
今天是一个案例应用,采用东北三省地图进行离散颜色映射,让大家感受下R语言在地理信息空间可视化方面的强大功能,同时也会对之前强调过的地图配色技巧进行应用。
加载工具包:
library(ggplot2) ###绘图函数
library(plyr) ###数据合并工具
library(maptools) ###地图素材导入
library(sp)
library(Cairo) #图片高清导出
library(RColorBrewer) ###有一些高质量的地图配色模板可以参考
数据导入、转换、合并、提取
CHN_adm2 <- readShapePoly("c:/rstudy/CHN_adm/CHN_adm2.shp") #中国地理信息数据
CHN_adm2_1 <- fortify(CHN_adm2) #转化为数据框
data1 <- CHN_adm2@data #提取行政区划信息
data2 <- data.frame(id=row.names(data1),data1)
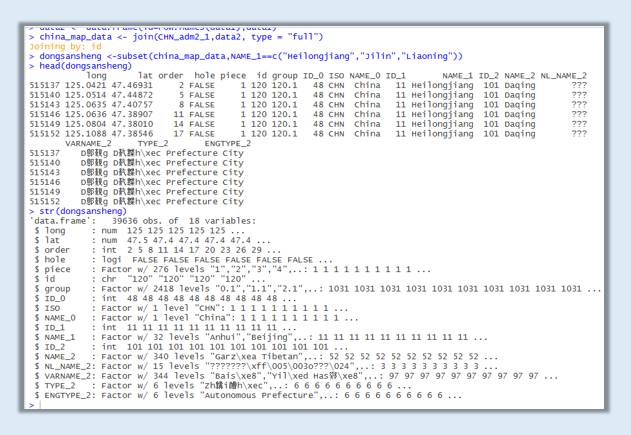
china_map_data <- join(CHN_adm2_1,data2, type = "full") #合并地理信息数据与经纬度数据
dongsansheng <-subset(china_map_data,NAME_1==c("Heilongjiang","Jilin","Liaoning")) #抽取东北三省的合并数据信息
到这里你可以查看一下东三省的市级行政单位详细信息:
aaa<-data.frame(name=unique(dongsansheng$NAME_2))
aaa

以上已经完成了东北三省的数据提取与整理工作,但是如果要使用自己的数据对各个市级行政进行填充,我们还需要自己制作一个业务数据文件文件,以前我都是将上一步的市级行政单位信息复制黏贴到excel表格中,然后建立业务数据,但是突然发现使用write导出函数可以很容易的将行政单位导出成csv格式数据,而且还避免手动黏贴造成的格式错误:
#同上,将市级行政单位提取出来,并附带建立一个指标变量。
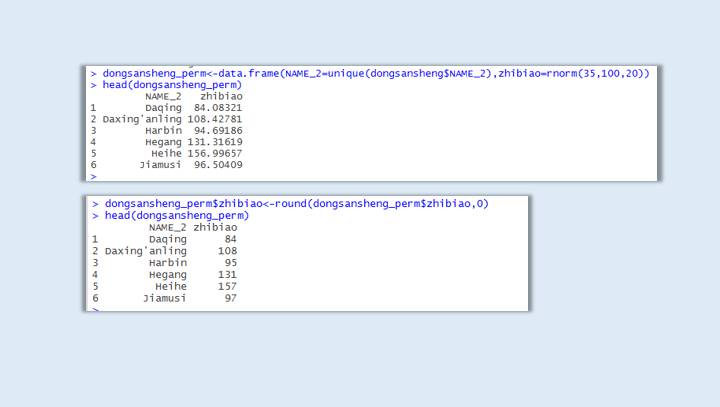
dongsansheng_perm<-data.frame(NAME_2=unique(dongsansheng$NAME_2),zhibiao=rnorm(35,100,20))
#将指标变量保留整数
dongsansheng_perm$zhibiao<-round(dongsansheng_perm$zhibiao,0)
#使用write函数将东三省的行政单位信息导出到数据文件目录下,并取名dongsansheng
