十年前,谷歌发表了 “BigTable” 的论文,论文中很多很酷的方面之一就是它所使用的文件组织方式,这个方法更一般的名字叫 Log Structured-Merge Tree。
LSM是当前被用在许多产品的文件结构策略:HBase, Cassandra, LevelDB, SQLite,甚至在mangodb3.0中也带了一个可选的LSM引擎(Wired Tiger 实现的)。
LSM 有趣的地方是他抛弃了大多数数据库所使用的传统文件组织方法,实际上,当你第一次看它是违反直觉的。
背景知识
简单的说,LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。
那么为什么这是一个好的方法呢?这个问题的本质还是磁盘随机操作慢,顺序读写快的老问题。这二种操作存在巨大的差距,无论是磁盘还是SSD。
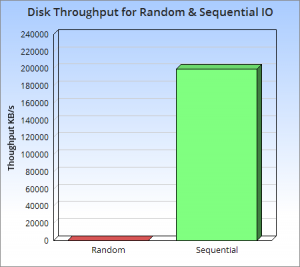
上图很好的说明了这一点,他们展现了一些反直觉的事实,顺序读写磁盘(不管是SATA还是SSD)快于随机读写主存,而且快至少三个数量级。这说明我们要避免随机读写,最好设计成顺序读写。
所以,让我们想想,如果我们对写操作的吞吐量敏感,我们最好怎么做?一个好的办法是简单的将数据添加到文件。这个策略经常被使用在日志或者堆文件,因为他们是完全顺序的,所以可以提供非常好的写操作性能,大约等于磁盘的理论速度,也就是200~300 MB/s。
因为简单和高效,基于日志的策略在大数据之间越来越流行,同时他们也有一些缺点,从日志文件中读一些数据将会比写操作需要更多的时间,需要倒序扫描,直接找到所需的内容。
这说明日志仅仅适用于一些简单的场景:1. 数据是被整体访问,像大部分数据库的WAL(write-ahead log) 2. 知道明确的offset,比如在Kafka中。
所以,我们需要更多的日志来为更复杂的读场景(比如按key或者range)提供高效的性能,这儿有4个方法可以完成这个,它们分别是:
- 二分查找: 将文件数据有序保存,使用二分查找来完成特定key的查找。
- 哈希:用哈希将数据分割为不同的bucket
- B+树:使用B+树 或者 ISAM 等方法,可以减少外部文件的读取
- 外部文件: 将数据保存为日志,并创建一个hash或者查找树映射相应的文件。
所有的方法都可以有效的提高了读操作的性能(最少提供了O(log(n)) ),但是,却丢失了日志文件超好的写性能。上面这些方法,都强加了总体的结构信息在数据上,数据被按照特定的方式放置,所以可以很快的找到特定的数据,但是却对写操作不友善,让写操作性能下降。
更糟糕的是,当我们需要更新hash或者B+树的结构时,需要同时更新文件系统中特定的部分,这就是上面说的比较慢的随机读写操作。这种随机的操作要尽量减少。
所以这就是 LSM 被发明的原理, LSM 使用一种不同于上述四种的方法,保持了日志文件写性能,以及微小的读操作性能损失。本质上就是让所有的操作顺序化,而不是像散弹枪一样随机读写。
很多树结构可以不用 update-in-place,最流行就是 append-only Btree,也称为 Copy-On-Write Tree。他们通过顺序的在文件末尾重复写对结构来实现写操作,之前的树结构的相关部分,包括最顶层结点都会变成孤结点。尽管通过这种方法避免了本地更新,但是因为每个写操作都要重写树结构,放大了写操作,降低了写性能。
The Base LSM Algorithm
从概念上说,最基本的LSM是很简单的 。将之前使用一个大的查找结构(造成随机读写,影响写性能),变换为将写操作顺序的保存到一些相似的有序文件(也就是sstable)中。所以每个文件包 含短时间内的一些改动。因为文件是有序的,所以之后查找也会很快。文件是不可修改的,他们永远不会被更新,新的更新操作只会写到新的文件中。读操作检查很 有的文件。通过周期性的合并这些文件来减少文件个数。

让我们更具体的看看,当一些更新操作到达时,他们会被写到内存缓存(也就是memtable)中,memtable使用树结构来保持key的有序,在大部 分的实现中,memtable会通过写WAL的方式备份到磁盘,用来恢复数据,防止数据丢失。当memtable数据达到一定规模时会被刷新到磁盘上的一 个新文件,重要的是系统只做了顺序磁盘读写,因为没有文件被编辑,新的内容或者修改只用简单的生成新的文件。
