尽管抄袭傍身,也没能阻挡《爱情公寓5》进击的脚步。
最近爱情公寓电视剧微博发布了长达8分钟的揭幕视频,官宣新季将在2020正式开播。
几位主演纷纷转发宣传,将#爱情公寓5揭幕#的话题送上了热搜。
观众在经历过一次《爱情公墓》的诈骗后,能否接受《爱情公寓5》(下文简称爱5)?
让我们来分析一下。
获取数据
首先,我选取了在B站上最热的视频,目前已经179万播放量,2万弹幕。
为什么选择B站呢?
著名UP主“残狼之卑”,曾经在b站上传了几十个对比视频,做成《爱情公寓的抄袭史》,每期视频播放量都几十万,所以按理来说B站的用户反对爱情公寓的人应该很多。
如果B站的用户都可以接受,那么《爱5》可能真的会取得不错的播放量。
B站的弹幕数据是有接口的,比如说:
https://comment.bilibili.com/\*\*\*\*\*\*\*\*.xml
它以一个固定的url地址+视频的cid+.xml组成。只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了。
以刚才的视频为例
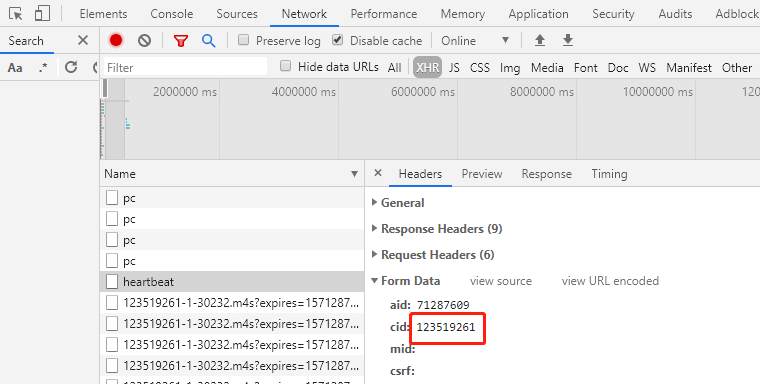
它的cid就是123519261,构成url就是:
https://comment.bilibili.com/123519261.xml
下载并打开这个XML格式的弹幕文件。
观察上图,所有的弹幕都放在了
那么我们写段爬虫:
from bs4 import BeautifulSoup
import pandas as pd
import requests
url = 'http://comment.bilibili.com/123519261.xml'
html = requests.get(url)
html.encoding='utf8'
soup = BeautifulSoup(html.text, 'lxml')
results = soup.find_all('d')
comments = [comment.text for comment in results]
comments_dict = {'comments': comments}
df = pd.DataFrame(comments_dict)
df.to_csv('bili_ai5.csv', encoding='utf-8-sig')最后成功获取1000条弹幕数据。
(b站给出的字幕限制是1000条)

数据分析

在弹幕中看到很多人提及“大二了”,“从小学5年级开始看”,我们来看一下学生阶段在弹幕中的提及数。
#学生阶段在弹幕中的提及数
a = {'小学':'小学|一年级|二年级|三年级|四年级|五年级|六年级',
'初中':'初中|初一|初二|初三',
'高一':'高一',
'高二':'高二',
'高三':'高三',
'大一':'大一',
'大二':'大二',
'大三':'大三',
'大四':'大四',}
for key, value in a.items():
data[key] = data['comments'].str.contains(value)
staff_count = pd.Series({key: data.loc[data[key], 'comments'].count() for key in a.keys()}).sort_values()
print(staff_count)

1000条弹幕就包含了这么多关于年龄的怀念。
数据可视化
我们将爬取得到的弹幕做个词云,更加直观地展示。
import jieba
from collections import Counter
from pyecharts import WordCloud
stop_words = [x.strip() for x in open ('stopwords.txt',encoding="utf-8") ]
text = ''.join(data['comments'])
words = list(jieba.cut(text))
ex_sw_words = []
for word in words:
if len(word)>1 and (word not in stop_words):
ex_sw_words.append(word)
c = Counter()
c = Counter(ex_sw_words)
wc_data = pd.DataFrame({'word':list(c.keys()), 'counts':list(c.values())}).sort_values(by='counts', ascending=False).head(100)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", wc_data['word'], wc_data['counts'], word_size_range=[15, 80])

词云图上,可以看到《爱情公寓》依旧是一代人快乐的回忆,即便是电影导致IP口碑全面崩盘,但粉丝好感似乎用之不尽。即便有人提到抄袭借鉴之类的,也会被说“黑粉gun开”。
通过这次B站弹幕的爬取分析,我现在可以肯定的是《爱5》依然会有很多人看。只要片方挥舞着“十年怀旧,挥别青春”的大旗便会无往不利,这也是他们的底气所在。
其实我理解大家只是想要一个结局。
但《爱5》过后。
没有演技的演员重新找路。
靠着怀旧的片方盆丰钵满。
这是我们想要的结局吗?
朱小五,某互联网公司数据分析师,热衷于爬虫,数据分析,可视化,个人公众号《凹凸玩数据》
本文相关代码已上传github:
https://github.com/zpw1995/aotodata/tree/master/bilibili\_danmu

本文转转自微信公众号凹凸数据原创https://mp.weixin.qq.com/s/2XcJHhsIMLPyKvlqIYxeVg,可扫描二维码进行关注:
 如有侵权,请联系删除。
如有侵权,请联系删除。