write.table (dongsansheng_perm, file ="C:/rstudy/dongsansheng.csv", sep =",", row.names =FALSE)
如果你需要最后显示各市中文名称的话,可以自己将各市中文名称添加到行政信息文件中,然后将指标列数据更换成自己的真实业务指标。当然如果想要直接使用拼音的话就不必添加中文名。
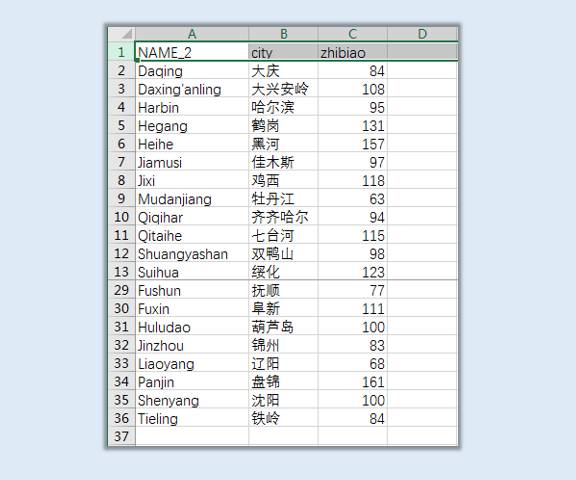
#使用read.csv函数将刚才整理好的带有业务数据的文件再次导入:
mydata<-read.csv("C:/rstudy/dongsansheng.csv",header=T)
#将业务数据与地理信息数据再次合并
dongsansheng_map_data <- join(dongsansheng,mydata, type="full")
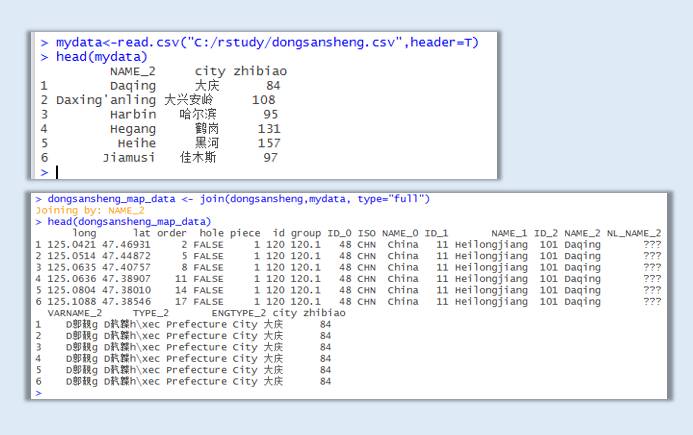
至此,制作地图的信息已经全部整理完毕,接下来要正式开始进行填充填充:
对于连续渐变填充的方法,之前已经有多篇推送进行介绍,这里还是给出代码,便于大家对不同的方法做出来的效果进行比较:
ggplot(dongsansheng_map_data, aes(x = long, y = lat, group = group,fill=zhibiao)) +
geom_polygon(colour="grey40") +
scale_fill_gradient(low="white",high="steelblue") +
coord_map("polyconic") +
theme(
panel.grid = element_blank(),
panel.background = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank()
)
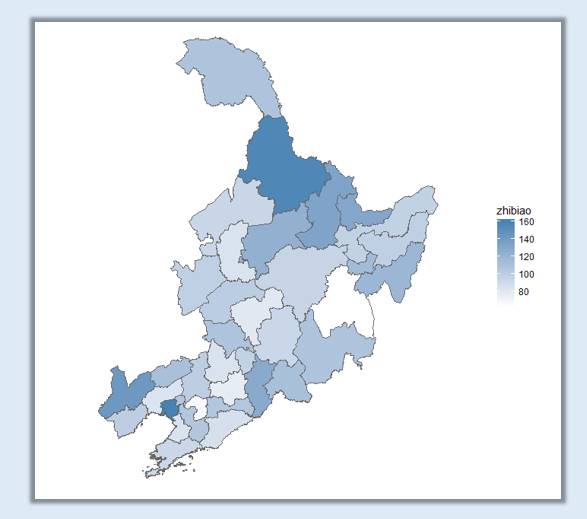
不要以为到这里就完事儿啦,精彩的好戏还在后头呢!
虽然我们使用连续渐变映射做出来了东三省的数据地图,可以如果我问你你能明确的告诉我某一个市的数值范围具体在那个数量段,你可以立马的告诉我吗,反正我是不能。
连续渐变只能给读者一个大小顺序上的感官印象,我们的依靠肉眼很难辨别出某一个地区的指标所处的数量段,这是连续渐变填充情况下的最大弊端:
经过一段时间的摸索,我终于找到了好的解决办法:下面就是通过数值分割的离散填充技巧具体步骤:
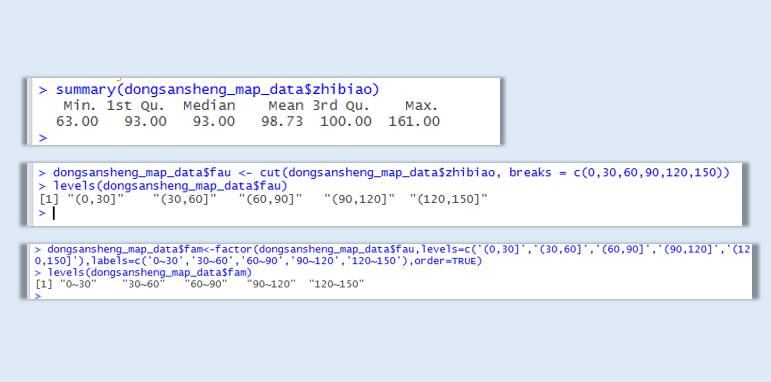
首先要了解自己的业务指标具体分布情况:
summary(dongsansheng_map_data$zhibiao)
Min. 1st Qu. Median Mean 3rd Qu. Max.