所以越多的数据存储到系统中,就会有越多的不可修改的,顺序的sstable文件被创建,它们代表了小的,按时间顺序的修改。
因为比较旧的文件不会被更新,重复的纪录只会通过创建新的纪录来覆盖,这也就产生了一些冗余的数据。
所以系统会周期的执行合并操作(compaction)。 合并操作选择一些文件,并把他们合并到一起,移除重复的更新或者删除纪录,同时也会删除上述的冗余。更重要的是,通过减少文件个数的增长,保证读操作的性 能。因为sstable文件都是有序结构的,所以合并操作也是非常高效的。
当一个读操作请求时,系统首先检查内存数据(memtable),如果没有找到这个key,就会逆序的一个一个检查sstable文件,直到key 被找到。因为每个sstable都是有序的,所以查找比较高效(O(logN)),但是读操作会变的越来越慢随着sstable的个数增加,因为每一个 sstable都要被检查。(O(K log N), K为sstable个数, N 为sstable平均大小)。
所以,读操作比其它本地更新的结构慢,幸运的是,有一些技巧可以提高性能。最基本的的方法就是页缓存(也就是leveldb的 TableCache,将sstable按照LRU缓存在内存中)在内存中,减少二分查找的消耗。LevelDB 和 BigTable 是将 block-index 保存在文件尾部,这样查找就只要一次IO操作,如果block-index在内存中。一些其它的系统则实现了更复杂的索引方法。
即使有每个文件的索引,随着文件个数增多,读操作仍然很慢。通过周期的合并文件,来保持文件的个数,因些读操作的性能在可接收的范围内。即便有了合 并操作,读操作仍然会访问大量的文件,大部分的实现通过布隆过滤器来避免大量的读文件操作,布隆过滤器是一种高效的方法来判断一个sstable中是否包 含一个特定的key。(如果bloom说一个key不存在,就一定不存在,而当bloom说一个文件存在是,可能是不存在的,只是通过概率来保证)
所有的写操作都被分批处理,只写到顺序块上。另外,合并操作的周期操作会对IO有影响,读操作有可能会访问大量的文件(散乱的读)。这简化了算法工 作的方法,我们交换了读和写的随机IO。这种折衷很有意义,我们可以通过软件实现的技巧像布隆过滤器或者硬件(大文件cache)来优化读性能。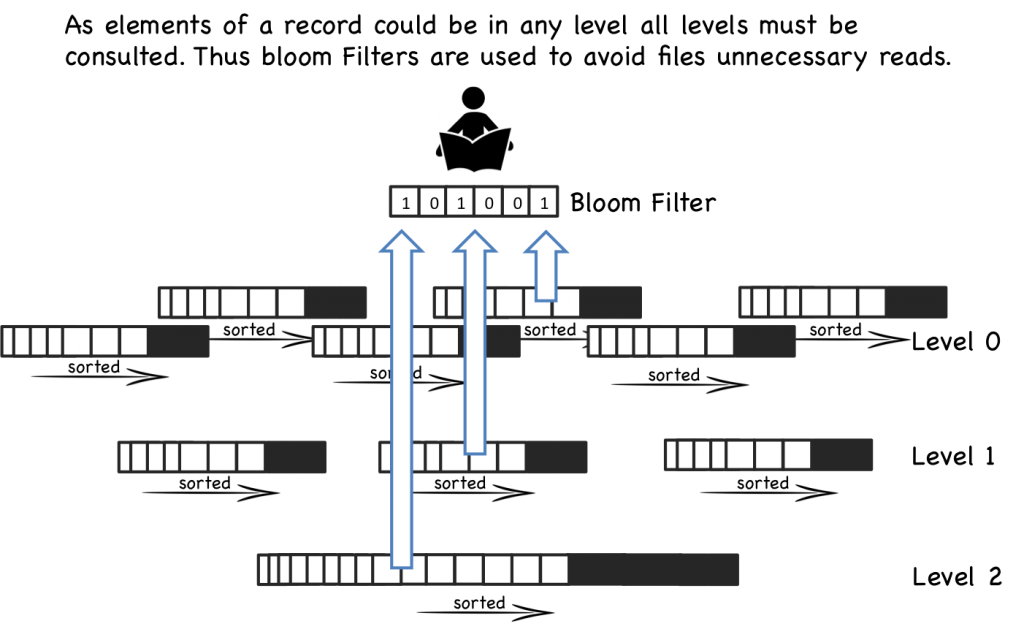
Basic Compaction
为了保持LSM的读操作相对较快,维护并减少sstable文件的个数是很重要的,所以让我们更深入的看一下合并操作。这个过程有一点儿像一般垃圾回收算法。
当一定数量的sstable文件被创建,例如有5个sstable,每一个有10行,他们被合并为一个50行的文件(或者更少的行数)。这个过程一 直持续着,当更多的有10行的sstable文件被创建,当产生5个文件时,它们就被合并到50行的文件。最终会有5个50行的文件,这时会将这5个50 行的文件合并成一个250行的文件。这个过程不停的创建更大的文件。像下图:
上述的方案有一个问题,就是大量的文件被创建,在最坏的情况下,所有的文件都要搜索。
Levelled Compaction
更新的实现,像 LevelDB 和 Cassandra解决这个问题的方法是:实现了一个分层的,而不是根据文件大小来执行合并操作。这个方法可以减少在最坏情况下需要检索的文件个数,同时也减少了一次合并操作的影响。
按层合并的策略相对于上述的按文件大小合并的策略有二个关键的不同:
- 每一层可以维护指定的文件个数,同时保证不让key重叠。也就是说把key分区到不同的文件。因此在一层查找一个key,只用查找一个文件。第一层是特殊情况,不满足上述条件,key可以分布在多个文件中。
- 每次,文件只会被合并到上一层的一个文件。当一层的文件数满足特定个数时,一个文件会被选出并合并到上一层。这明显不同与另一种合并方式:一些相近大小的文件被合并为一个大文件。
这些改变表明按层合并的策略减小了合并操作的影响,同时减少了空间需求。除此之外,它也有更好的读性能。但是对于大多数场景,总体的IO次数变的更多,一些更简单的写场景不适用。
总结
所以, LSM 是日志和传统的单文件索引(B+ tree,Hash Index)的中立,他提供一个机制来管理更小的独立的索引文件(sstable)。
通过管理一组索引文件而不是单一的索引文件,LSM 将B+树等结构昂贵的随机IO变的更快,而代价就是读操作要处理大量的索引文件(sstable)而不是一个,另外还是一些IO被合并操作消耗。
