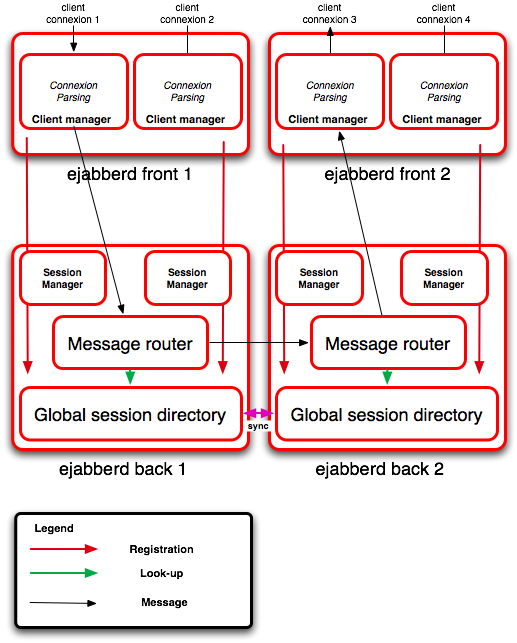
其中ejabberd front是不存在Router的,只有Client Manager。而ejabberd back是具有Message router 的。那么我们可以将这个图简单的抽象为这样的:
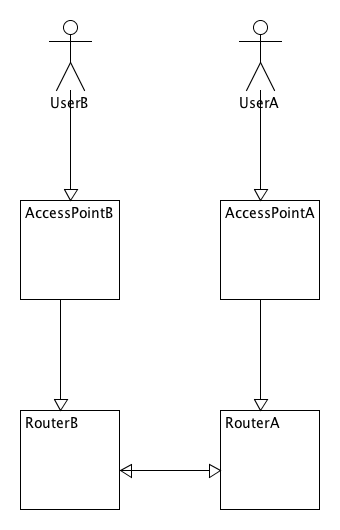
UserA和UserB分别将自己的信息注册在RouterA和RouterB中。RouterA和RouterB使用数据同步(2PC),来同步信息。那么当UserA想要向UserB发送一个消息的时候,需要现在RouterA中查询出UserA到UserB的消息路由路径,然后再交付给相应的路径进行路由。
当脑裂发生的时候,相当RouterA和RouterB直接的联系丢失了,RouterA认为整个系统中只有它一个Router,RouterB也是这样认为的。那么相当于RouterA中没有UserB的信息,RouterB中没有UserA的信息了,此时UserA再发送消息给UserB的时候,RouterA会认为UserB已经离线了,然后将该信息进行离线持久化。
说到这里面估计大家已经明白了脑裂是什么东西了。
怎么解决 paxos算法,使用奇数性质的节点来进行表决,必须选出一个说的算的老大,这个集群才能正常工作。
双星模式下,使用专线直连,从硬件上保障。
使用额外的探测节点,当双方直连断开之后,使用一个约定好的共同节点来探测是否是直连故障。
当两(多)个节点同时认为自已是唯一处于活动状态的服务器从而出现争用资源的情况,这种争用资源的场景即是所谓的“脑裂”(split-brain)或”区间集群“(partitioned cluster)。
HeartBeat原理: HeartBeat运行于备用主机上的Heartbeat可以通过以太网连接检测主服务器的运行状态,一旦其无法检测到主服务器的"心跳"则自动接管主服务器的资源。通常情况下,主、备服务器间的心跳连接是一个独立的物理连接,这个连接可以是串行线缆、一个由"交叉线"实现的以太网连接。Heartbeat甚至可同时通过多个物理连接检测主服务器的工作状态,而其只要能通过其中一个连接收到主服务器处于活动状态的信息,就会认为主服务器处于正常状态。从实践经验的角度来说,建议为Heartbeat配置多条独立的物理连接,以避免Heartbeat通信线路本身存在单点故障。