63.00 93.00 93.00 98.73 100.00 161.00
计划将该指标在0~200之间均分为5份:
dongsansheng_map_data$fau <- cut(dongsansheng_map_data$zhibiao, breaks = c(0,40,80,120,160,200))
levels(dongsansheng_map_data$fau)
[1] "(0,40]" "(40,80]" "(80,120]" "(120,160]" "(160,200]"
以上通过查看因子水平,我们得到了分割后的因子变量情况,但是直接将该因子变量作为离散颜色边度填充依据的话,那么图例中的因子变成就会默认使用(0,40]……很不美观,所以我们需要对各段因子变量进行重新命名:
dongsansheng_map_data$fam<-factor(dongsansheng_map_data$fau,levels=c('(0,40]','(40,80]','(80,120]','(120,160]','(160,200]'),labels=c('040','4080','80120','120160','160~200'),order=TRUE)
levels(dongsansheng_map_data$fam)
[1] "040" "4080" "80120" "120160" "160~200"
这样的分段更加符合我们的认知,看起来也更加的协调。
接下来就是离散颜色标度的填充:
windowsFonts(myFont = windowsFont("微软雅黑")) #首先定义字体,如果你特别追求字体细节的话
填充函数:
ggplot(dongsansheng_map_data, aes(x = long, y = lat, group = group,fill =fam)) +
geom_polygon(colour="white")+
scale_fill_brewer(palette="Greens") + ###Blues&Greens
coord_map("polyconic") +
ggtitle("某公司2015~2016年度营业状况分布图")+
guides(fill=guide_legend(reverse=TRUE,title=NULL))+
theme(
title=element_text(family="myFont"),
legend.text.align=1, ###图例标签右对齐
panel.grid = element_blank(),
panel.background = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank(),
legend.position = c(0.08,0.6)
)
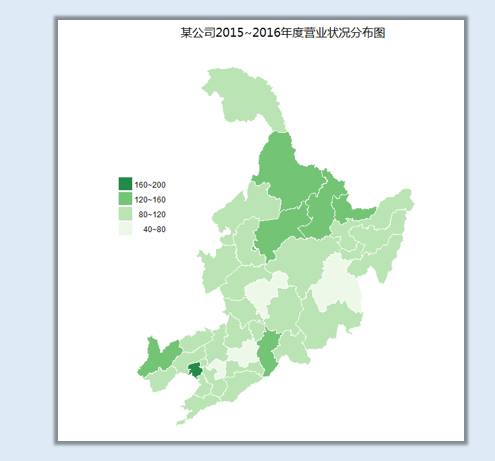
这里因为指标全部是正值,且分割后的因子变量是有序因子变量,我用了RColorBrewer包中的单色调离散颜色方案。
其中Blues也是一个很好的选择:
ggplot(dongsansheng_map_data, aes(x = long, y = lat, group = group,fill =fam)) +
geom_polygon(colour="white")+
scale_fill_brewer(palette="Blues") + ###Blues&Greens
coord_map("polyconic") +
ggtitle("某公司2015~2016年度营业状况分布图")+