如果还有不明白的,这还有一些其它的好的介绍。 here and here
关于 LSM 的一些思考
为什么 LSM 会比传统单个树结构有更好的性能?
我们看到LSM有更好的写性能,同时LSM还有其它一些好处。 sstable文件是不可修改的,这让对他们的锁操作非常简单。一般来说,唯一的竞争资源就是 memtable,相对来说需要相对复杂的锁机制来管理在不同的级别。
所以最后的问题很可能是以写为导向的压力预期如何。如果你对LSM带来的写性能的提高很敏感,这将会很重要。大型互联网企业似乎很看中这个问题。 Yahoo 提出因为事件日志的增加和手机数据的增加,工作场景为从 read-heavy 到 read-write。。许多传统数据库产品似乎更青睐读优化文件结构。
因为可用的内存的增加,通过操作系统提供的大文件缓存,读操作自然会被优化。写性能(内存不可提高)因此变成了主要的关注点,所以采取其它的方法,硬件提升为读性能做的更多,相对于写来说。因此选择一个写优化的文件结构很有意义。
理所当然的,LSM的实现,像LevelDB和Cassandra提供了更好的写性能,相对于单树结构的策略。
Beyond Levelled LSM
这有更多的工作在LSM上, Yahoo开发了一个系统叫作 Pnuts, 组合了LSM与B树,提供了更好的性能。我没有看到这个算法的开放的实现。 IBM和Google也实现了这个算法。也有相关的策略通过相似的属性,但是是通过维护一个拱形的结构。如 Fractal Trees, Stratified Trees.
这当然是一个选择,数据库利用大量的配置,越来越多的数据库为不同的工作场景提供插件式引擎。 Parquet 是一个流行的HDFS的替代,在很多相对的文面做的好很(通过一个列格式提高性能)。MySQL有一个存储抽象,支持大量的存储引擎的插件,例如 Toku (使用 fractal tree based index)。
Mongo3.0 则包含了支持B+和LSM的 Wired Tiger引擎。许多关系数据库可以配置索引结构,使用不同的文件格式。
考虑被使用的硬件,昂贵的SSD,像FusionIO有更好的随机写性能,这适合本地更新的策略方法。更便宜的SSD和机械盘则更适合LSM。
Hbase上的LSM(LSM核心原理)
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
以上就是LSM树最本质的原理,有了原理,再看具体的技术就很简单了。
1)首先说说为什么要有WAL(Write Ahead Log),很简单,因为数据是先写到内存中,如果断电,内存中的数据会丢失,因此为了保护内存中的数据,需要在磁盘上先记录logfile,当内存中的数据flush到磁盘上时,就可以抛弃相应的Logfile。
2)什么是memstore, storefile?很简单,上面说过,LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile。
3)为什么会有compact?很简单,随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树。
延伸阅读
- There is a nice introductory post here.
- The LSM description in this paper is great and it also discusses interesting extensions.
- These three posts provide a holistic coverage of the algorithm: here, here and here.
- The original Log Structured Merge Tree paper here. It is a little hard to follow in my opinion.
- The Big Table paper here is excellent.
- LSM vs Fractal Trees on High Scalability.
- Recent work on Diff-Index which builds on the LSM concept.
- Jay on SSDs and the benefits of LSM