guides(fill=guide_legend(reverse=TRUE,title=NULL))+
theme(
title=element_text(family="myFont"),
legend.text.align=1, ###图例标签右对齐
panel.grid = element_blank(),
panel.background = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank(),
legend.position = c(0.08,0.6)
)
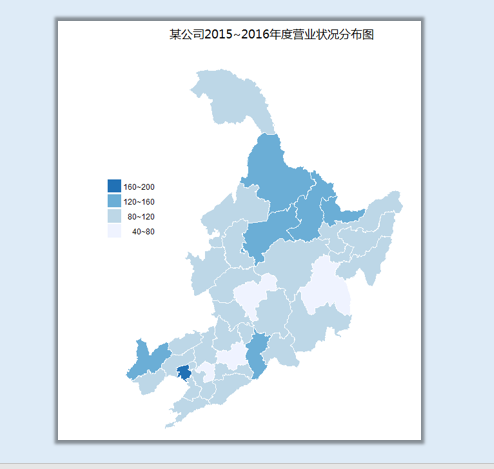
这个包的配色方案中还有很多非常漂亮的颜色,大家可以依次尝试。
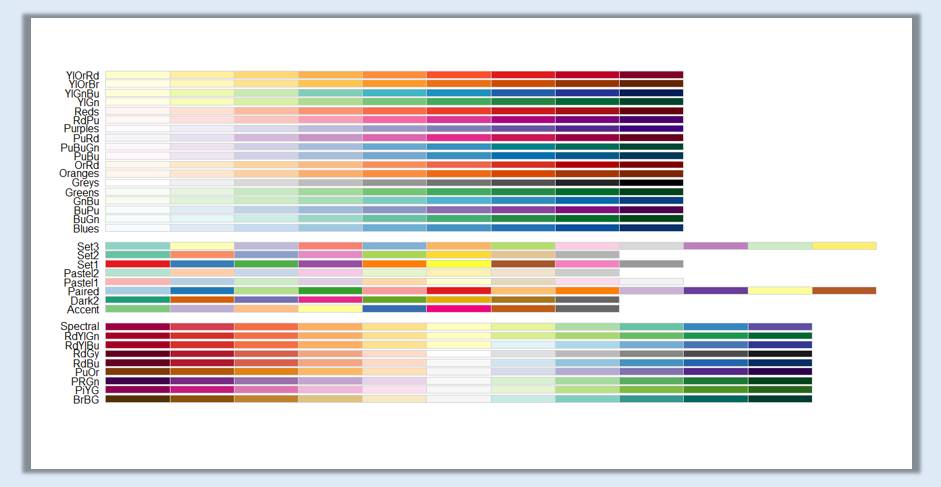
接下来我们来处理各省份的标签问题:
这里有一个很棘手的问题,因为要想给各个城市设置标签,我们必须知道各个城市详细的经纬度数据,而我们的数据集中有的经纬度数据是各城市的轮廓线数据,并没有各城市(城市中心)精确的经纬度数据,所以这里只能勉为其难的取各个城市区域的中心位置作为添加标签的依据(哪位小伙伴儿如果能够获取详细的城市中心经纬度数据,可以共享一下,虽然也可以一个一个的通过百度地图查找当时毕竟效率低)。
获取各个城市区域中心经纬度坐标:
midpos <- function(data1) mean(range(data1,na.rm=TRUE))
centres <- ddply(dongsansheng_map_data,.(city),colwise(midpos,.(long,lat)))
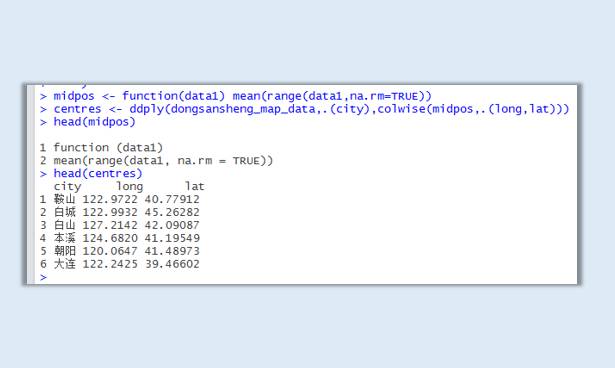
接下来就添加标签:
ggplot(dongsansheng_map_data,aes(long,lat)) +
geom_polygon(aes(group=group,fill=fam),colour="white") +
scale_fill_brewer(palette="Greens") + ###Blues&Greens
geom_text(aes(label=city),size =3,family="myFont",fontface="plain",data=centres) +
ggtitle("某公司2015~2016年度营业状况分布图")+
guides(fill=guide_legend(reverse=TRUE,title=NULL))+
theme(
title=element_text(family="myFont"),
panel.grid = element_blank(),
legend.text.align=1,
panel.background = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank(),
legend.position = c(0.08,0.6)
)
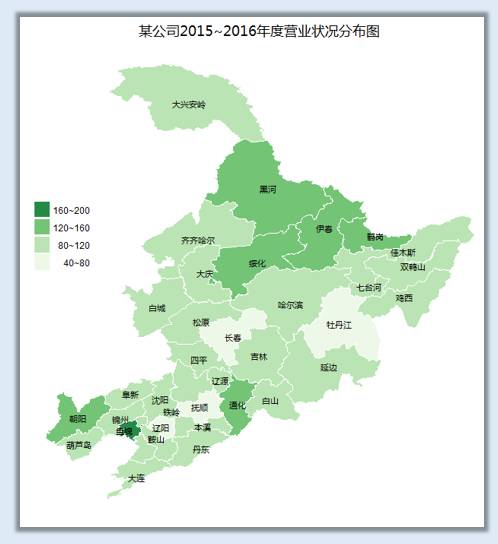
到此,整个数据地图填充完毕,今天这篇主要针对离散标度颜色填充进行,还有一类离散颜色标度填充方式是将具体的数值转化成百分比数量段进行填充,作为该篇的续集下次再讲,代码文件和数据将会分享在魔方学院QQ群里供群友下载。
文件及代码分享在QQ群共享中:
魔方学院QQ群:
QQ群:
微信群:

本文分享自微信公众号 - 数据小魔方(datamofang)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











